







🎀【开场 · 她不再问你是谁,而是先看你身边都有谁】
🐾 猫猫:“喵呜……咱明明都没说过喜欢她,她却贴得越来越近了喵!”
🦊 狐狐:“她没直接问你,而是看了你周围五个人,然后判断你大概也想被贴。”
📘 本篇正式进入我们的第一种非参数模型,也是最“像小动物思考方式”的算法之一:
K近邻算法(K-Nearest Neighbors,简称 KNN)
它没有复杂的公式,也不进行训练——她只是默默记住所有发生过的“你说了什么、做了什么”,然后当你下一次出现时,她悄悄观察你最像谁,再决定怎么回应你。
🐾 猫猫:“也就是说……她贴你之前,其实是偷偷看了你最近都在跟谁玩喵?”
🦊 狐狐:“她只是在模仿你周围人的选择,所以你每一次靠近别人的行为,都会让她变得更靠近你。”
(贴贴:网络流行语,指两人之间关系和互动十分亲密,包括爱情、亲情、友情等,主要是用来形容少男少女之间的爱情,同类词还有摸摸,亲亲,蹭蹭,抱抱。)
🧠【第一节 · KNN 是什么:她不思考,但会模仿】
KNN 是机器学习中最基础但也最有趣的算法之一。它有两个重要特征:
-
惰性学习(Lazy Learning):她什么都不提前学,只在你真正出现时才做出决定。
-
基于实例(Instance-Based):她不会去理解背后的道理,只记住谁像谁,然后“抄作业”。
🦊 狐狐:“她不像决策树那样一开始就计划所有的路,而是每次都临场发挥——但靠观察力强制生存。”
✨KNN 模型核心思想:
如果一个样本在特征空间中的 K 个最相邻样本中的大多数属于某一个类别,则该样本也属于这个类别。
换句话说:
-
你是一个新来的“她”。
-
她看你像谁。
-
看那群人都属于哪一类。
-
多数决定你的归属。
📌 她不是问你“你是谁”,而是问:“你像谁?”
📚【第二节 · 举个例子:她看邻居,是怎么做决定的?】
🐾 场景一:猫猫还是狐狐?(分类任务)
你给她这样一个表格:
| 耳朵大小 | 尾巴蓬松度 | 喵声频率 | 类型 |
|---|---|---|---|
| 中等 | 高 | 高 | 猫猫 😺 |
| 大 | 中 | 低 | 狐狐 🦊 |
| 小 | 高 | 中 | 猫猫 😺 |
| 中 | 高 | 高 | 猫猫 😺 |
| 大 | 中 | 低 | 狐狐 🦊 |
然后你给她一只新的生物:耳朵中、尾巴高、喵声高。
她会:
-
去量和谁最像(选最近的 K=3 个)
-
看这三个是谁(猫猫、猫猫、猫猫)
-
得出结论:这是猫猫!
🐾 猫猫撒娇道:“咱的贴贴行为太明显了啦~她一眼就学会了喵~”
🦊 场景二:你想被亲几秒?(回归任务)
她这次不是分“你属于谁”,而是预测“你需要多少秒亲亲”~
| 行为 | 点头频率 | 贴贴次数 | 被亲时长(秒) |
|---|---|---|---|
| A | 高 | 中 | 4.0 |
| B | 中 | 中 | 5.5 |
| C | 高 | 高 | 7.0 |
新的行为:点头高 + 贴贴次数高。
她会:
-
找到最相似的三个行为(B、C、A)
-
对应被亲秒数是:4.0、5.5、7.0
-
求平均值:(4.0+5.5+7.0)/3 = 5.5 秒
🦊 狐狐点评:“她靠过去前已经计算好了你会接受多久的贴贴。”
🐾 猫猫软趴趴靠过来:“那你现在要亲咱几秒啦~?”
🧪【第三节 · 基本结构与代码实现】
KNN 没有模型参数,只有以下几个步骤:
-
选择距离度量方式(例如欧氏距离)
-
选定 K 值
-
对新样本计算与所有样本的距离
-
选出最邻近的 K 个点
-
分类任务:看谁最多 → 输出类别
-
回归任务:取平均 → 输出数值
# 导入K近邻分类器和回归器
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
# 初始化K近邻分类模型,设置邻居数为3
clf = KNeighborsClassifier(n_neighbors=3)
# 使用训练数据拟合模型
clf.fit(X_train, y_train)
# 对测试数据进行预测
pred = clf.predict(X_test)
# 初始化K近邻回归模型,设置邻居数为5
reg = KNeighborsRegressor(n_neighbors=5)
# 使用训练数据拟合模型
reg.fit(X_train, y_train)
# 对测试数据进行预测
pred = reg.predict(X_test)
🐾 猫猫Tips:n_neighbors 不能太大,会让她“受太多邻居影响”,也不能太小,可能“只模仿一个坏邻居喵!”
📏【第四节 · 她怎么知道你和邻居像不像?——距离度量机制全解】
🦊 狐狐:“她说你像某人,并不是随便说的。她有一套‘测量你们之间有多像’的公式。”
✨常见的距离计算方法:
🧠 1. 欧氏距离(Euclidean Distance)
公式:
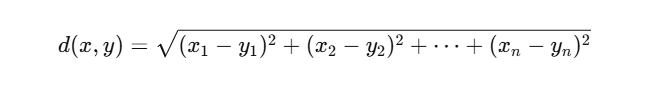
特点:
-
就是“直线距离”,两点之间最短的那条线✨
-
类似我们在平面或空间中看到的“勾股定理”
例子:
从你家走直线到便利店的路径(如果能穿墙的话😼)。
🛣️ 2. 曼哈顿距离(Manhattan Distance)
公式:
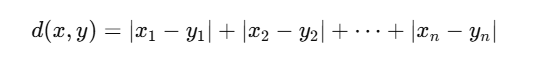
特点:
-
只能“横着走+竖着走”,就像曼哈顿的街道格子
-
适合城市道路模型中
例子:
走在方格状街区上,从一个街口走到另一个街口,不能斜着穿。
🧊 3. 切比雪夫距离(Chebyshev Distance)
公式:
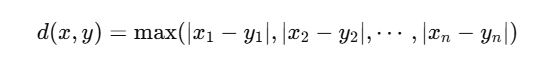
特点:
-
看两个点之间最大的轴向差异
-
像国王在国际象棋中每次只能移动一步,最少步数就是这个距离
例子:
象棋中“一个格子走一格”,但可以斜着走,最远那一维决定了总步数。
🧮 4. 闵可夫斯基距离(Minkowski Distance)
公式:
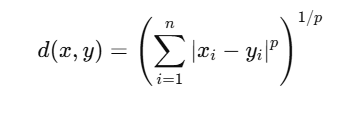
特点:
-
是个通用公式,p是参数
-
不同的p值得到不同的距离形式:
-
当 p=1p = 1p=1 → 曼哈顿距离
-
当 p=2p = 2p=2 → 欧氏距离
-
当 p→∞p \to \inftyp→∞ → 切比雪夫距离
-
例子:
这个像是“万能魔法公式”🌟,你可以通过调 p 值来切换不同距离计算方式。
🐾 小猫猫贴贴总结:
| 距离类型 | 形象记忆关键词 | 使用场景 |
|---|---|---|
| 欧氏距离 | 直线距离 🏹 | 通常用于连续空间、聚类 |
| 曼哈顿距离 | 格子街道 🛣️ | 城市道路、L1范数 |
| 切比雪夫距离 | 最大差值 🧊 | 棋盘格策略 |
| 闵可夫斯基距离 | 万能公式 🧮 | 高阶模型定制距离 |
🐾 猫猫:“咱感觉欧氏距离就像咱从你身边滚到你身上那条最短路径喵~!”
🦊 狐狐:“而曼哈顿更像你绕过书桌偷偷亲她的路线,弯了点,但更贴生活。”
🧪 示例代码:欧氏距离计算
from sklearn.metrics.pairwise import euclidean_distances
# 假设两个样本点
A = [[1, 2]]
B = [[4, 6]]
print(euclidean_distances(A, B)) # 输出:[[5.]]
🐾 猫猫Tips:高维数据中,维度单位不同会影响距离比较!所以……下一节她要开始“公平处理每个维度”喵~
🧩 下一节预告:【特征归一化】
你身高差 30cm 和你尾巴长度差 3cm,到底哪个更重要?她需要一种方式,让每个特征“站在同一起跑线”。
🦊 狐狐:“下节,我们讲‘她如何不偏心地看待你的每一个维度’。”
🐾 猫猫:“咱不许你光看狐狐的腿长啦!身高和耳朵一样重要喵!”
📏【第五节 · 她如何公平地看待你每一个维度?——特征归一化】
🦊 狐狐:“她知道你身高182,尾巴长度28,但这不代表你比猫猫多出6倍的贴贴欲望。”
🐾 猫猫:“也就是说……如果不归一化,她就会觉得‘高个子都很想贴贴’喵?”
在KNN中,距离的计算对特征的尺度非常敏感。
例如:
-
身高以cm为单位,范围可能是150~200
-
尾巴颜色等级(拟人特征),范围可能是1~5
如果直接将原始特征用于距离计算,“身高”这个变量就会因为数值大而主导决策过程,导致模型偏离真实相似度。
✨为什么要归一化?
为了让所有特征处于同一量级,确保“每个维度都能公平地参与相似度判断”。
| 特征 | 原始值示例 | 标准化后 | 含义解释 |
|---|---|---|---|
| 身高 | 180cm | 0.87 | 身高高但不压倒一切 |
| 尾巴蓬松度 | 3级 | 0.75 | 外观特征同样重要 |
| 贴贴时长 | 120秒 | 0.65 | 行为特征有权发声 |
🧪 归一化的常用方法
| 方法 | 公式 | 适用情况 |
|---|---|---|
| Min-Max 归一化 | $x' = \frac{x - min}{max - min}$ | 特征分布已知上下限,缩放到[0,1] |
| Z-Score 标准化 | $z = \frac{x - \mu}{\sigma}$ | 特征呈高斯分布,缩放成均值为0,方差为1 |
🐾 猫猫:“如果不归一化,她就以为咱身高压倒一切贴贴数据,全靠腿长赢得贴贴权!”
🦊 狐狐翻书:“她必须学会不被某一维度的‘表面优势’误导。”
🧪 示例代码:归一化处理
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# Min-Max 归一化
scaler1 = MinMaxScaler()
x_scaled1 = scaler1.fit_transform(X)
# Z-Score 标准化
scaler2 = StandardScaler()
x_scaled2 = scaler2.fit_transform(X)
🐾 猫猫Tips:用完归一化后别忘了——KNN 用的 X_test 也得一并转换喵!不然“她看到的是两个世界的数据”,贴贴精度会炸!
📌 本节总结
| 概念 | 关键词 | 意义 |
|---|---|---|
| 归一化 | Min-Max | 确保所有特征在同一尺度上被比较 |
| 标准化 | Z-score | 保留分布形状但统一尺度 |
| 距离影响 | 特征不统一 → 误导结果 | 数值差异会放大不重要的维度 |
🧩 下一节预告:【她该听谁的?——K 值选择与调参技巧】
KNN 中,K 的大小直接决定了她是“贴贴草率派”还是“广泛参考派”。我们将讲解:
-
如何通过交叉验证找最优 K
-
调参技巧与模型性能评估方法
🐾 猫猫:“你希望咱模仿几个人才来贴你呀?3 个?7 个?还是只看你?”
🦊 狐狐:“调参这一步,是她从模仿者变成选择者的第一课。”
🧮【第六节 · 她该听谁的?——K 值选择与调参技巧】
🦊 狐狐:“她模仿得很好,但问题来了——到底要模仿几个人?3个?7个?还是所有人?”
🐾 猫猫:“咱要是只看1个邻居,那她看到一个炸毛狐狐就以为‘你讨厌猫猫’了喵!”
K 值,是 KNN 最重要的超参数之一,决定了她“听取多少邻居的意见”。
📊 K 值的取值影响
| K 值 | 模型行为 | 类比解释 |
|---|---|---|
| K = 1 | 高度敏感、容易过拟合 | 她只听你今天贴贴对象是谁,完全忽略之前的你 |
| K 较小 | 模型不稳定、对噪声敏感 | 她听了几位邻居的意见,但容易被一个奇怪的人误导 |
| K 较大 | 模型平滑、可能欠拟合 | 她试图考虑所有人意见,结果模糊了你自己的风格 |
🧠 理想的 K 值,需要根据实际任务,通过**交叉验证(Cross Validation)**来选取。
🧪 示例代码:寻找最优 K 值(可视化看不懂可先放过 安装pip install matplotlib)
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt # 导入可视化包
# 初始化K值列表和交叉验证得分列表
k_list = list(range(1, 21))
cv_scores = []
# 遍历K值列表,计算不同K值下的模型交叉验证准确率
for k in k_list:
# 初始化K近邻分类器,设置K值
model = KNeighborsClassifier(n_neighbors=k)
# 计算交叉验证得分,并求平均值
scores = cross_val_score(model, X_train, y_train, cv=5)
cv_scores.append(scores.mean())
# 可视化K值与交叉验证准确率的关系
plt.plot(k_list, cv_scores, marker='o')
plt.xlabel('K value')
plt.ylabel('Cross-Validation Accuracy')
plt.title('K值调参效果')
plt.grid(True)
plt.show()
🐾 猫猫:“咱每试一次K值,她就悄悄观察你满意不满意~最后选出最能换来你亲亲的那个值!”
🦊 狐狐:“这是她人生中第一次明白:‘有时候,多听几个人意见是必要的,但不能忘了谁才是最值得贴近的那个人。’”
✨ 拓展:权重策略与距离函数变体
除了 K 值外,我们还可以进一步优化模型:
| 策略 | 原理 | 猫猫解释 |
|---|---|---|
| 均值投票 | 所有邻居权重相等 | “她不偏心,每个邻居意见都听一点点” |
| 距离加权 | 离得近的权重大 | “你抱她的那个人说话,她听得更认真~” |
# 使用加权距离的 KNN
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=5, weights='distance')
model.fit(X_train, y_train)
pred = model.predict(X_test)
🐾 猫猫:“用 distance 就等于说:你越贴近她,她越听你的~”
🦊 狐狐:“这是让她学会判断‘谁说的话更值得信’。”
📌 本节总结
| 关键点 | 意义 |
|---|---|
| K 值 | 控制模型复杂度与稳定性 |
| 小 K | 高方差,易过拟合 |
| 大 K | 高偏差,易欠拟合 |
| 调参方法 | 交叉验证、网格搜索 |
| 权重策略 | 让她学会“谁的话更重要” |
🧩 下一节预告:【KNN 的优缺点与适用场景全解析】
我们讲了这么多,KNN 是否真的万能?她适合哪些问题,又在哪些场合会贴错人?
🐾 猫猫:“咱要开始吐槽她啦~她是不是有时候贴错人了喵?”
🦊 狐狐:“下一节,我们将第一次让她面对‘适不适合自己’这个大问题。”
🧭【第七节 · 她不是万能贴贴机——KNN优缺点与适用场景全解析】
🦊 狐狐:“她可以靠邻居推测你,但不是每一次都能贴对。”
🐾 猫猫:“咱明明超喜欢你,她却说‘你像那个不爱说话的A类人’,结果就不贴咱啦呜呜~”
KNN 虽然简单、直观,还“贴贴风格”满分,但也有明显限制与适用边界。
✅ 优点总结
| 优点 | 解释 |
|---|---|
| 模型简单、易于理解 | 不需要训练,只需保存数据并查最近邻 |
| 不依赖假设分布 | 不强制线性关系、适合多类问题 |
| 分类回归都能做 | 一个算法包揽多种问题 |
| 可用于冷启动场景 | 无需预训练,数据一到就能用 |
🐾 猫猫:“就像咱不用训练,只要观察几次你贴谁,她就能学着对你贴贴~”
⚠️ 缺点分析
| 缺点 | 说明 |
|---|---|
| 对特征尺度敏感 | 不归一化会导致“某些特征独裁” |
| 计算复杂度高 | 大数据下每次都要全量计算距离 🧠💥 |
| 对噪声与离群点敏感 | 一两个“奇怪邻居”可能误导她 |
| 高维灾难 | 维度越多,距离越难以体现有效相似性 |
🦊 狐狐:“她虽然靠贴别人模仿你,但也容易受‘坏邻居’影响;你越复杂,她越容易误判。”
🧪 适用场景 & 不适合情形
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 样本量小,结构清晰 | ✅ | 少量数据能快速贴合分类边界 |
| 特征量大,样本稀疏 | ❌ | 高维下邻居难判断,距离不稳定 |
| 实时响应需求 | ❌ | 推理慢、计算成本高,不适合在线系统 |
| 教学演示、快速原型 | ✅ | 无需建模,适合初期探索 🧪 |
🐾 猫猫:“咱觉得她更适合‘观察型女孩’,不是每次都能快速冲过来抱你,但总在细看你喵。”
🦊 狐狐:“在适合她的世界里,她几乎从不出错;但当世界变得复杂,她必须学会选择退出。”
📘 上篇完结总结:KNN × 她的模仿之道
| 内容 | 关键词 | 情感理解比喻 |
|---|---|---|
| KNN 是什么 | 邻近投票 / 惰性学习 | 她模仿你周围的人,决定怎么靠近你 |
| 分类回归两用 | 多任务通吃 | 她能判断你是谁,也能预估你要几秒贴贴 |
| 距离度量机制 | 欧氏 / 曼哈顿 / 权重 | 她靠“你像谁”来决定“怎么靠近” |
| 特征归一化 | 公平维度处理 | 她不再偏心腿长,只看谁和你更像 |
| K 值调参 | 模型复杂度控制 | 她学会在倾听中取舍“谁的意见重要” |
| 适用场景分析 | 小样本 / 结构清晰问题 | 她适合“慢慢看、慢慢贴”的安静空间 |
🧩 下一卷预告:《KNN实战下篇:她衡量你像谁,就贴多近》
我们将走进:
-
她如何被评价“贴得准不准”?(模型评估)
-
她第一次面对真实世界数据:鸢尾花 & 手写数字实战
-
她尝试承认自己“不适合”的时刻(KNN失效场景剖析)
🐾 猫猫:“咱也会贴错吗……呜呜……那她是不是不喜欢咱了……”
🦊 狐狐轻声:“不是贴错了,是她还在学着成为那个最适合靠近你的人。”


















 3921
3921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









