







从零开始搭建 AIGC 系统:新手也能轻松掌握的实操教程
在这个 AI 技术飞速发展的时代,AIGC(人工智能生成内容)系统已从高大上的技术概念,逐渐成为企业和个人都能触碰的实用工具。无论是用于自动生成文案、设计图像,还是开发智能对话机器人,搭建一套属于自己的 AIGC 系统都能带来极大的便利。本文将以通俗易懂的方式,带你一步步完成 AIGC 系统的搭建,即使是技术新手也能轻松跟上节奏。
一、搭建 AIGC 系统前的核心准备
在正式动手搭建之前,我们需要明确目标并做好基础准备,这就像盖房子前要先确定户型和准备建材一样重要。
明确系统定位与需求
首先要想清楚,你搭建的 AIGC 系统主要用来做什么?是专注于文本生成(如写文章、写代码),还是图像生成(如设计图片、制作插画),或者是两者兼具的综合型系统?不同的定位会影响后续的技术选型和搭建步骤。
如果是个人使用或小型团队试用,初期可以从单一功能入手,比如先搭建一个文本生成系统;如果是企业级应用,可能需要考虑多模态生成、高并发处理等更复杂的需求。
硬件与软件环境准备
硬件方面,虽然 AIGC 系统对硬件有一定要求,但并非高不可攀。对于入门级的文本生成系统,一台配备 8 核 CPU、16GB 内存的电脑或服务器基本能满足需求;如果涉及图像生成或大语言模型,建议配备 NVIDIA 显卡(如 RTX 3090、RTX 4090 等),显卡的显存越大,能运行的模型规模也就越大。
软件方面,操作系统推荐使用 Linux(如 Ubuntu 20.04 或 22.04),因为大多数开源 AI 项目对 Linux 的支持更完善。此外,还需要安装一些基础工具:
- Python 3.8 及以上版本(AIGC 系统开发的主要编程语言)
- 包管理工具 pip(用于安装 Python 依赖库)
- Git(用于获取开源项目代码)
- Docker(可选,用于简化环境配置和部署)
二、AIGC 系统搭建的核心步骤
第一步:选择合适的开源模型
目前市面上有很多成熟的开源 AIGC 模型,新手可以站在巨人的肩膀上,无需从零开发模型。以下是一些常用的开源模型推荐:
- 文本生成:LLaMA 系列(如 LLaMA 2)、ChatGLM、Qwen 等,这些模型在对话、创作等任务上表现出色,且有不同规模的版本可供选择。
- 图像生成:Stable Diffusion、Midjourney(有开源替代方案)等,能根据文本描述生成高质量图像。
以文本生成为例,我们可以选择 LLaMA 2 的开源版本,它有 7B、13B 等不同参数规模,7B 参数的模型在普通显卡上也能运行。
第二步:搭建基础运行环境
接下来,我们需要为模型搭建一个可以运行的环境。这里以 Linux 系统为例,介绍具体步骤:
- 安装 Python 和 pip:大多数 Linux 系统会预装 Python,可通过python --version查看版本,若版本过低,可通过官方网站下载安装包进行升级。pip 通常会随 Python 一起安装,若未安装,可运行apt-get install python3-pip(Ubuntu 系统)进行安装。
- 创建虚拟环境:为了避免不同项目的依赖冲突,建议使用虚拟环境。运行以下命令创建并激活虚拟环境:
# 安装虚拟环境工具
pip install virtualenv
# 创建名为aigc-env的虚拟环境
virtualenv aigc-env
# 激活虚拟环境
source aigc-env/bin/activate
- 安装模型依赖库:不同的模型需要不同的依赖库,以 LLaMA 2 为例,需要安装 transformers、accelerate 等库,可运行以下命令:
pip install transformers accelerate torch sentencepiece
第三步:部署模型并实现基础功能
环境搭建完成后,就可以部署模型并实现基础的生成功能了。
- 获取模型文件:LLaMA 2 等模型需要通过官方渠道申请获取,也可以在一些开源社区找到合规的共享版本。将下载好的模型文件解压到指定目录,例如./models/llama2-7b。
- 编写基础调用代码:使用 Python 编写一段简单的代码来调用模型,实现文本生成功能。以下是一个示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型和分词器
model_path = "./models/llama2-7b"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
# 输入提示词
prompt = "请写一篇关于春天的短文"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda") # 若有GPU,使用cuda加速
# 生成文本
outputs = model.generate(**inputs, max_new_tokens=200, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
运行这段代码,模型就会根据输入的提示词生成关于春天的短文,这标志着基础的 AIGC 功能已经实现。
第四步:搭建交互界面(可选)
如果想让系统更易用,可以搭建一个简单的交互界面。对于新手来说,使用 Streamlit 是一个快速的选择,它能让你用 Python 代码快速构建 Web 应用。
- 安装 Streamlit:
pip install streamlit
- 编写界面代码:创建一个app.py文件,编写如下代码:
import streamlit as st
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型和分词器(同上)
model_path = "./models/llama2-7b"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
st.title("AIGC文本生成系统")
prompt = st.text_input("请输入你的提示词:")
if st.button("生成"):
with st.spinner("正在生成..."):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(** inputs, max_new_tokens=200, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
st.write(response)
- 运行界面:在终端运行streamlit run app.py,然后在浏览器中访问提示的地址,就能看到一个简单的文本生成交互界面了。
三、系统优化与功能扩展
搭建好基础系统后,我们可以根据需求进行优化和功能扩展,让系统更加强大和实用。
性能优化
- 模型量化:对于显存有限的设备,可以使用模型量化技术,如 4-bit 或 8-bit 量化,在牺牲少量性能的情况下,大幅降低显存占用。可以使用 bitsandbytes 库实现量化。
- 缓存机制:对于频繁出现的相同或相似提示词,可以缓存生成结果,减少重复计算,提高响应速度。
功能扩展
- 多模态生成:集成图像生成模型(如 Stable Diffusion),实现文本到图像的生成功能。
- 对话记忆:在对话系统中添加记忆功能,让模型能够记住之前的对话内容,提升对话的连贯性。
- 参数调节:在交互界面中添加温度(temperature)、最大长度(max_new_tokens)等参数的调节功能,让用户可以根据需求控制生成结果的风格和长度。
四、常见问题与解决方法
在搭建 AIGC 系统的过程中,新手可能会遇到一些问题,以下是一些常见问题及解决方法:
- 模型加载失败:可能是模型文件不完整或路径错误,检查模型文件是否解压完整,路径是否正确。
- 运行速度慢:若使用 CPU 运行,速度会较慢,建议使用 GPU;也可以尝试使用更小参数的模型。
- 生成结果质量差:可以调整温度参数(temperature 越低,结果越确定;越高,结果越多样),或优化提示词,提供更具体的要求。
五、总结
搭建 AIGC 系统并非遥不可及,只要按照步骤一步步操作,新手也能成功搭建出属于自己的 AIGC 系统。从选择模型、搭建环境,到部署模型、实现功能,再到优化扩展,每一步都有章可循。
随着技术的不断发展,AIGC 系统的应用场景会越来越广泛。希望本文的教程能帮助你迈出 AIGC 实践的第一步,在实践中不断探索和完善,让 AIGC 技术为你带来更多价值。如果你在搭建过程中遇到其他问题,欢迎在评论区交流讨论,让我们一起在 AIGC 的世界里共同进步。
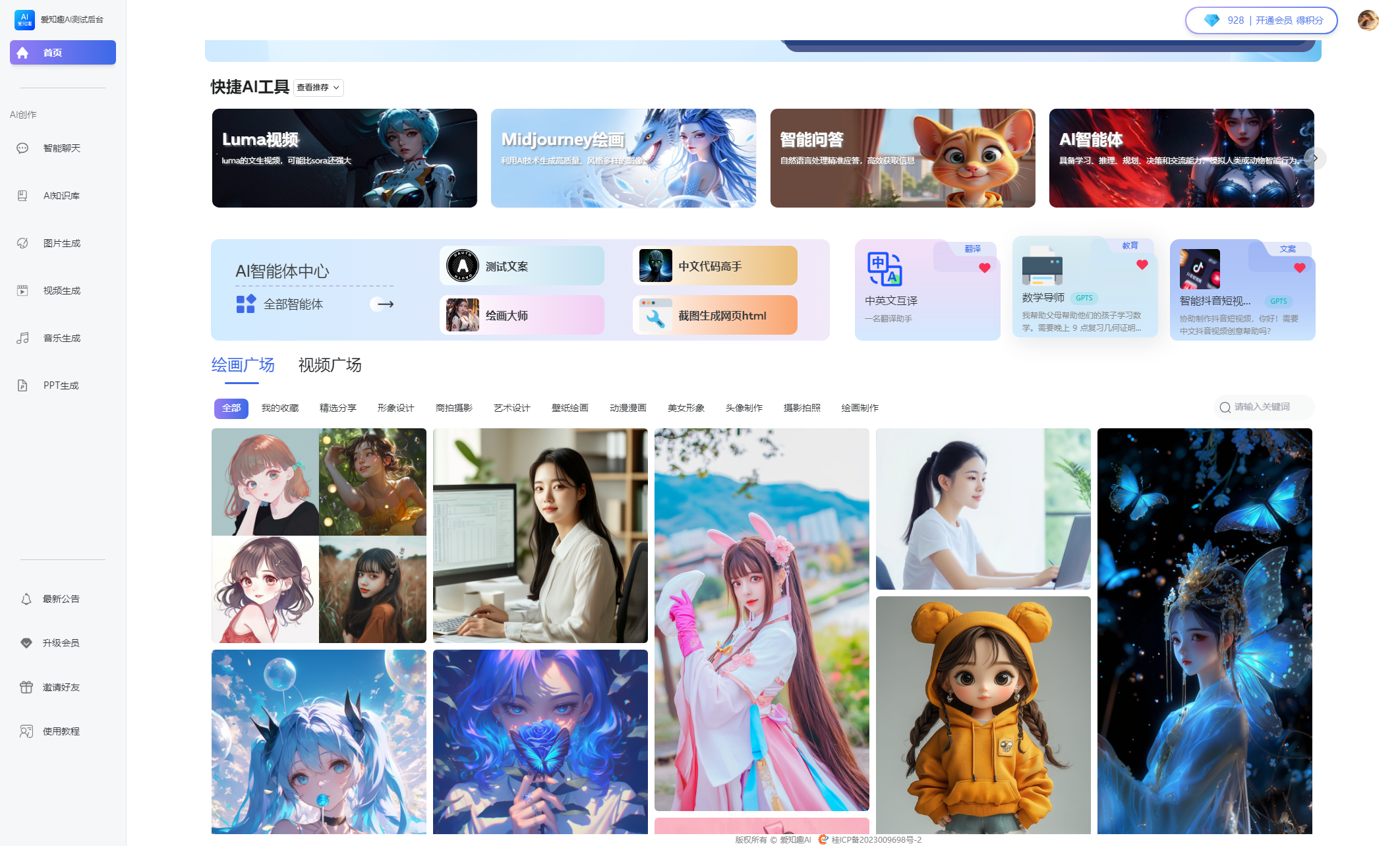
爱知趣AI系统最新版本在线演示地址(系统终身免费更新)
在线演示
前端演示(电脑打开):https://ai.91aopusi.com
后端演示(电脑打开):https://ce6688.92zhiqu.com/aizhiqu/admin
后台演示账号:super密码:123456
立即体验爱知趣 AI 系统,开启您的智能创作之旅!
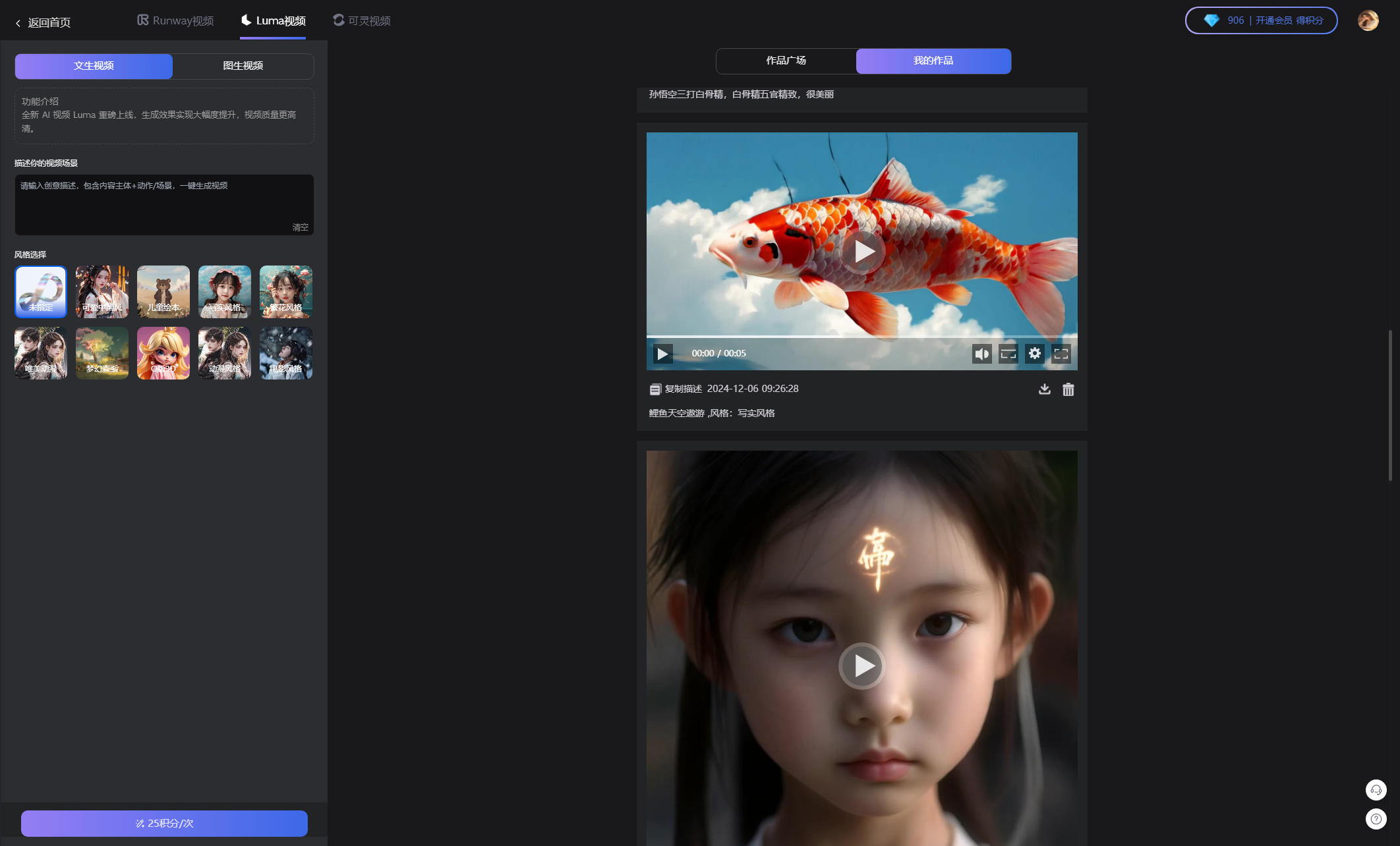
核心主要功能:智能聊天、思维导图,文档分析,Al知识库(扣子AI)、图片生成(DALL绘画、midjourney绘画)、视频生成(Runway、Luma、可灵)音乐SUNO生成、PPT生成。
长期迭代更新,系统上线2年时长,一直在迭代更新
技术栈
-
多端支持PC端,H5端,小程序,APP端
-
前端:采用 VUE3 技术,打造流畅的用户界面。
-
后端:基于 Node.js 构建,保障系统稳定运行。
-
独立手机端(小程序、h5、app):uniapp
-
数据:MySQL8.0 + redis
-
运行环境:Linux 环境,确保高效与安全。
🔥特色功能亮点
🔥1、极速部署:利用宝塔工具,10 分钟即可完成部署,即使是小白也能轻松操作。
🔥2、简单配置:仅需配置数据库,即可启动系统,快捷方便。
🔥3、强大在线配置框架:95% 的数据可在后台统一管理,带来丝滑的操作体验。
🔥4、丰富模型支持:支持主流公司的最新模型,包括 OpenAI 的 GPT 系列、Google 的 BERT、百度的文心一言、阿里云的通义千问、腾讯的腾讯混元、讯飞的讯飞星火,以及 Claude、DeepSeek、Midjourney、Suno、Luma、kling、replicate、Runway 等众多知名模型,满足不同用户的多样化需求。
🔥5、自定义对话模型:可对模型名称、别名、单次积分扣除数量等进行自定义设置。
🔥5、对接扣子AI,支持多模态模式,支持知识库上传,支持工作流,支持插件调用。功能强大
🔥6、对话账号池具备极为庞大的对话账号资源,数量几近无限。该账号池对 OpenAI、Azure、文心一言、讯飞星火、清华智谱等多个平台予以全面支持。
🔥7、多会话隔离与参数配置:支持对话多会话隔离,参数可独立配置,同时实现云端存储和消息云端漫游。
🔥8、内容安全过滤:通过内置词库、自定义词库和第三方(百度内容审核)进行多层安全检测,确保内容安全。
🔥9、开放式对话插件:已支持联网查询功能,为对话提供更多信息支持。
🔥10、绘画账号池:拥有无限量的绘画账号,每个账号可单独设定并发线程,实现线程隔离,并可设置出图模式。
🔥11、绘图服务管理:可在线启动、重启、关闭绘图服务,实时查看队列数量,并区分绘图普通(relax)、快速(fast)、极速(turb)模式,分别设置扣除积分。
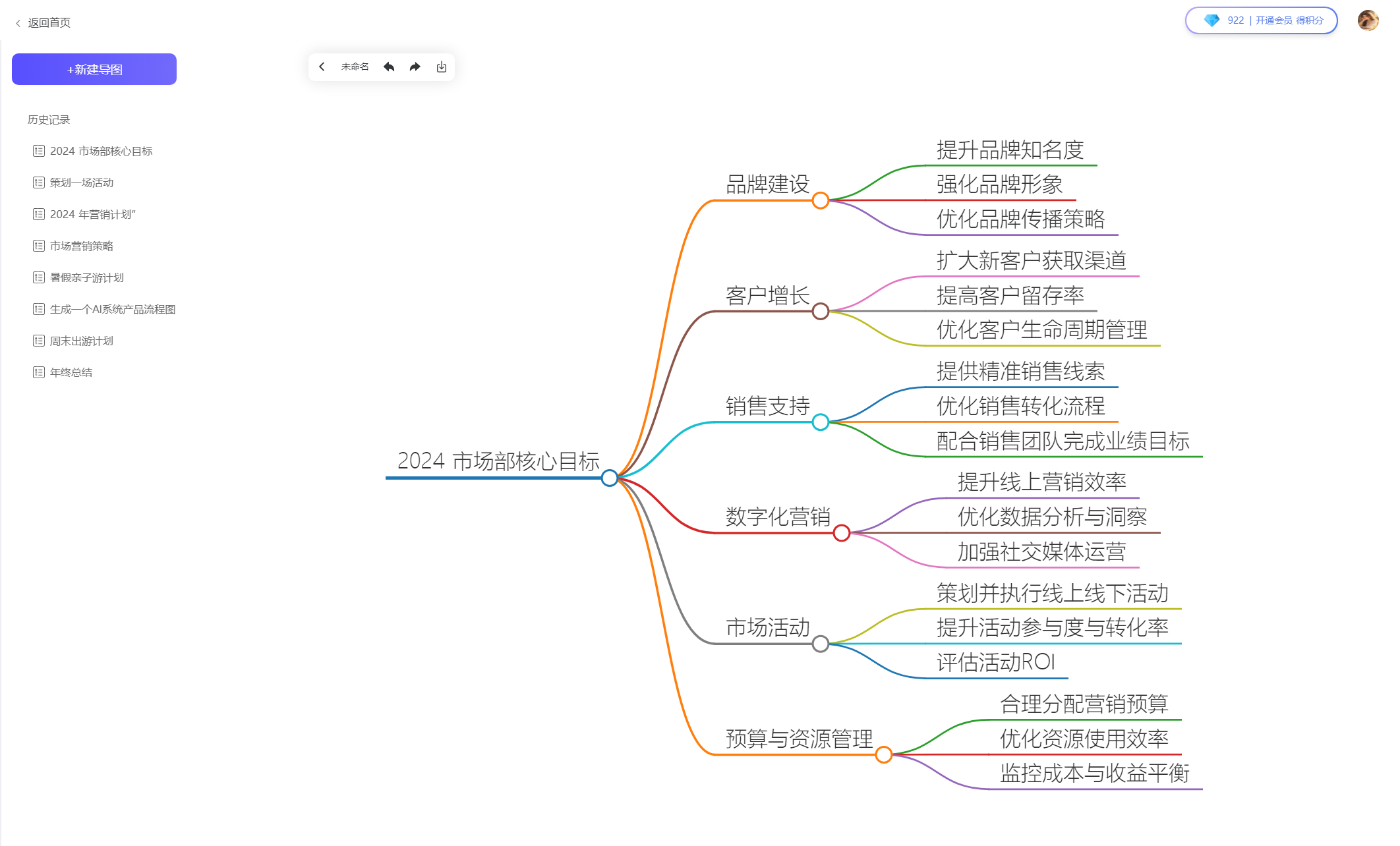
🔥12、思维导图生成:一键根据需求生成思维导图,并可导出为 PNG 或 SVG 格式。
🔥13、灵感广场:用户可公开展示自己的绘图作品(私有绘图不展示),激发创作灵感。
🔥14、应用市场:可在后台动态添加和管理应用,不断拓展系统功能。
🔥15、用户系统:支持微信扫码登录和手机号码登录,方便快捷。
🔥16、支付系统:集成微信(支持扫码支付 + JSAPI)、支付宝、虎皮椒、多种支付方式。
🔥17、兑换码系统:提供兑换码功能,增加用户福利与互动。
🔥18、站点在线配置:可在后台在线配置站点的 LOGO、名称等信息。
🔥19、邀请机制:通过好友邀请获得对应奖励,并具备防止恶意自邀的检测机制。
🔥20、积分自定义:支持对对话各个模型和绘画各个操作单独自定义扣除积分数量。
🔥21、用户端菜单控制:可动态控制用户侧边栏菜单的显隐,以及设置用户端动态菜单,支持内嵌网页外🔥22、部链接跳转和内部路径跳转。
🔥23、敏感词检测:保障内容合规性,维护良好的使用环境。

















 9042
9042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









