







摘要
本文参考李国勇、杨丽娟编著的《神经模糊预测控制及其Matlab实现》(中国工信出版社、第4版)撰写,并非出于盈利目的,如有冒犯,还望海涵。详细介绍了如何利用感知机原理设计“逻辑与”,并且指出了感知机的局限性。
一、问题介绍
从原理出发往往比较枯燥难懂,本文将从实际例子出发看看如何通过感知机原理解决实际问题,最后再来刨析其中的理论。
逻辑与问题:
在数电中,我们学习过与门,在数据库中也有AND操作。简易而言,就是在两个输入(输入只能是0或者1)的情况下,只有当两输入同为1时,最终输出才是1,否则输出则为0;类似乘法y=X1*X2,其中y是输出,X1和X2为输入。
我们需要设计一个“功能”来实现这样的映射关系。
二、代码实现
2.1 详细代码
err_goal=0.001;
lr=0.9;
max_epoch=10000;
X=[0 0 1 1;0 1 0 1];
T=[0 0 0 1];
[M,N]=size(X);
[L,N]=size(T);
Wij=rand(L,M);
y=0;
b=rand(L);
for epoch=1:max_epoch
NETi=Wij*X;
for j=1:N
for i=1:L
if(NETi(i,j)>=b(i))
y(i,j)=1;
else
y(i,j)=0;
end
end
end
E=(T-y);
EE=0;
for j=1:N
EE=EE+abs(E(j));
end
if(EE<err_goal)
break;
end
Wij=Wij+lr*E*X';
b=b+sqrt(EE);
end
epoch,Wij,b2.2 代码解释
我们先看输入矩阵X和输出矩阵T,如果不理解矩阵也没关系,具体形式如下所示,其中f就是我们要设计的“感知器”,方框内的每一纵列作为输入,而右侧方框内对应位置的一列作为输出,比如第一列“ 0 0 ”对应的就是“ 0 ”,而第二列“ 0 1 ” 对应的就是“0”....第四列“ 1 1 ”对应的为 “1” 。

后续,它设计了一个矩阵Wij,我们称之为输出层加权矩阵(因为它和输出层直接相连,改变输出层的维度)。这个矩阵我们可以发现他是1行2列的矩阵,但是为什么是1行2列而不是1行3列或者不是2行1列呢?
其实设计的感知器或者神经网络最终都要从输入的维度降到输出的维度,通过线性代数的知识,我们知道当1*2(1行2列)的矩阵乘以2*1的矩阵(单一的输入矩阵)就可以得到1*1的值,完成降维的操作。所以,实际上,你甚至可以设计一个2*2的输入矩阵Qij放在中间来调整效果,因为1*2的矩阵乘上2*2的矩阵再乘上2*1的矩阵,最终还是会降低到1*1,这也是为什么如今会有多层神经网络的原因,越多的网络层,意味着结构更加灵活,理论上可以拟合的内容越逼近,但是训练量更大,也可能会陷入过拟合和局部最优的问题。
在输入X经过Wij矩阵时,进行了Wij*X的操作,得到了一个临时输出矩阵NETi,通过对NETi和阈值b矩阵的大小比较得到了输出矩阵Y。其中,由于Wij和b起初都是用随机值填充的矩阵,所以输出矩阵Y效果不一定很好。
这时候就需要通过误差修正来改变这个Wij和b:

于是就出现了Wij=Wij+lr*E*X';这意味着 “ 输出间的权重值变化量正比于输出单元期望输出和实际输出的差值 ”
但是鄙人未能理解为何阈值b=b+sqrt (EE),希望有读者顿悟以后指点一下。
通过多次迭代以后,即可得到一个合适Wij和阈值b来进行逻辑与的映射。
2.3 单步调试理解
起初我们可以看到随机的阈值b=0.9340,权重矩阵Wij=[0.0357,0.8491]

得到的NETi=[ 0, 0.8491, 0.0357, 0.8848],
然而NETi中所有的值都没达到阈值,故y为0矩阵[0 ,0 ,0, 0]
预期输出矩阵T和输出矩阵y做差得到误差矩阵E=[0,0,0,1]
得到误差和EE=1

因为误差和大于最初设计的误差极限0.001,所以不满足要求,需要修改权重后继续迭代:
修改后的输入权重矩阵计算得Wij=[0.9357 , 1.7491]
阈值b=1.9340
第二轮迭代:
计算得NETi=[ 0, 1.7491, 0.9357, 2.6848]
得y=[0,0,0,1]
E=[0,0,0,0]
EE=0<err_goal
满足要求,训练完成

三、感知机的相关理论
由于Wij输入权重矩阵的设计,我们发现实际上,它本身是在训练一个w1x1+w2x2-b的模型,当 w1x1+w2x2 > b 时,y=1,否则则为0。这可以很明显的在二维坐标上表示:
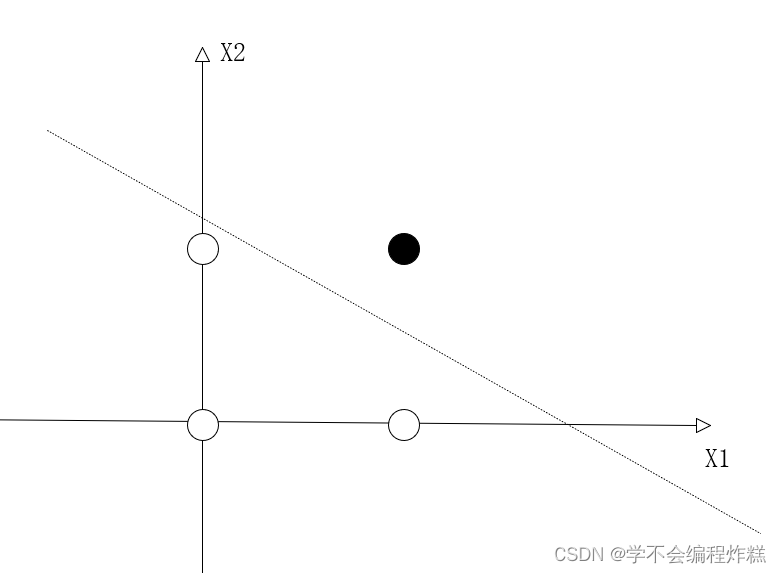
即找到一条斜线x2=(-w1/w2)x1+b/w2来区分(1,1)坐标和(0,0)、(0,1)、(1,0)坐标,这样感知机的几何解释也就十分清楚了。但是也正因此导致了感知机无法处理非线性分类问题,比如异或问题:
















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









