







 本文深入探讨了机器学习中的欠拟合与过拟合现象,解释了两者如何影响模型的训练效果及泛化能力。欠拟合通常发生在模型过于简单,无法捕捉数据中的复杂模式;而过拟合则表现为模型过于复杂,对训练数据过度拟合,导致对未知数据预测能力下降。文章还讨论了泛化误差的概念,它是衡量模型对未来数据预测能力的重要指标。
本文深入探讨了机器学习中的欠拟合与过拟合现象,解释了两者如何影响模型的训练效果及泛化能力。欠拟合通常发生在模型过于简单,无法捕捉数据中的复杂模式;而过拟合则表现为模型过于复杂,对训练数据过度拟合,导致对未知数据预测能力下降。文章还讨论了泛化误差的概念,它是衡量模型对未来数据预测能力的重要指标。
欠拟合
在机器学习过程中,特别是线性回归,那么会对数据进行拟合
如果一条曲线经过的数据点很少且很多数据相当于没有用上

## 过拟合
过拟合是曲线对每一点的都会拟合
这样会导致模型具有很差的泛化能力
且测试集的数据进行测试有很大误差

泛化能力:
其实很简单 就是对未来数据的预测能力的表现
泛化误差:
对未来样本预测与实际的误差
wiki解释:一个机器学习模型的泛化误差(Generalization error),是一个描述学生机器在从样品数据中学习之后,离教师机器之间的差距的函数。使用这个名字是因为这个函数表明一个机器的推理能力,即从样品数据中推导出的规则能够适用于新的数据的能力
泛华误差公式:
这个公式有没有很眼熟,没错居然是损失函数的期望就是泛华误差 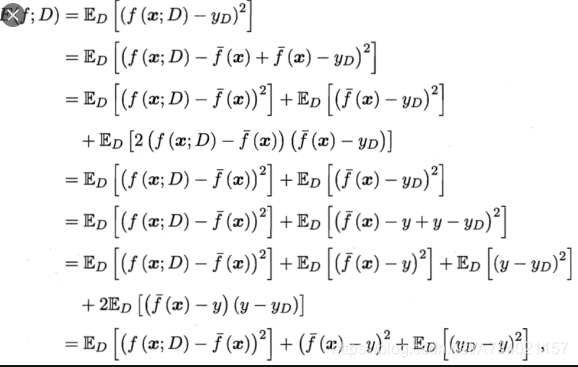

















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









