






| DeepSeek原创文章 | |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | Deepseek基座:Deepseek-v3核心内容解析 |
| 6 |
Deepseek目前主要关注两条技术路线:一个是base模型的突破,另一个是模型reasoning的performence。本文会整体把Deepseek的系列论文过一遍,然后highlight一些重要技术。
这一篇文章更多关注于基座模型的发展。

DeepSeek LLM
Deepseek LLM: Scaling Open-Source Language Models with Longtermism
这是DeepSeek 的第一篇大模型工作可以看作是其在大语言模型领域的“横空出世”之作。这篇paper并非以创新为主,而是对 Meta 的 Llama 2 模型的一次高质量复现。当时Llama 2 发布不久,作为初创公司的 DeepSeek 选择从复现入手,是非常合理且务实的选择。 所以它们的目标是验证自身能否成功 reproduce 出 Llama 2 的性能,并在此基础上进行后续迭代。
一、核心技术路线与实现方式
数据部分
-
中英双语支持:DeepSeek 模型是面向中英文混合训练的,这与纯英文的 Llama 2 不同。
-
数据质量更高:虽然整体流程 follow Llama 2,但在数据清洗和构建上投入更多精力,提升了数据集的质量。
模型架构
完全复用 Transformer 架构:包括model architecture、初始化方法、training等均与 Llama 2 一致。
两种规模版本:
-
7B 参数版本(对标 Llama 2 的 7B)
-
67B 参数版本(对标 Llama 2 的 70B)
训练策略
-
预训练总量:约 2T token,与 Llama 2 的训练量相当。
-
后训练阶段(Post-training):
-
包括 SFT(监督微调)和 DPO(偏好优化),流程与主流做法一致。
二、性能表现与对比
- 超越 Llama 2:论文中提到 DeepSeek 在多个评测任务上超过了 Llama 2 270B 的效果。
主要归因于数据质量的提升,而非模型结构上的重大改进
三、改动细节
1. 学习率调度策略的改进
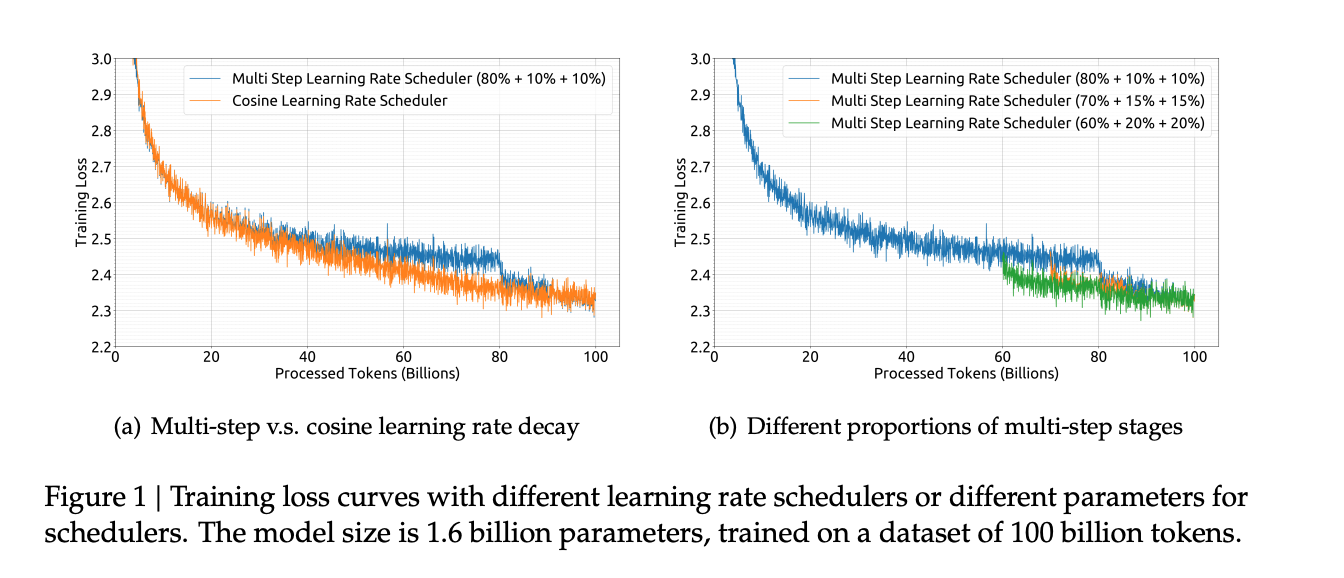
关于在Learning Rate Schedule的选择上,Llama 2选择Cosine Learning Rate Schedule,但Deepseek选择Multi-step Learning Rate Schedule
Cosine Learning Rate Schedule
- 核心思想:学习率从初始值开始,按照余弦函数的形状逐渐下降到一个最小值(通常是 0 或接近 0),然后再可能回升(如果是周期性 Cosine)。
公式形式(单周期):
-
:第 t 步的学习率
-
:初始学习率
-
:最低学习率
-
:当前训练步数
-
:总训练步数
特点:
在训练初期下降慢,后期下降快;
需要提前设定好总的训练步数(或 epoch 数);
如果中途更改数据量或训练计划,难以灵活调整。Multi-step Learning Rate Schedule
- 核心思想:在预设的几个训练阶段(epoch 或 step 点)将学习率按一定比例降低(如乘以 0.1),通常采用常数段+跳跃式下降的方式。
-
示例设置:
milestones = [30, 80] # 在第 30 和 80 个 epoch 时降低学习率
gamma = 0.1 # 每次降低为原来的 1/10-
特点:
- 每一段学习率是固定的;
- 更容易根据训练情况手动干预;
- 不依赖于总训练步数,适合动态调整训练计划;
- 实现简单,广泛用于目标检测、图像分类等任务。
DeepSeek 为何选择 Multi-step?
大模型训练过程中,数据可能会动态更新(比如新增高质量数据),导致原定的训练步数发生变化。Cosine 调度一旦设定就无法轻易更改,否则会影响学习率曲线,影响收敛。 Multi-step 更加灵活,可以在不同阶段手动或自动调整学习率下降时机,而不破坏整体训练节奏。 不过虽然学习率变化方式不同,但最终性能与 Cosine 接近,根据figure 1说明这种改动是有效且实用的。
2、Scaling Law 与 超参数研究
Skilling Law(缩放定律) 是一种经验公式或预测函数,用于指导在给定算力预算下,如何选择最优的模型大小、数据量和训练策略,以获得最佳性能。
其本质是回答这个问题:
“如果我有 X 算力资源,我应该训练多大的模型、用多少数据、设置怎样的超参数才能得到最好的效果?”
- 比如你有 1000 张 A100 GPU 卡,只能使用三个月,你想知道:
- 应该训练一个 70B 的模型还是 130B?
- 配套训练多少 token 数据最合理?
- 学习率、batch size 等怎么设置?
这些都会影响模型的训练速度、效果,如果你的算力是固定的,那么必然会有个最优的config,我们发现了这种Scaling law,那么就可以通过小模型实验,推测大模型的最佳config,从而节约成本
Deepseek在这篇paper上做了关于Scaling law的research,而且比起之前的Scaling law做了更深入的研究。
-
以往的 Scaling Law(如 Chinchilla、Llama 2)主要关注:
- 模型大小(model size)
- 数据总量(data size)
DeepSeek 则首次将 超参数(learning rate, batch size 等) 也纳入 Scaling Law 的研究范围。
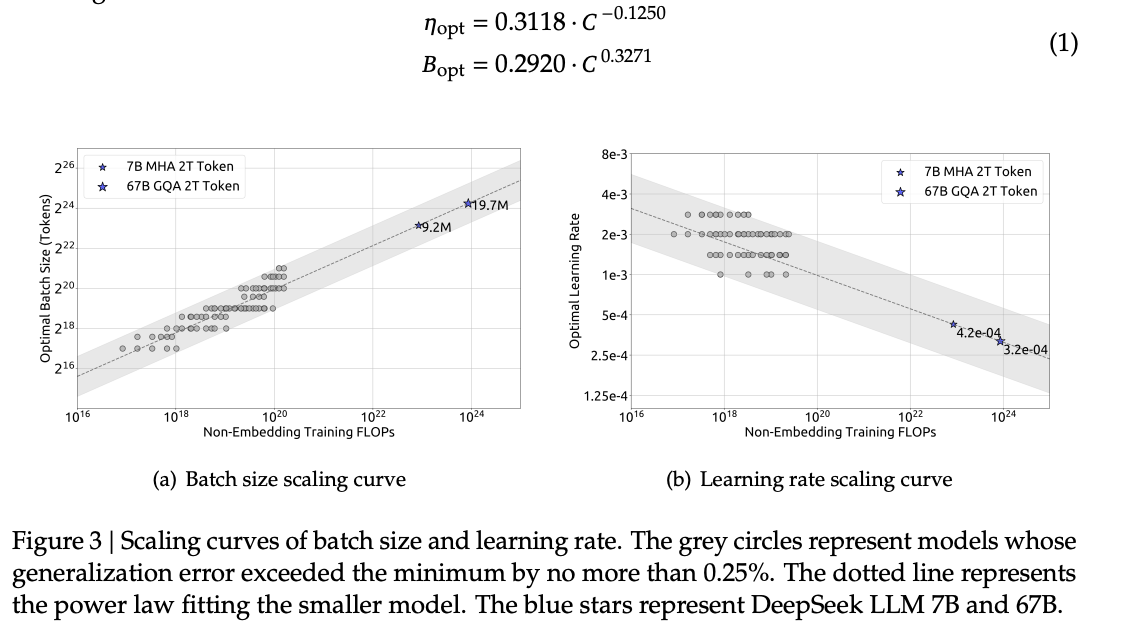
论文中 Figure 3 展示了:
随着算力增加,最优的 base size 和 learning rate 如何变化;
这些关系呈现出幂律(power law)形式;
可以从小规模模型外推到大规模模型。-
之前的方法(如 Chinchilla)在估算算力需求时,仅考虑了模型层数、参数数量等基础因素;
-
DeepSeek 指出这些方法忽略了 Transformer 中注意力机制带来的“计算开销”,因为在进行注意力计算时,它的复杂度为
,T为序列长度,D为模型维度,这部分注意力计算在传统的Scaling law被忽略了
-
因此他们提出了一个新的公式(论文中的 Equation 2),更精确地建模实际所需的 FLOPs(浮点运算次数);
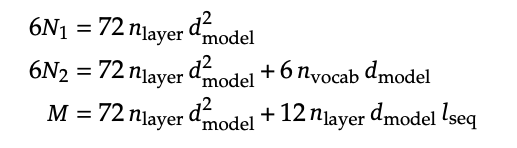
- 横轴:表示算力(FLOPs),即浮点运算次数,可理解为使用多少张 GPU 训练了多长时间(如 1000 张卡训练 1~3 个月)。
- 纵轴:模型性能(loss),越低越好。
- 灰色小点:是通过小规模模型训练得到的实验结果(少量算力训练出的小模型)。
- 虚线拟合曲线:基于这些小模型拟合出的 Scaling Law 曲线,用于预测大规模模型的效果。
Deepseek提出了更精确的公式
-
传统公式:
,忽略注意力机制带来的额外开销;
-
DeepSeek 新公式:
,其中
表示每个 token 的平均计算成本(FLOPs/token),并考虑了注意力机制的平方级复杂度;
然后他们明确指出“注意力机制”的高阶复杂度影响
- 注意力机制的计算复杂度为
,随着序列长度增长呈平方增加;
- 传统方法低估了这部分开销,导致资源配置不准确;
- DeepSeek 强调这种“conversational overhead”应被纳入模型配置决策中 。
3、对 Data Quality 的新洞察
以往 Scaling Law 假设所有数据质量一致,DeepSeek 提出不同数据质量会导致不同的最优模型与数据配比,即使算力相同,高质量数据可以支持更大模型或更少数据量 。
-
DeepSeek 从一开始就注重数据质量,这也是其模型性能优于同期模型的重要原因之一;
-
表明 Scaling Law 不只是“暴力美学”,而是需要结合数据、模型、训练策略的综合优化 。

还有一点就是Deepseek对“刷榜”这件事也做了一些诚实的探讨,当时大模型研究比较浮躁,人们更多关注llm在榜单上的表现,而模型在榜单上的表现其实和在真实应用的时候会存在一个gap。
比如说Deepseek针对考试题型进行微调后,原本47分的模型可以升到71分,坦诚地告诉读者,我们模型真正的能力并不那么强。
如果您认为博文还不错,请帮忙点赞、收藏、关注。您的反馈是我的原动力

















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









