






ViT
直接上图
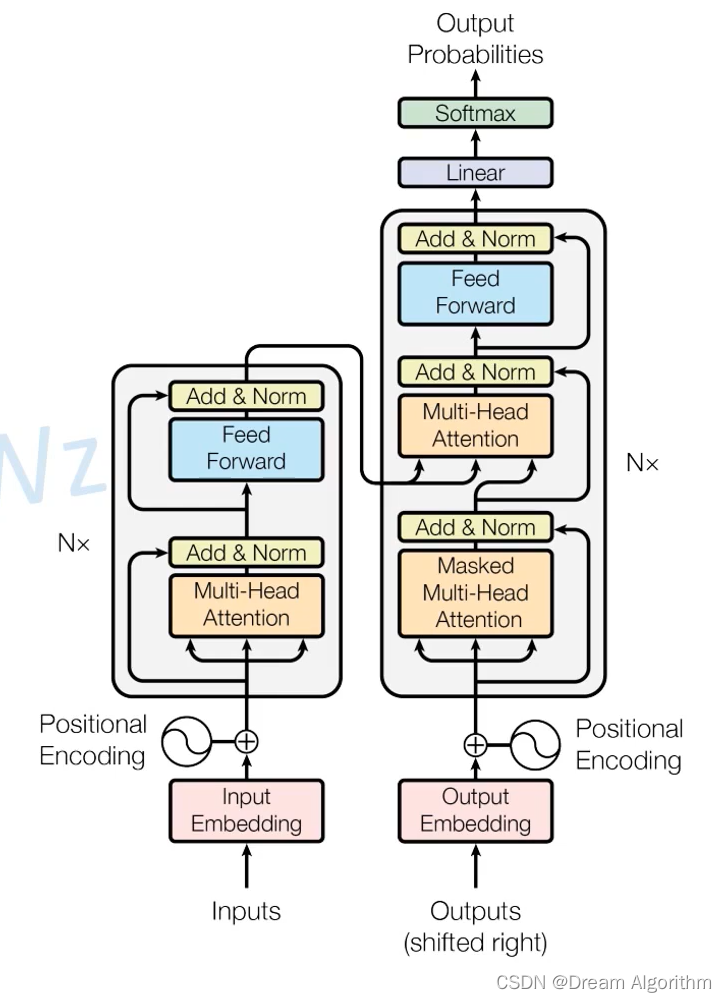
这个是最原始的transformer,后续出的一些transformer都是在这个基础上进行的改进。
里面的注意力机制借鉴李宏毅老师的图:
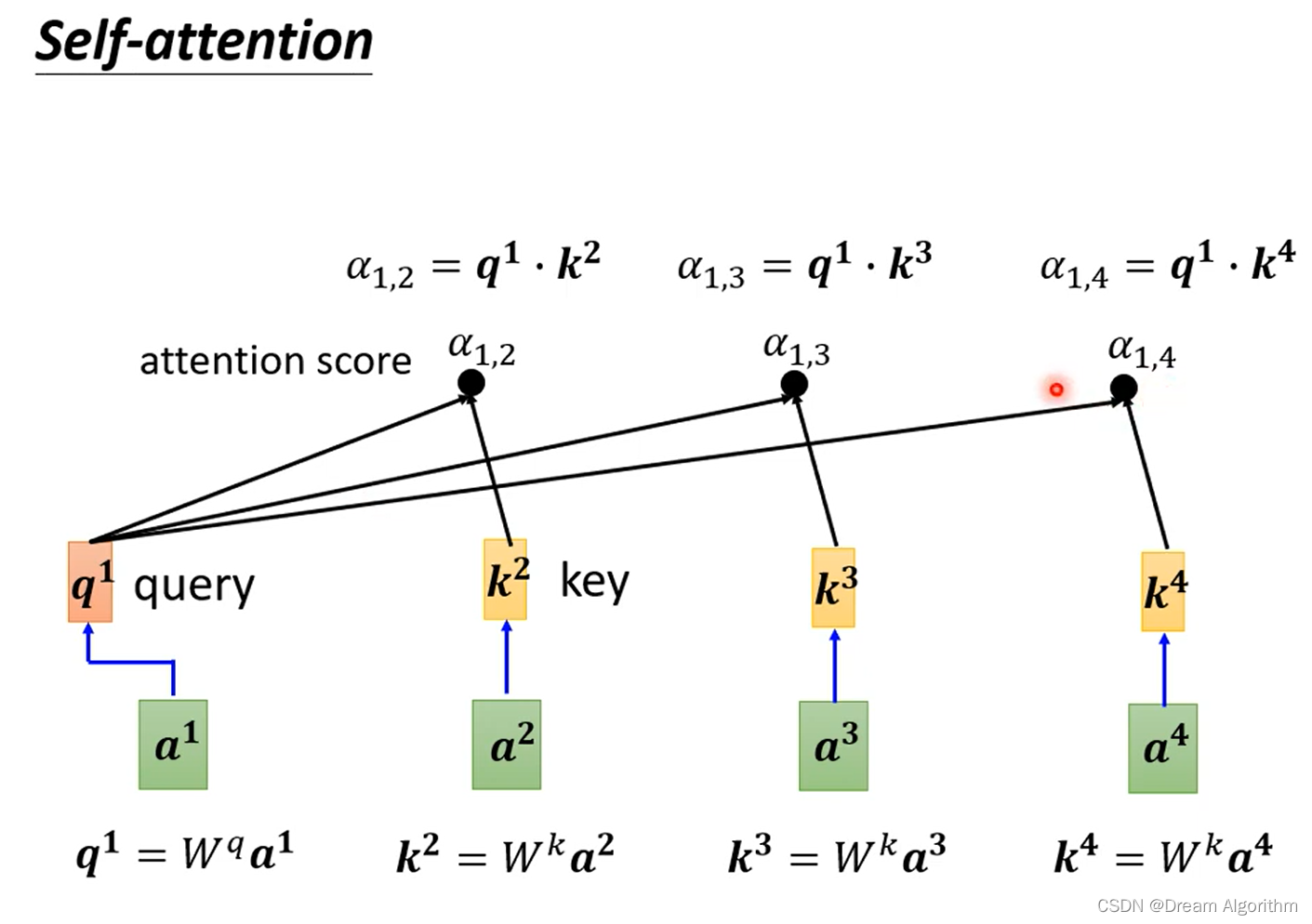
注意力分数是由query矩阵和key矩阵点成得到的。这个点乘是对全图进行处理,进行全图的自注意力。
Swintransformer
swintransformer是在ViT的基础上对全图进行了窗口化的处理。
直接上图:
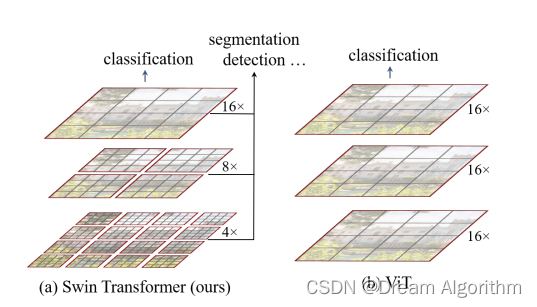
论文作者处理的方式是对整张图划分为许多窗口,这样处理起来效率更高,划分为一个个窗口之后,就带有了卷积的归纳偏置的性质,在处理图片的时候收敛更快,不容易过拟合(个人理解,如有错误欢迎批评)。
还有很多transformer的其他变体,例如BoTNet:
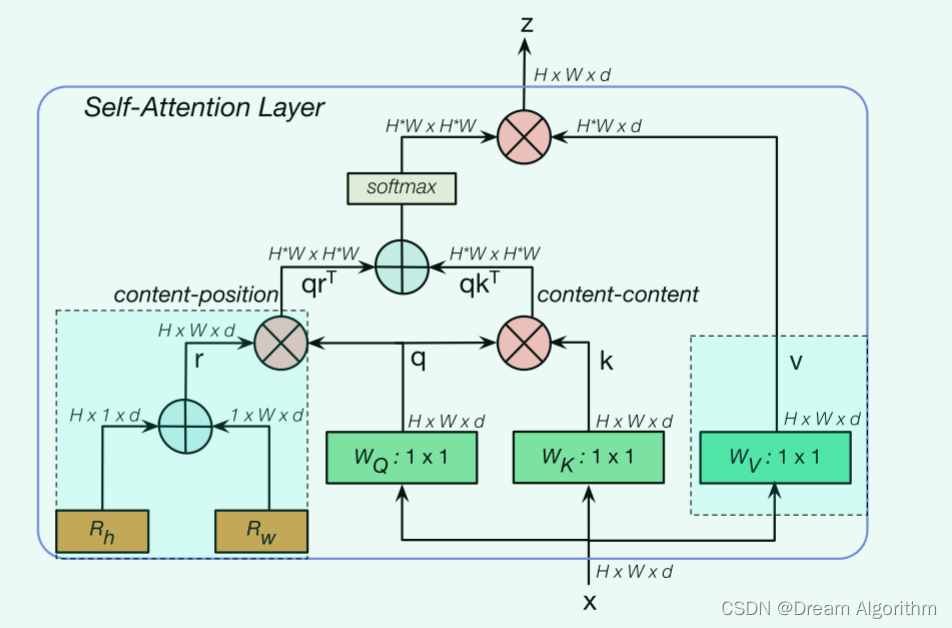
Cross_ViT:
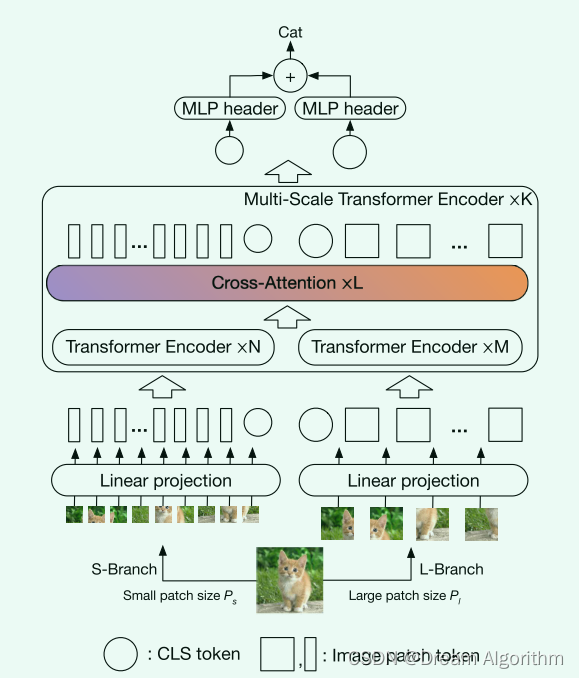
将图片划分为不同大小的patch,然后分别进行处理。
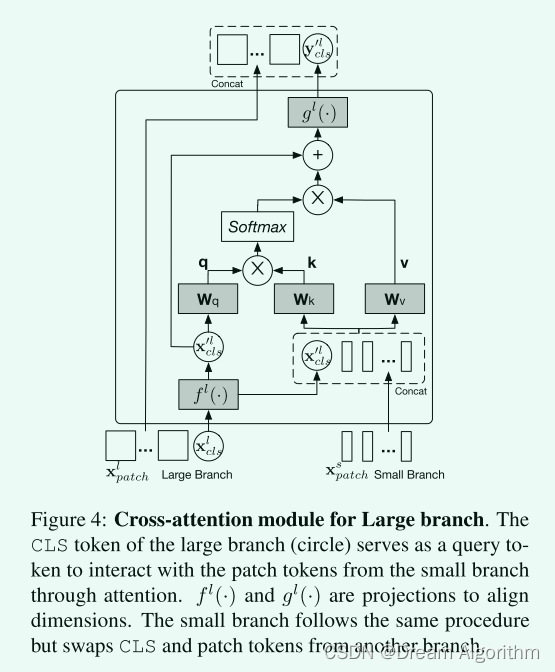
跨patch的注意力如图:
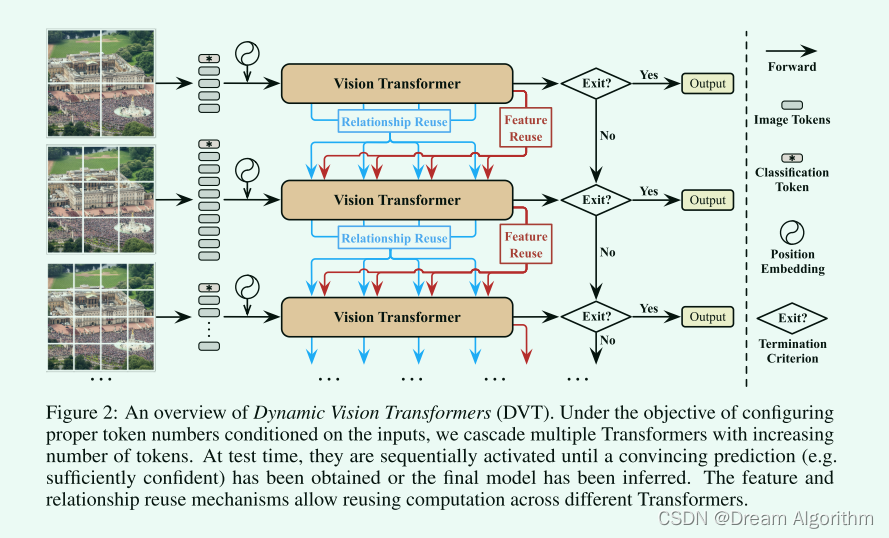
DynamicViT
上图:
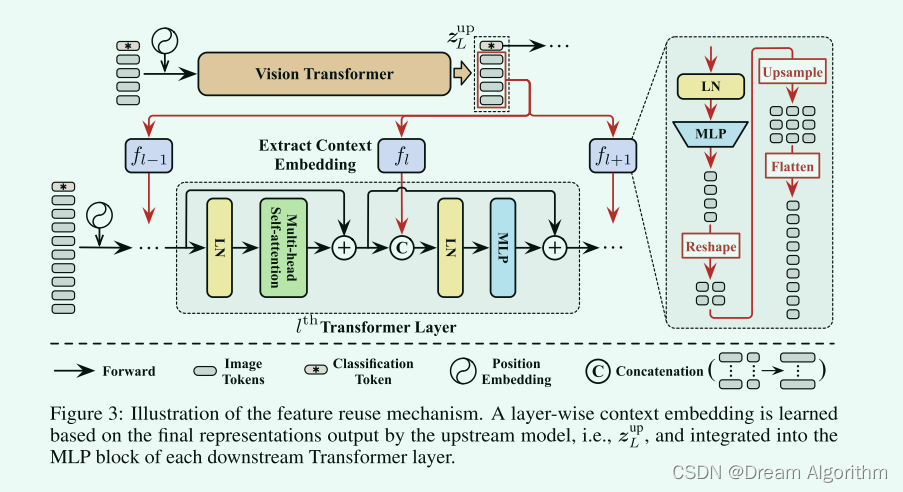
这里特征重利用为:
关系重利用为:
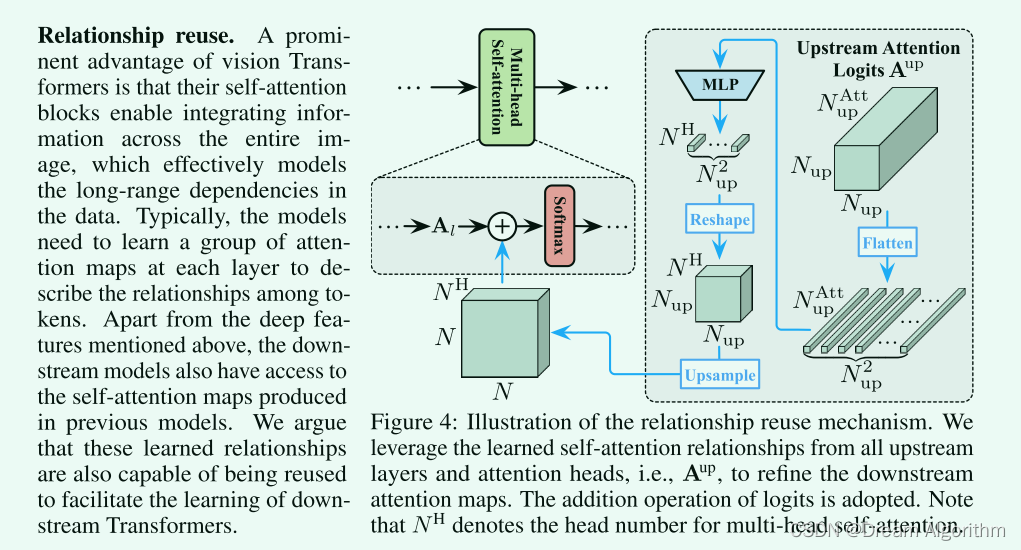
这里就不仔细介绍了,有兴趣的朋友们可以去下载原文多了解一下。
原文连接:
ViT:
arXiv:2010.11929
Swintransformer:
| arXiv:2103.14030 |
BoTNet:
https://arxiv.org/abs/2101.116Cross_ViT:
Cross_ViT:
| arXiv:2103.14899 |
DynamicViT:
| arXiv:2105.15075 |
还有很多transformer和卷积结合互补的文章,只要是我看过的以后也会陆续地有个小总结吧。欢迎大家关注我,及时的对我批评指正。















 1597
1597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









