







目前我们对Transformer模型的研究已经很全面了,关于它的复现成果也非常多,但都比较零散,不成系统,而且缺乏对Transformer改进变体的详细梳理,这对我们改模型写代码很不友好。传统源码,内容冗杂,不易理解,对于刚入手的同学来说较为困难。
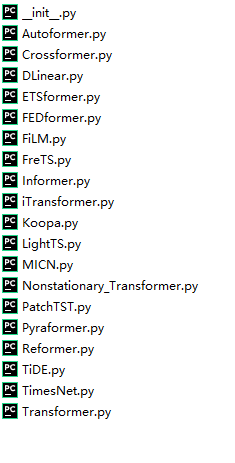
基于此,笔者整理了Informer,Autoformer,Crossformer,Dlinear,iTransformer,Patchtst,TSMixer,TimesNet,Transformer,FEDformer,TiDE, Reformer等19种最新的时间序列预测模型python代码,集成在一个代码中。
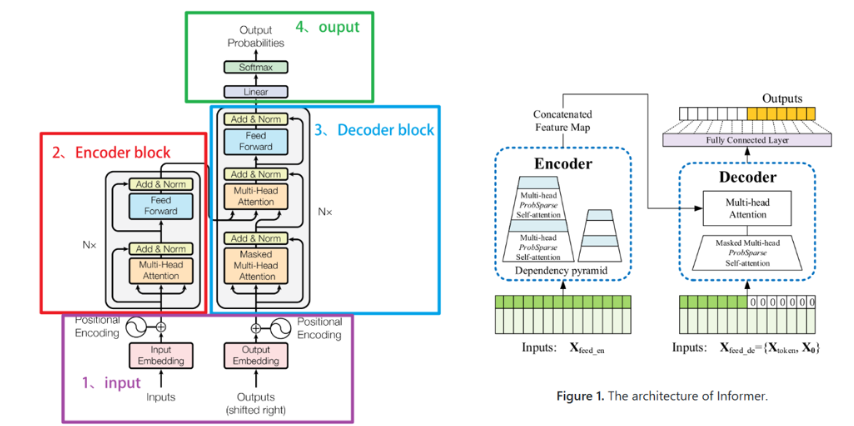
informer

Autoformer
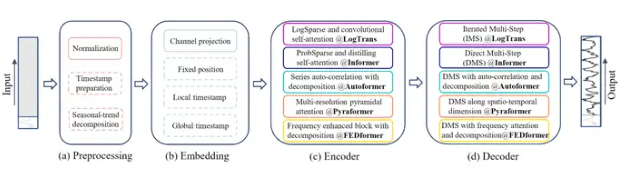
Dlinear
传统源码结构复杂,不易理解,上述代码的数据加载处理,训练,测试等过程全部进行重构,重构后的代码简介易懂,数据替换,参数修改方便。示例为csv数据;支持单变量多变量输入;多步单步预测;多个模型参考量巨大。
值得注意的是,该代码参数较多,集成程度较好,适合对python有基础了解的朋友进行学习,或者改进以发文章使用,小白适合更为基础的代码,对于这一点,我只能说太酷啦!!!!
transformer及其变体代码:
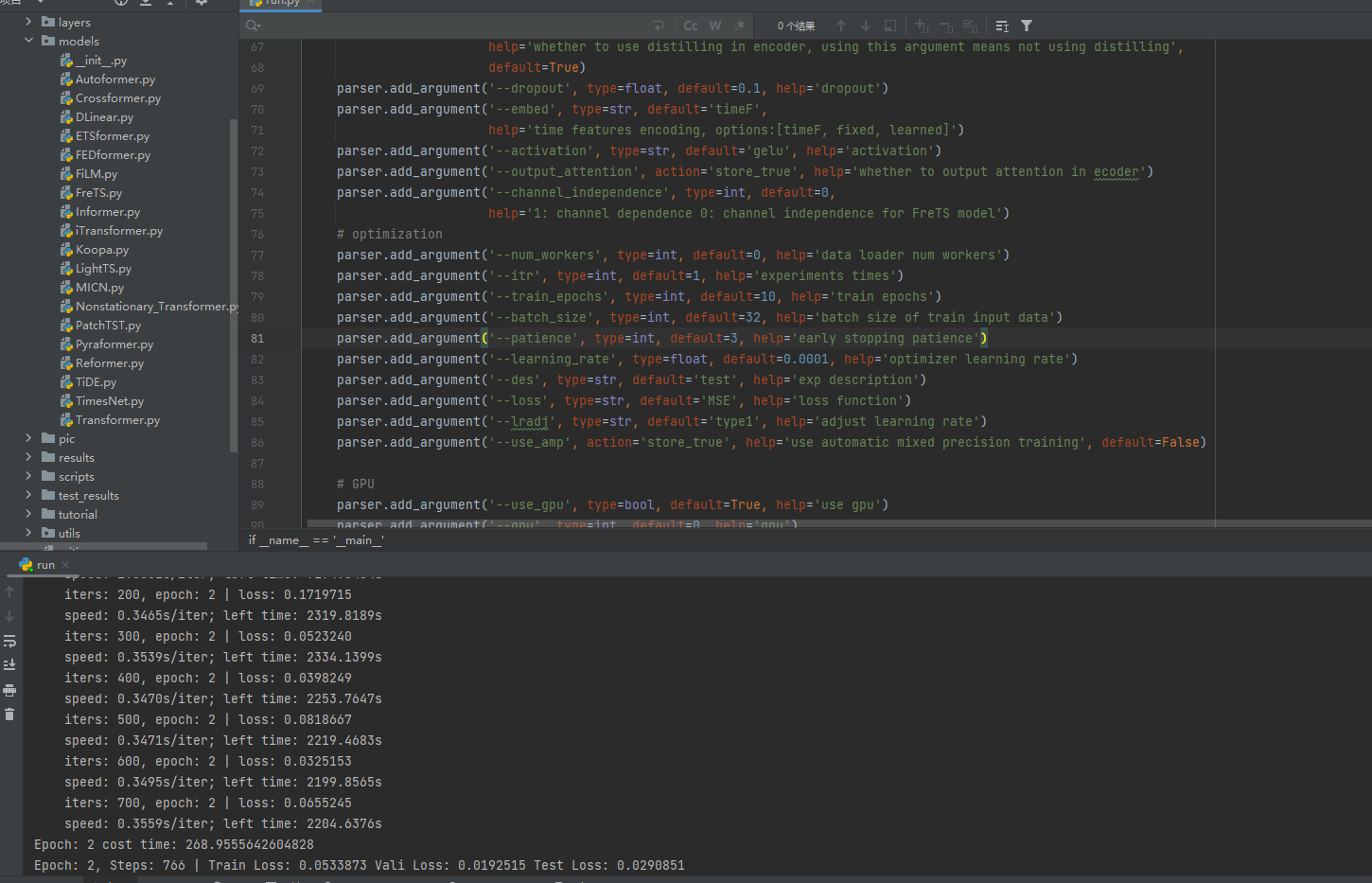
部分核心代码:
#集成的autoformer
import torch
import torch.nn as nn
import torch.nn.functional as F
from layers.Embed import DataEmbedding, DataEmbedding_wo_pos
from layers.AutoCorrelation import AutoCorrelation, AutoCorrelationLayer
from layers.Autoformer_EncDec import Encoder, Decoder, EncoderLayer, DecoderLayer, my_Layernorm, series_decomp
import math
import numpy as np
class Model(nn.Module):
"""
Autoformer is the first method to achieve the series-wise connection,
with inherent O(LlogL) complexity
Paper link: https://openreview.net/pdf?id=I55UqU-M11y
"""
def __init__(self, configs):
super(Model, self).__init__()
self.task_name = configs.task_name
self.seq_len = configs.seq_len
self.label_len = configs.label_len
self.pred_len = configs.pred_len
self.output_attention = configs.output_attention
# Decomp
kernel_size = configs.moving_avg
self.decomp = series_decomp(kernel_size)
# Embedding
self.enc_embedding = DataEmbedding_wo_pos(configs.enc_in, configs.d_model, configs.embed, configs.freq,
configs.dropout)
# Encoder
self.encoder = Encoder(
[
EncoderLayer(
AutoCorrelationLayer(
AutoCorrelation(False, configs.factor, attention_dropout=configs.dropout,
output_attention=configs.output_attention),
configs.d_model, configs.n_heads),
configs.d_model,
configs.d_ff,
moving_avg=configs.moving_avg,
dropout=configs.dropout,
activation=configs.activation
) for l in range(configs.e_layers)
],
norm_layer=my_Layernorm(configs.d_model)
)
# Decoder
if self.task_name == 'long_term_forecast' or self.task_name == 'short_term_forecast':
self.dec_embedding = DataEmbedding_wo_pos(configs.dec_in, configs.d_model, configs.embed, configs.freq,
configs.dropout)
self.decoder = Decoder(
[
DecoderLayer(
AutoCorrelationLayer(
AutoCorrelation(True, configs.factor, attention_dropout=configs.dropout,
output_attention=False),
configs.d_model, configs.n_heads),
AutoCorrelationLayer(
AutoCorrelation(False, configs.factor, attention_dropout=configs.dropout,
output_attention=False),
configs.d_model, configs.n_heads),
configs.d_model,
configs.c_out,
configs.d_ff,
moving_avg=configs.moving_avg,
dropout=configs.dropout,
activation=configs.activation,
)
for l in range(configs.d_layers)
],
norm_layer=my_Layernorm(configs.d_model),
projection=nn.Linear(configs.d_model, configs.c_out, bias=True)
)
if self.task_name == 'imputation':
self.projection = nn.Linear(
configs.d_model, configs.c_out, bias=True)
if self.task_name == 'anomaly_detection':
self.projection = nn.Linear(
configs.d_model, configs.c_out, bias=True)
if self.task_name == 'classification':
self.act = F.gelu
self.dropout = nn.Dropout(configs.dropout)
self.projection = nn.Linear(
configs.d_model * configs.seq_len, configs.num_class)
def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
# decomp init
mean = torch.mean(x_enc, dim=1).unsqueeze(
1).repeat(1, self.pred_len, 1)
zeros = torch.zeros([x_dec.shape[0], self.pred_len,
x_dec.shape[2]], device=x_enc.device)
seasonal_init, trend_init = self.decomp(x_enc)
# decoder input
trend_init = torch.cat(
[trend_init[:, -self.label_len:, :], mean], dim=1)
seasonal_init = torch.cat(
[seasonal_init[:, -self.label_len:, :], zeros], dim=1)
# enc
enc_out = self.enc_embedding(x_enc, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
# dec
dec_out = self.dec_embedding(seasonal_init, x_mark_dec)
seasonal_part, trend_part = self.decoder(dec_out, enc_out, x_mask=None, cross_mask=None,
trend=trend_init)
# final
dec_out = trend_part + seasonal_part
return dec_out
def imputation(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask):
# enc
enc_out = self.enc_embedding(x_enc, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
# final
dec_out = self.projection(enc_out)
return dec_out
def anomaly_detection(self, x_enc):
# enc
enc_out = self.enc_embedding(x_enc, None)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
# final
dec_out = self.projection(enc_out)
return dec_out
def classification(self, x_enc, x_mark_enc):
# enc
enc_out = self.enc_embedding(x_enc, None)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
# Output
# the output transformer encoder/decoder embeddings don't include non-linearity
output = self.act(enc_out)
output = self.dropout(output)
# zero-out padding embeddings
output = output * x_mark_enc.unsqueeze(-1)
# (batch_size, seq_length * d_model)
output = output.reshape(output.shape[0], -1)
output = self.projection(output) # (batch_size, num_classes)
return output
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask=None):
if self.task_name == 'long_term_forecast' or self.task_name == 'short_term_forecast':
dec_out = self.forecast(x_enc, x_mark_enc, x_dec, x_mark_dec)
return dec_out[:, -self.pred_len:, :] # [B, L, D]
if self.task_name == 'imputation':
dec_out = self.imputation(
x_enc, x_mark_enc, x_dec, x_mark_dec, mask)
return dec_out # [B, L, D]
if self.task_name == 'anomaly_detection':
dec_out = self.anomaly_detection(x_enc)
return dec_out # [B, L, D]
if self.task_name == 'classification':
dec_out = self.classification(x_enc, x_mark_enc)
return dec_out # [B, N]
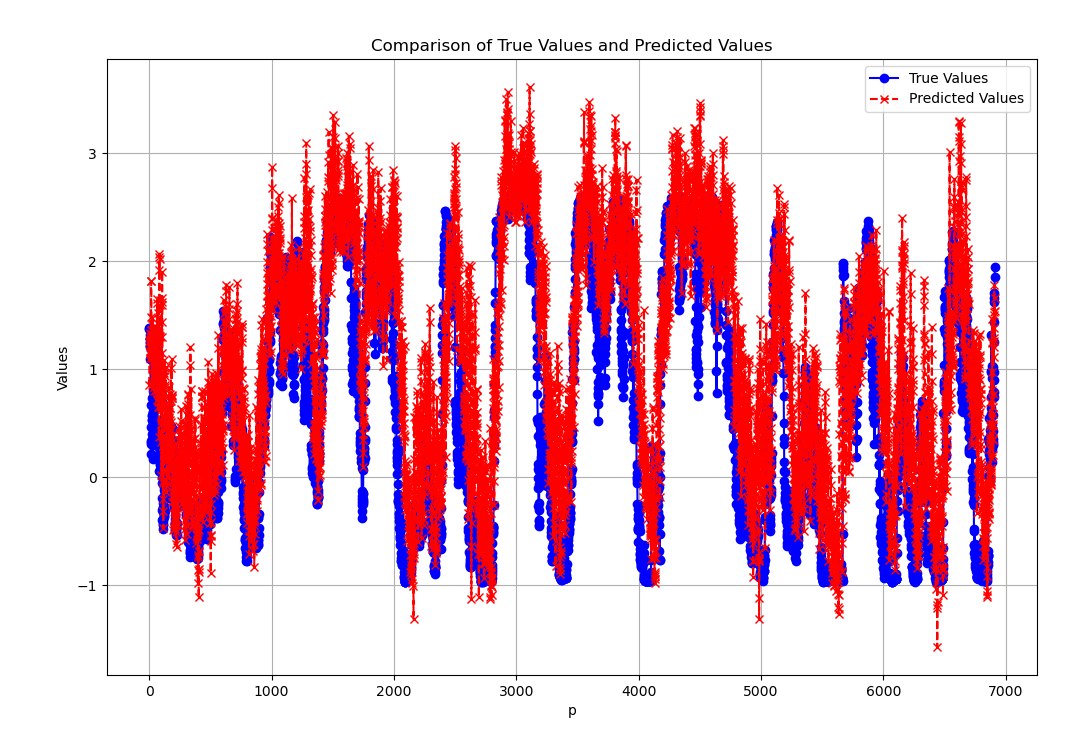
return None运行图:
包括模型:
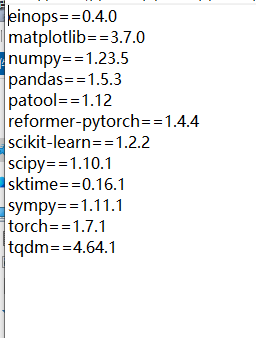
对应环境:
有兴趣进一步交流的朋友:欢迎关注公众好:年轻的战场ssd

















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









