






1. 简 介
扩散模型(Diffusion Model)的起源可以追溯到概率图模型和统计物理学领域。它最初的灵感来自于对热扩散和布朗运动等物理现象的研究,这些过程描述了系统如何从一个高能量、不均匀的状态(如高温区)逐步过渡到一个低能量、平衡的状态(如均匀温度分布),后来被引入机器学习和生成模型领域。
扩散模型的早期形式可以追溯到多种研究工作,Sohl-Dickstein 等人(2015年) 在论文《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》中首次将扩散过程引入深度生成模型的框架,奠定了扩散模型的理论基础。
近年来,扩散模型得到了快速发展。尤其是 Ho 等人(2020年)在论文《Denoising Diffusion Probabilistic Models (DDPM)》中提出了一种高效的扩散模型框架,这一工作开辟了扩散模型的新方向,使其在图像生成、语音合成和其他生成任务中表现优异。DDPM 将扩散过程分为两个阶段,一是前向过程(Forward Process), 向数据中逐步添加噪声,直到数据接近高斯分布。二是反向过程(Reverse Process),学习逐步去噪,最终从随机噪声中生成目标数据。如下图所示,随机噪声经过去噪模块1000次去噪之后,生成了一个猫的图像。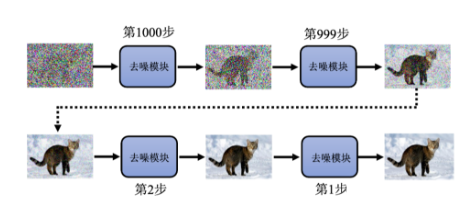
就像是米开朗基罗说的:“塑像就在石头里,我只是把不需要的部分去掉”。
2. 原 理
2.1 前向过程
前向过程也就是我们常说的扩散过程,它模拟真实数据逐渐被噪声污染的过程。其做法通常是从高斯分布里面采样一组噪声添加到正常的图片当中,产生有点噪声的图像,然后从高斯分布中再采样一次,再得到更加噪声的图片,以此类推,最后整张图片就看不出来原来是什么东西,也就是整张图片变成了一个接近高斯分布的噪声。做完这个扩散过程以后,就有去噪模块的训练数据了。
前向过程是一个固定的、不可学习的马尔可夫链。从初始数据分布 开始,逐步向数据中添加高斯噪声,使数据分布逐渐接近标准高斯分布 。公式表示为:
其中 是当前时间步的数据, 是前一时间步的数据, 是一个预定义的时间步长参数,表示每一步添加噪声的强度。 是单位矩阵,表示每个数据维度上的噪声是独立且均匀的。 是高斯分布,表示 的条件分布。
添加噪声的过程是一个马尔可夫链,在每一步中,数据根据高斯分布从 生成 ,噪声的均值为 ,方差为 。前向过程将原始数据逐渐加噪,最终在 步后,使其分布接近标准高斯分布 。
2.2 反向过程
反向过程的目的学习如何从完全随机的噪声逐步还原出目标数据。反向过程是需要通过神经网络来学习的,该网络的输入是一张有噪声的图,输出是一张滤掉一点噪声的图像,去噪越做越多,最终就能看到一张清晰的图片。如下图所示
通常,这个去噪的模型里面实际上是一个噪声预测器(noise predictor),它会预测图片里面的噪声。这个噪声预测器的输入是去噪的图片和噪声现在的严重程度(也就是我们现在进行到去噪的第几个步骤的代号),如下图所示。它预测在这张图片里面噪声应该长什么样子,再在去噪的图片中减去它预测的噪声,就产生去噪以后的结果,即输出一张噪声少了一点的图。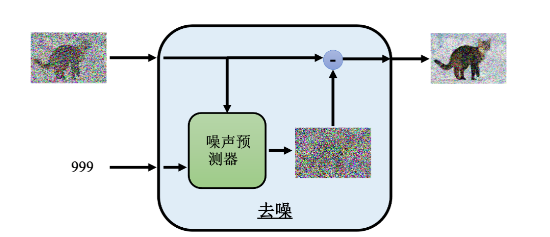
要训练这样的噪声预测器,要用到之前我们在扩散过程中产生的训练数据。即,扩散过程中产生的一张加完噪声的图片跟现在是第几次加噪声,是网络的输入,而加入的这个噪声就是网络应该要预测的输出。比如,噪声预测器的输入是一张加了第2次噪声的猫的图像以及 2 这个数字,接下来的输出应该是第2步加的噪声,如下图所示: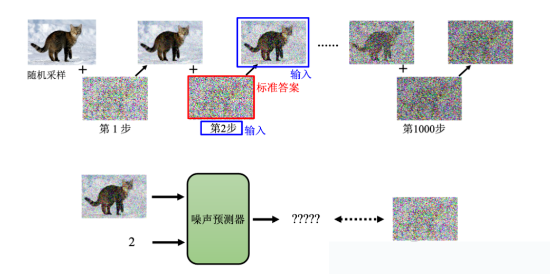
但有些时候我们不仅想要产生图片,还想产生与我们文字描述一样的图片,对于这样的情况,我们只需要在训练数据中增加对图片的描述,同时在去噪的每一个步骤中让噪声预测器多一个额外的输入,也就是描述的这段文字,如下图所示: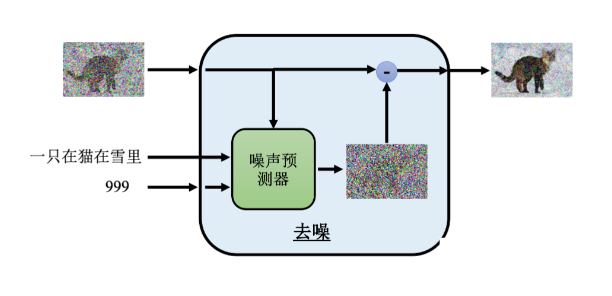
反向过程假设数据的逆演化仍然是一个马尔可夫过程,模型需要学习如何从 预测 ,逐步还原出无噪声的原始数据:
其中 是当前时间步的带噪声数据, 是目标时间步的数据(去噪后)。 是由神经网络预测的均值。 是由神经网络预测的方差(通常固定为常数以简化计算)。通过训练神经网络,使其能够预测每一步中的噪声成分。
扩散模型的训练目标是通过最大化似然估计来优化反向过程。训练过程等价于一个降噪任务,模型学习在给定加噪数据 的情况下,如何估计当前时间步的噪声,扩散模型的训练损失函数如下:
其中 是前向过程中实际添加的噪声, 是模型预测的噪声。 是当前时间步的损失,表示实际噪声与预测噪声之间的均方误差。通过最小化这个损失,模型学习如何在每一步准确预测噪声,从而能够反向还原数据。
如果你还想学习更多的AI大模型知识,这里我也贴心的为大家准备了一份学习资料。无偿分享给大家,VX扫描以下二维码即可领取
3. 代 码
下面我们以生成动漫人脸图像为目标来训练Diffusion Model
动漫人脸数据集下载链接:
https://www.kaggle.com/datasets/b07202024/diffusion/download?datasetVersionNumber=1
本代码遵循典型的 DDPM(Denoising Diffusion Probabilistic Model)框架,整体分为 U-Net 模型(用于去噪)、GaussianDiffusion 类(提供前向扩散和反向采样逻辑)以及数据集和训练器等部分。U-Net 负责在不同尺度下对图像特征进行编码与解码,以预测在每个时间步中加入的噪声;GaussianDiffusion 封装了核心公式与超参数,包括 beta 调度、采样/训练流程及损失函数;Trainer 则管理训练过程,如数据加载、梯度累积、EMA(指数移动平均)等。这种架构将“加噪”和“去噪”分离并封装在模型和调度器中,使得训练和推理流程更加清晰易懂,也能方便地进行扩展或替换不同的网络结构与超参数策略。以下是完整代码(引自《李宏毅深度学习》):
import math # 引入数学相关函数和常量
import copy # 提供浅拷贝和深拷贝功能
from pathlib import Path # 方便进行路径操作
from random import random # 随机数生成函数
from functools import partial # 可用于对函数进行部分参数绑定
from collections import namedtuple # 提供类似结构体的命名元组
from multiprocessing import cpu_count # 获取当前机器的 CPU 核心数
import torch # 引入 PyTorch 库
from torch import nn, einsum # nn 用于神经网络相关模块,einsum 可进行爱因斯坦求和
import torch.nn.functional as F # 提供常用函数式神经网络操作
from torch.utils.data import Dataset, DataLoader # 数据集基类和数据加载器
from torch.optim import Adam # Adam 优化器
import torchvision # PyTorch 视觉工具包
from torchvision import transforms as T, utils # 图像预处理 transforms,utils 提供图像显示保存等功能
from einops import rearrange, reduce, repeat # einops 提供灵活的张量变换函数
from einops.layers.torch import Rearrange # einops 在 PyTorch 中的 Layer 实现
from PIL import Image # Python Image Library,用于图像读写等操作
from tqdm.auto import tqdm # 进度条库,auto 会根据环境自动选择合适的进度条
from ema_pytorch import EMA # 指数滑动平均库,用于模型权重的 EMA
# (Exponential Moving Average)
from accelerate import Accelerator # 用于分布式训练加速的库
import matplotlib.pyplot as plt # 常用的绘图库
import os # 与操作系统相关的功能
# 设置 cuDNN 的自动优化为 True,可以在某些情况下提升卷积运算速度
torch.backends.cudnn.benchmark = True
# 设置随机数种子,保证可重复性
torch.manual_seed(4096)
# 如果有 GPU 可用,则为 GPU 设置相同的随机数种子
if torch.cuda.is_available():
torch.cuda.manual_seed(4096)
def linear_beta_schedule(timesteps):
"""
linear schedule, proposed in original ddpm paper
线性 Beta 时间调度函数,用于扩散模型(DDPM)中定义 Beta 参数在每个时间步的取值。
"""
scale = 1000 / timesteps # 用 timesteps 对原始范围进行缩放
beta_start = scale * 0.0001 # 线性 Beta 的起始值
beta_end = scale * 0.02 # 线性 Beta 的结束值
return torch.linspace(beta_start, beta_end, timesteps, dtype = torch.float64)
# 在 [beta_start, beta_end] 范围上,生成 timesteps 个等差数列。
def extract(a, t, x_shape):
"""
从向量 a 中取出与时间步 t 对应的值,并 reshape 成 x_shape 的形状。
"""
b, *_ = t.shape # 获取 batch 大小 b,忽略后面维度
out = a.gather(-1, t) # 在最后一维上按照索引 t 收集元素
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
# reshape 成 (b, 1, 1, ..., 1) 的形式,以便后续进行广播操作
class Dataset(Dataset):
"""
自定义数据集,用于加载指定文件夹下的 .jpg 图像文件。
"""
def __init__(
self,
folder, # 图像文件所在的文件夹路径
image_size # 需要 resize 到的图像尺寸
):
self.folder = folder # 保存文件夹路径
self.image_size = image_size # 保存图像尺寸
self.paths = [p for p in Path(f'{folder}').glob(f'**/*.jpg')]
# 递归搜索 folder 目录下的所有 .jpg 文件,并将路径保存到 self.paths 列表中
#################################
## TODO: Data Augmentation ##
#################################
self.transform = T.Compose([
T.Resize(image_size), # 调整图像大小到 image_size x image_size
T.ToTensor() # 将图像转换为 PyTorch 张量,并将像素值归一化到 [0,1]
])
def __len__(self):
# 返回数据集的大小(图像的数量)
return len(self.paths)
def __getitem__(self, index):
# 根据索引返回对应的图像数据
path = self.paths[index] # 获取图像路径
img = Image.open(path) # 打开图像
return self.transform(img) # 应用预处理并返回
def exists(x):
return x is not None
# 如果 x 不是 None,则返回 True,否则返回 False
def default(val, d):
if exists(val):
return val
return d() if callable(d) else d
# 如果 val 存在,则返回 val;否则,如果 d 可调用,则返回 d(),否则返回 d
# 这个函数通常用于参数的默认值设置
def identity(t, *args, **kwargs):
return t
# 一个简单的恒等函数,原样返回输入 t,本质上不对数据做任何处理
def cycle(dl):
while True:
for data in dl:
yield data
# 这是一个生成器,循环迭代给定的 dataloader (dl),使其可无限次迭代
def has_int_squareroot(num):
return (math.sqrt(num) ** 2) == num
# 判断 num 的平方根是否为整数
# math.sqrt(num) ** 2 如果等于 num,则 num 的平方根是整数
def num_to_groups(num, divisor):
groups = num // divisor
remainder = num % divisor
arr = [divisor] * groups
if remainder > 0:
arr.append(remainder)
return arr
# 将 num 拆分成大小为 divisor 的若干组,最后如果有余数 remainder,则将它作为一组附加到数组的末尾
# 举例:num=10, divisor=3,则返回 [3, 3, 4]
# normalization functions
def normalize_to_neg_one_to_one(img):
return img * 2 - 1
# 将图像像素值 [0, 1] 的范围映射到 [-1, 1]
def unnormalize_to_zero_to_one(t):
return (t + 1) * 0.5
# 将图像像素值 [-1, 1] 的范围映射回 [0, 1]
# small helper modules
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
# 初始化时传入一个 nn.Module,然后在 forward 中进行残差连接
def forward(self, x, *args, **kwargs):
return self.fn(x, *args, **kwargs) + x
# 前向传播时,将输入 x 经过 self.fn,再加回原始 x 实现残差结构
def Upsample(dim, dim_out = None):
return nn.Sequential(
nn.Upsample(scale_factor = 2, mode = 'nearest'),
nn.Conv2d(dim, default(dim_out, dim), 3, padding = 1)
)
# 上采样模块:
# 1) 将特征图放大 2 倍(最近邻插值)
# 2) 卷积将通道数从 dim 映射到 dim_out(如果 dim_out 没传,则仍为 dim)
def Downsample(dim, dim_out = None):
return nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (c p1 p2) h w', p1 = 2, p2 = 2),
nn.Conv2d(dim * 4, default(dim_out, dim), 1)
)
# 下采样模块:
# 1) 通过 einops 将高宽各自分辨率乘以 2 的模式展平到通道维度上(相当于像素重排)
# 使得通道数扩大 4 倍 (p1=2, p2=2 => 2*2=4)
# 2) 1x1 卷积将通道数映射到 dim_out(默认保持不变)
class WeightStandardizedConv2d(nn.Conv2d):
"""
https://arxiv.org/abs/1903.10520
weight standardization purportedly works synergistically with group normalization
"""
def forward(self, x):
eps = 1e-5 if x.dtype == torch.float32 else 1e-3
# 根据数据类型选择不同的数值稳定性常数 eps
weight = self.weight
mean = reduce(weight, 'o ... -> o 1 1 1', 'mean')
var = reduce(weight, 'o ... -> o 1 1 1', partial(torch.var, unbiased = False))
# 计算卷积核在输出通道维度 o 上的均值 mean 和方差 var
normalized_weight = (weight - mean) * (var + eps).rsqrt()
# 对卷积核进行标准化
return F.conv2d(x, normalized_weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
# 使用标准化后的卷积核进行卷积操作
class LayerNorm(nn.Module):
def __init__(self, dim):
super().__init__()
self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
# 可学习的缩放参数 g,初始化为 1
def forward(self, x):
eps = 1e-5 if x.dtype == torch.float32 else 1e-3
var = torch.var(x, dim = 1, unbiased = False, keepdim = True)
mean = torch.mean(x, dim = 1, keepdim = True)
return (x - mean) * (var + eps).rsqrt() * self.g
# 沿着通道维度(=1)做 layer norm,并使用 g 来进行缩放
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = LayerNorm(dim)
# 在执行 fn 之前,先进行 LayerNorm
def forward(self, x):
x = self.norm(x)
return self.fn(x)
# 前向过程:先归一化,再执行传入的 fn
# sinusoidal positional embeds
class SinusoidalPosEmb(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
# 记录嵌入维度
def forward(self, x):
device = x.device
half_dim = self.dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
# 生成等比数列,以用于构建正余弦频率
emb = x[:, None] * emb[None, :]
# 将输入时间步 x 与频率 emb 相乘
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
# 拼接正弦和余弦部分
return emb
# 返回正余弦位置编码
class RandomOrLearnedSinusoidalPosEmb(nn.Module):
""" following @crowsonkb 's lead with random (learned optional) sinusoidal pos emb """
""" https://github.com/crowsonkb/v-diffusion-jax/blob/master/diffusion/models/danbooru_128.py#L8 """
def __init__(self, dim, is_random = False):
super().__init__()
assert (dim % 2) == 0
half_dim = dim // 2
self.weights = nn.Parameter(torch.randn(half_dim), requires_grad = not is_random)
# 如果 is_random 为 False,则这些频率是可学习的;否则是随机固定
def forward(self, x):
x = rearrange(x, 'b -> b 1')
# 将输入 x reshape 成 (batch, 1)
freqs = x * rearrange(self.weights, 'd -> 1 d') * 2 * math.pi
# 计算随机或可学习的频率 freqs
fouriered = torch.cat((freqs.sin(), freqs.cos()), dim = -1)
# 拼接正弦和余弦
fouriered = torch.cat((x, fouriered), dim = -1)
# 再将原始 x 与正余弦部分合并
return fouriered
# 返回包含输入和正余弦编码的结果
# building block modules
class Block(nn.Module):
def __init__(self, dim, dim_out, groups = 8):
super().__init__()
self.proj = WeightStandardizedConv2d(dim, dim_out, 3, padding = 1)
self.norm = nn.GroupNorm(groups, dim_out)
self.act = nn.SiLU()
# 一个卷积 -> GroupNorm -> SiLU 激活的基本模块
# 卷积使用 WeightStandardizedConv2d,便于搭配 GroupNorm
def forward(self, x, scale_shift = None):
x = self.proj(x)
x = self.norm(x)
if exists(scale_shift):
scale, shift = scale_shift
x = x * (scale + 1) + shift
# 如果从时间嵌入得到 scale_shift,则对特征图进行缩放和偏移
x = self.act(x)
return x
# 输出经过标准化和激活的张量
class ResnetBlock(nn.Module):
def __init__(self, dim, dim_out, *, time_emb_dim = None, groups = 8):
super().__init__()
# 如果传入了 time_emb_dim,则对时间嵌入进行线性映射得到 scale 和 shift
self.mlp = nn.Sequential(
nn.SiLU(),
nn.Linear(time_emb_dim, dim_out * 2)
) if exists(time_emb_dim) else None
self.block1 = Block(dim, dim_out, groups = groups)
self.block2 = Block(dim_out, dim_out, groups = groups)
self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
# 如果 dim != dim_out,就用 1x1 卷积在残差分支中对通道数进行调整
def forward(self, x, time_emb = None):
scale_shift = None
if exists(self.mlp) and exists(time_emb):
time_emb = self.mlp(time_emb)
time_emb = rearrange(time_emb, 'b c -> b c 1 1')
scale_shift = time_emb.chunk(2, dim = 1)
# 将 time_emb 拆分为 (scale, shift)
h = self.block1(x, scale_shift = scale_shift)
h = self.block2(h)
return h + self.res_conv(x)
# 最终输出为正常流 (h) + 残差分支
class LinearAttention(nn.Module):
def __init__(self, dim, heads = 4, dim_head = 32):
super().__init__()
self.scale = dim_head ** -0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False)
# 一次性生成 q, k, v
self.to_out = nn.Sequential(
nn.Conv2d(hidden_dim, dim, 1),
LayerNorm(dim)
)
# 输出层(卷积 + LayerNorm)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim = 1)
# 将通道维分成 q, k, v
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> b h c (x y)', h = self.heads), qkv)
q = q.softmax(dim = -2)
k = k.softmax(dim = -1)
# 分别对 q 的通道维(-2)和 k 的序列维(-1)做 softmax
q = q * self.scale
v = v / (h * w)
# 缩放 q,以及对 v 做归一化
context = torch.einsum('b h d n, b h e n -> b h d e', k, v)
# 先将 k 和 v 做乘积,得到上下文 context
out = torch.einsum('b h d e, b h d n -> b h e n', context, q)
# 再和 q 做乘积以得到输出
out = rearrange(out, 'b h c (x y) -> b (h c) x y', h = self.heads, x = h, y = w)
# reshape 回原始形状
return self.to_out(out)
# 卷积 + LayerNorm 得到最终结果
class Attention(nn.Module):
def __init__(self, dim, heads = 4, dim_head = 32):
super().__init__()
self.scale = dim_head ** -0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False)
self.to_out = nn.Conv2d(hidden_dim, dim, 1)
# 自注意力机制:先获取 q, k, v,再做注意力加权求和,最后映射回 dim
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim = 1)
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> b h c (x y)', h = self.heads), qkv)
q = q * self.scale
# 缩放 q
sim = torch.einsum('b h d i, b h d j -> b h i j', q, k)
# 相似度矩阵 sim (b, heads, i, j)
attn = sim.softmax(dim = -1)
# 沿着最后一维做 softmax,得到注意力分布
out = torch.einsum('b h i j, b h d j -> b h i d', attn, v)
# 加权求和得到输出
out = rearrange(out, 'b h (x y) d -> b (h d) x y', x = h, y = w)
# reshape 回原始分辨率
return self.to_out(out)
# 最后再用 1x1 卷积映射回 dim 维度
# model
class Unet(nn.Module):
def __init__(
self,
dim,
init_dim = None,
out_dim = None,
dim_mults=(1, 2, 4, 8),
channels = 3,
resnet_block_groups = 8,
learned_sinusoidal_cond = False,
random_fourier_features = False,
learned_sinusoidal_dim = 16
):
super().__init__()
# determine dimensions
self.channels = channels
init_dim = default(init_dim, dim)
self.init_conv = nn.Conv2d(channels, init_dim, 7, padding = 3)
# 输入通道 -> init_dim, 使用 7x7 卷积做初始特征提取
dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:]))
# 比如 dim=64, dim_mults=(1,2,4,8), 则 dims=[64, 64*1, 64*2, 64*4, 64*8]
# in_out 就是 [(64,64),(64,128),(128,256),(256,512)]
block_klass = partial(ResnetBlock, groups = resnet_block_groups)
# 使用部分函数 partial,将 ResnetBlock 的 groups 参数固定
# time embeddings
time_dim = dim * 4
# 时间嵌入的维度,一般设置为 4 倍 base dim
self.random_or_learned_sinusoidal_cond = learned_sinusoidal_cond or random_fourier_features
if self.random_or_learned_sinusoidal_cond:
sinu_pos_emb = RandomOrLearnedSinusoidalPosEmb(learned_sinusoidal_dim, random_fourier_features)
fourier_dim = learned_sinusoidal_dim + 1
else:
sinu_pos_emb = SinusoidalPosEmb(dim)
fourier_dim = dim
# 根据需要选择使用随机/可学习的正弦嵌入,或使用经典的正弦嵌入
self.time_mlp = nn.Sequential(
sinu_pos_emb,
nn.Linear(fourier_dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim)
)
# 时间嵌入先经过正弦嵌入,然后用两个全连接层(中间激活为 GELU),维度转为 time_dim
# layers
self.downs = nn.ModuleList([])
self.ups = nn.ModuleList([])
num_resolutions = len(in_out)
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1)
# 判断是否是最后一个分辨率
self.downs.append(nn.ModuleList([
block_klass(dim_in, dim_in, time_emb_dim = time_dim),
block_klass(dim_in, dim_in, time_emb_dim = time_dim),
Residual(PreNorm(dim_in, LinearAttention(dim_in))),
Downsample(dim_in, dim_out) if not is_last else nn.Conv2d(dim_in, dim_out, 3, padding = 1)
]))
# down 阶段:
# 1) ResnetBlock(dim_in -> dim_in)
# 2) 再一个 ResnetBlock(dim_in -> dim_in)
# 3) Residual(PreNorm(LinearAttention))
# 4) 如果不是最后层,用 Downsample;否则用 3x3 卷积保持分辨率
mid_dim = dims[-1]
self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim = time_dim)
self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))
self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim = time_dim)
# 中间层(U-Net 最底部):ResnetBlock -> 自注意力 -> ResnetBlock
for ind, (dim_in, dim_out) in enumerate(reversed(in_out)):
is_last = ind == (len(in_out) - 1)
# 倒序遍历 in_out,用于 up 阶段
self.ups.append(nn.ModuleList([
block_klass(dim_out + dim_in, dim_out, time_emb_dim = time_dim),
block_klass(dim_out + dim_in, dim_out, time_emb_dim = time_dim),
Residual(PreNorm(dim_out, LinearAttention(dim_out))),
Upsample(dim_out, dim_in) if not is_last else nn.Conv2d(dim_out, dim_in, 3, padding = 1)
]))
# up 阶段的逻辑与 down 类似,只是要先拼接 skip connection
self.out_dim = default(out_dim, channels)
# 最终输出通道数,默认与输入通道一致
self.final_res_block = block_klass(dim * 2, dim, time_emb_dim = time_dim)
# 最后一步和初始输入拼接后,再过一个 ResnetBlock
self.final_conv = nn.Conv2d(dim, self.out_dim, 1)
# 通过 1x1 卷积将维度映射到 out_dim
def forward(self, x, time):
x = self.init_conv(x)
# 初始卷积提取特征
r = x.clone()
# 保存初始特征用于最后拼接
t = self.time_mlp(time)
# 将时间步 time 通过 time_mlp 得到时间嵌入 t
h = []
# 用于保存每层的输出,以便在解码器阶段做 skip connection
# downsample
for block1, block2, attn, downsample in self.downs:
x = block1(x, t)
h.append(x)
x = block2(x, t)
x = attn(x)
h.append(x)
x = downsample(x)
# 依次执行 block1 -> block2 -> attn -> downsample
# 并存储中间输出 h
# mid
x = self.mid_block1(x, t)
x = self.mid_attn(x)
x = self.mid_block2(x, t)
# U-Net 中间层的处理
# upsample
for block1, block2, attn, upsample in self.ups:
# pop 出下采样时存储的输出,进行 skip connection
x = torch.cat((x, h.pop()), dim = 1)
x = block1(x, t)
x = torch.cat((x, h.pop()), dim = 1)
x = block2(x, t)
x = attn(x)
x = upsample(x)
# final
x = torch.cat((x, r), dim = 1)
# 跟最初的输入特征 r 拼接
x = self.final_res_block(x, t)
return self.final_conv(x)
# 最终输出一个跟输入维度相匹配的特征图
model = Unet(64)
# 实例化一个 U-Net 模型,基本通道数 dim = 64
class GaussianDiffusion(nn.Module):
def __init__(
self,
model, # 传入的 U-Net 等模型,用于预测噪声
*,
image_size, # 图像大小(宽和高)
timesteps = 1000, # 扩散过程的总时间步数
beta_schedule = 'linear',# beta 的调度方式;此处仅支持 'linear'
auto_normalize = True # 是否自动将图像 [0,1] 归一化到 [-1,1]
):
super().__init__()
# 继承自 nn.Module
assert not (type(self) == GaussianDiffusion and model.channels != model.out_dim)
# 如果是 GaussianDiffusion 类本身,则要求 model 的输入通道和输出通道一致,否则会出错
assert not model.random_or_learned_sinusoidal_cond
# 在本实现里,不允许网络使用随机或可学习的正弦位置编码
self.model = model
# 保存传入的模型(通常是一个 U-Net)
self.channels = self.model.channels
# 模型的通道数量(图像的通道,默认为 3)
self.image_size = image_size
# 保存图像大小
if beta_schedule == 'linear':
beta_schedule_fn = linear_beta_schedule
else:
raise ValueError(f'unknown beta schedule {beta_schedule}')
# 根据传入的 beta_schedule 字符串选择 beta 调度函数
# 目前只支持 'linear',否则抛出异常
# calculate beta and other precalculated parameters
betas = beta_schedule_fn(timesteps)
# 计算在每个时间步上的 beta 值(线性递增)
alphas = 1. - betas
# α_t = 1 - β_t
alphas_cumprod = torch.cumprod(alphas, dim=0)
# 累乘得到 α_1 * α_2 * ... * α_t
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value = 1.)
# 向前偏移一个时间步,便于在计算 q(x_{t-1}|x_t, x_0) 时使用
# 第一个时间步补 1,使 α_cumprod_prev 的长度与 alphas_cumprod 一致
timesteps, = betas.shape
# 获取时间步数(1000)
self.num_timesteps = int(timesteps)
# 将其保存为整型
# sampling related parameters
self.sampling_timesteps = timesteps
# 采样时使用的步数,默认和训练步数相同
# helper function to register buffer from float64 to float32
register_buffer = lambda name, val: self.register_buffer(name, val.to(torch.float32))
# 定义一个小函数,用于将各种张量注册为 buffer,并转换为 float32 类型
register_buffer('betas', betas)
register_buffer('alphas_cumprod', alphas_cumprod)
register_buffer('alphas_cumprod_prev', alphas_cumprod_prev)
# 将以上计算好的 beta、alpha 累乘、以及前一个时间步的 alpha 累乘注册为 buffer
# 这些值是训练和推理都会用到,但不会被训练的参数
# calculations for diffusion q(x_t | x_{t-1}) and others
register_buffer('sqrt_alphas_cumprod', torch.sqrt(alphas_cumprod))
# sqrt(累乘α_t)
register_buffer('sqrt_one_minus_alphas_cumprod', torch.sqrt(1. - alphas_cumprod))
# sqrt(1 - 累乘α_t)
register_buffer('log_one_minus_alphas_cumprod', torch.log(1. - alphas_cumprod))
# 记录 log(1 - 累乘α_t)
register_buffer('sqrt_recip_alphas_cumprod', torch.sqrt(1. / alphas_cumprod))
# sqrt(1 / 累乘α_t)
register_buffer('sqrt_recipm1_alphas_cumprod', torch.sqrt(1. / alphas_cumprod - 1))
# sqrt(1 / 累乘α_t - 1)
# calculations for posterior q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
# q(x_{t-1} | x_t, x_0) 的后验方差
# 根据公式: posterior_variance_t = β_t * (1 - α_{t-1}累乘) / (1 - α_t累乘)
# above: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t)
register_buffer('posterior_variance', posterior_variance)
# 注册后验方差
# below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
register_buffer('posterior_log_variance_clipped', torch.log(posterior_variance.clamp(min =1e-20)))
# 取对数时夹紧最小值防止数值溢出
register_buffer('posterior_mean_coef1', betas * torch.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod))
# 后验均值系数1
register_buffer('posterior_mean_coef2', (1. - alphas_cumprod_prev) * torch.sqrt(alphas) / (1. - alphas_cumprod))
# 后验均值系数2
# derive loss weight
# snr - signal noise ratio
snr = alphas_cumprod / (1 - alphas_cumprod)
# SNR = α_t累乘 / (1 - α_t累乘)
# https://arxiv.org/abs/2303.09556
maybe_clipped_snr = snr.clone()
# 这里可以对 snr 做一些裁剪操作,如果需要的话
register_buffer('loss_weight', maybe_clipped_snr / snr)
# 用于加权损失的系数
# auto-normalization of data [0, 1] -> [-1, 1] - can turn off by setting it to be False
self.normalize = normalize_to_neg_one_to_one if auto_normalize else identity
self.unnormalize = unnormalize_to_zero_to_one if auto_normalize else identity
# 根据 auto_normalize 决定是否对数据进行 [-1,1] <-> [0,1] 的转换
def predict_start_from_noise(self, x_t, t, noise):
"""
通过 x_t 和噪声,反推 x_0 的预测值
x_0 = 1 / sqrt(alpha_cumprod) * x_t - sqrt(1 / alpha_cumprod - 1) * noise
"""
return (
extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
)
def predict_noise_from_start(self, x_t, t, x0):
"""
通过 x_t 和对 x_0 的预测值,反推噪声的预测值
noise = (1 / sqrt(alpha_cumprod) * x_t - x_0) / sqrt(1 / alpha_cumprod - 1)
"""
return (
(extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t - x0) / \
extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
)
def q_posterior(self, x_start, x_t, t):
"""
计算后验分布 q(x_{t-1} | x_t, x_0) 的均值和方差
"""
posterior_mean = (
extract(self.posterior_mean_coef1, t, x_t.shape) * x_start +
extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
)
# 后验分布的均值
posterior_variance = extract(self.posterior_variance, t, x_t.shape)
# 后验分布的方差
posterior_log_variance_clipped = extract(self.posterior_log_variance_clipped, t, x_t.shape)
# 后验分布方差的对数(已做 clip)
return posterior_mean, posterior_variance, posterior_log_variance_clipped
def model_predictions(self, x, t, clip_x_start = False, rederive_pred_noise = False):
"""
给定当前噪声图 x 和时间步 t,通过模型预测噪声 pred_noise,并得到对 x_0 的估计 x_start
"""
model_output = self.model(x, t)
# 模型输出,通常是预测噪声
maybe_clip = partial(torch.clamp, min = -1., max = 1.) if clip_x_start else identity
# 如果需要对预测出的 x_0 做裁剪,则 partial(torch.clamp);否则恒等函数
pred_noise = model_output
# 这里把模型输出视为噪声预测
x_start = self.predict_start_from_noise(x, t, pred_noise)
x_start = maybe_clip(x_start)
# 对 x_0 进行 [-1,1] 裁剪(可选)
if clip_x_start and rederive_pred_noise:
# 如果 x_0 被裁剪,为了更准确,需要重新计算一次噪声
pred_noise = self.predict_noise_from_start(x, t, x_start)
return pred_noise, x_start
def p_mean_variance(self, x, t, clip_denoised = True):
"""
计算从扩散过程中 p(x_{t-1} | x_t) 的均值和方差,用于反向采样
"""
noise, x_start = self.model_predictions(x, t)
# 模型预测噪声和 x_0
if clip_denoised:
x_start.clamp_(-1., 1.)
# 默认会把 x_0 的范围裁剪到 [-1,1]
model_mean, posterior_variance, posterior_log_variance = self.q_posterior(
x_start = x_start,
x_t = x,
t = t
)
# 计算后验分布的均值和方差
# 这里的后验分布相当于 q(x_{t-1}|x_t, x_0)
return model_mean, posterior_variance, posterior_log_variance, x_start
@torch.no_grad()
def p_sample(self, x, t: int):
"""
在反向扩散的某一个时间步 t,从 p(x_{t-1} | x_t) 采样
"""
b, *_, device = *x.shape, x.device
batched_times = torch.full((b,), t, device = x.device, dtype = torch.long)
# 构造与批大小相同的时间张量
model_mean, _, model_log_variance, x_start = self.p_mean_variance(
x = x,
t = batched_times,
clip_denoised = True
)
# 根据 x_t 计算后验均值和方差
noise = torch.randn_like(x) if t > 0 else 0.
# 如果 t > 0 则在采样时加噪声;如果 t=0,则不再加噪声
pred_img = model_mean + (0.5 * model_log_variance).exp() * noise
# 采样公式: x_{t-1} = 均值 + 标准差 * 噪声
return pred_img, x_start
@torch.no_grad()
def p_sample_loop(self, shape, return_all_timesteps = False):
"""
从纯噪声开始,逐步反向采样还原图像
"""
batch, device = shape[0], self.betas.device
# batch 大小, 使用存储在 buffer 中的 betas 的设备
img = torch.randn(shape, device = device)
# 初始从标准正态分布采样
imgs = [img]
# 用于保存采样过程中每个时间步的结果
x_start = None
###########################################
## TODO: plot the sampling process ##
###########################################
for t in tqdm(reversed(range(0, self.num_timesteps)), desc = 'sampling loop time step', total = self.num_timesteps):
# 从 T-1 到 0 逐步反向采样
img, x_start = self.p_sample(img, t)
imgs.append(img)
ret = img if not return_all_timesteps else torch.stack(imgs, dim = 1)
# 如果 return_all_timesteps=True, 返回整个采样序列;否则只返回最终生成的图像
ret = self.unnormalize(ret)
# 将图像从 [-1,1] 转回 [0,1]
return ret
@torch.no_grad()
def sample(self, batch_size = 16, return_all_timesteps = False):
"""
对外提供的采样接口
"""
image_size, channels = self.image_size, self.channels
sample_fn = self.p_sample_loop
# 默认使用 p_sample_loop 进行逐步采样
return sample_fn((batch_size, channels, image_size, image_size), return_all_timesteps = return_all_timesteps)
def q_sample(self, x_start, t, noise=None):
"""
前向扩散:从 x_0 得到 x_t 的采样
x_t = sqrt(α_cumprod) * x_0 + sqrt(1-α_cumprod) * noise
"""
noise = default(noise, lambda: torch.randn_like(x_start))
# 如果不指定噪声,则生成一个和 x_start 形状相同的高斯噪声
return (
extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise
)
@property
def loss_fn(self):
return F.mse_loss
# 训练时使用的损失函数,默认是 MSE
def p_losses(self, x_start, t, noise = None):
"""
在给定 x_0 以及随机的时间步 t 时,计算训练时的损失
"""
b, c, h, w = x_start.shape
noise = default(noise, lambda: torch.randn_like(x_start))
# noise sample
x = self.q_sample(x_start = x_start, t = t, noise = noise)
# 前向扩散,将 x_0 添加噪声到 x_t
# predict and take gradient step
model_out = self.model(x, t)
# 模型对 x_t 进行估计噪声
loss = self.loss_fn(model_out, noise, reduction = 'none')
# 计算 MSE 损失 (逐元素)
loss = reduce(loss, 'b ... -> b (...)', 'mean')
# 在除 batch 之外的所有维度取平均 (即每个样本的损失)
loss = loss * extract(self.loss_weight, t, loss.shape)
# 乘以权重 (与 SNR 相关)
return loss.mean()
# 返回对整个 batch 的平均损失
def forward(self, img, *args, **kwargs):
"""
模块的前向调用接口,一般在训练时调用
"""
b, c, h, w, device, img_size, = *img.shape, img.device, self.image_size
# 解包图像形状、设备以及定义的图像大小
assert h == img_size and w == img_size, f'height and width of image must be {img_size}'
t = torch.randint(0, self.num_timesteps, (b,), device=device).long()
# 随机采样一个时间步 t 用于训练
img = self.normalize(img)
# 如果开启了 auto_normalize,则把 [0,1] 的图片映射到 [-1,1]
return self.p_losses(img, t, *args, **kwargs)
# 调用 p_losses 计算训练损失
path = './faces/faces'
# 数据所在的文件路径,这里假设所有训练图像都在 ./faces/faces 目录中
IMG_SIZE = 64
# 设置图像尺寸为 64x64
batch_size = 16
# 设置训练时的批大小为 16 张图像
train_num_steps = 10000
# 训练的总步数,指优化器更新(iteration)次数
lr = 1e-3
# 学习率 (learning rate),这里设置为 0.001
grad_steps = 1
# 梯度累积步数;若设置大于 1 则表示每累积一定次数的反向传播再进行一次优化更新
ema_decay = 0.995
# 指数移动平均 (EMA) 的衰减率,常用于在训练过程中平滑模型权重
channels = 16
# U-Net 的基础通道数,即第一个卷积层的通道数
dim_mults = (1, 2, 4)
# 用来指定 U-Net 不同下采样 / 上采样阶段的通道扩展倍数,
# 最终网络结构中的通道数将按 (channels, 2*channels, 4*channels, ...) 的形式逐步增加
timesteps = 100
# 扩散过程中加噪声的时间步数 T;比如在 DDPM 中可以是 1000,这里设置为 100
beta_schedule = 'linear'
# beta 的调度方式(表示在扩散过程中 beta 的变化),此处设置为线性
model = Unet(
dim = channels,
dim_mults = dim_mults
)
# 实例化一个 U-Net 模型对象,输入的基本通道数为 16,
# 会根据 dim_mults 逐步在网络层中增加通道数
diffusion = GaussianDiffusion(
model,
image_size = IMG_SIZE,
timesteps = timesteps,
beta_schedule = beta_schedule
)
# 将 U-Net 模型封装到 GaussianDiffusion 类中,
# 并设置扩散过程中的一些参数(如图像大小、时间步数等)。
# 该类会负责前向扩散(加噪)和反向扩散(去噪)的具体实现。
trainer = Trainer(
diffusion,
path,
train_batch_size = batch_size,
train_lr = lr,
train_num_steps = train_num_steps,
gradient_accumulate_every = grad_steps,
ema_decay = ema_decay,
save_and_sample_every = 1000
)
# 实例化一个 Trainer 类来管理训练流程:
# - 使用 diffusion 模型进行前向与反向传播
# - 每个 batch 的大小为 16
# - 使用学习率 1e-3
# - 总训练步数为 10000
# - 每个 step 都更新梯度(grad_steps=1)
# - EMA 衰减因子为 0.995
# - 每 1000 步保存一次模型并进行一次采样
trainer.train()
# 开始训练,Trainer 内部会执行循环读取数据、前向计算、损失反传、优化器更新等流程。
运行环境:
accelerate 1.0.1
einops 0.8.0
ema-pytorch 0.7.7
matplotlib 3.5.1
multiprocess 0.70.15
numpy 1.24.4
python 3.8.19
pytorch 2.4.0
pytorch-cuda 12.1
tqdm 4.66.5
下图为模型在完成训练之后生成的动漫人脸图像:
从该结果可以看出,模型成功地学习到了二次元人脸的整体特征与色彩分布,生成的人像在发型、五官、配色等方面都有一定的多样性,说明扩散模型在此任务中具备一定的泛化能力。不过图像中仍存在一定程度的模糊、面部细节缺失或扭曲等现象,表明训练规模与网络容量可能还需要进一步优化,以获得更精细、更稳定的生成质量。
总结一下,扩散模型(Diffusion Model)通过在前向过程逐步向图像添加噪声、在反向过程逐步去噪的方式实现图像生成,具有相对稳定的训练过程和良好的生成多样性。它在高分辨率图像生成、条件生成(文本、语音、语义分割等)方面表现不错,且与自回归、GAN 等其他生成方法形成互补。未来发展方向包括更高效的采样策略、更灵活的条件控制、多尺度或多模态的融合,以及在更广泛的数据类型(视频、3D 等)上的应用和研究。
如果你还想学习更多的AI大模型知识,这里我也贴心的为大家准备了一份学习资料。无偿分享给大家,VX扫描以下二维码即可领取

















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









