







 本文探讨了CUDA内核中浮点运算的IEEE-754标准、单精度与双精度的区别,以及内置函数、标准函数和原子操作对指令生成的影响。理解这些因素有助于提升CUDA程序的性能、精确度和正确性,尤其是在移植遗留应用和处理数值计算时。
本文探讨了CUDA内核中浮点运算的IEEE-754标准、单精度与双精度的区别,以及内置函数、标准函数和原子操作对指令生成的影响。理解这些因素有助于提升CUDA程序的性能、精确度和正确性,尤其是在移植遗留应用和处理数值计算时。
指令是处理器中的一个逻辑单元,直到CUDA内核代码什么时候会产生不同指令以及高级语言如何转换为指令,这对我们很重要。对两个功能等效指令的选择可以影响很多应用程序的特性,包括性能、精确度和正确性。当通过严格的数字验证请求,把遗留应用程序传输到CUDA时,就要特别留意这些问题。接下来将介绍浮点运算、内置和标准函数、原子操作这三个显著影响CUDA内核生成指令的因素。其中,浮点运算是针对非整数值的计算,并且会影响CUDA程序的精确度和性能。内置和标准的函数使用相同的数学运算,但有不同的精确度和性能。当调用多个线程执行操作时,原子指令确保了程序执行的正确性。
浮 点 指 令
自从浮点运算采用IEEE-754标准后,所有的主流处理器厂商都使用这一标准,包括NVDIA。这个标准规定将二进制浮点数据编码成3段:符号段(sign),一个比特位;指数段(exponent),多个比特位;以及尾数或分数段(fraction),多个比特位。如下图所示:

为了确保跨平台计算的一致性,IEEE-754定义了32位和64位浮点格式,它们分别对应C语言数据类型的float和double,它们的位长度不同,如下图所示:

给定一个32位的浮点变量,其中标志位s占1位,指数e为8位,尾数v为23位,这个浮点变量可以表示成下图所示的格式。
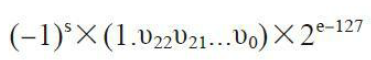
因为浮点变量相较于整型变量来说能够更精确的表示一个数值,所以这个浮点相较于整型变量来说能够更精确地表示一个数值,所以这个浮点变量表达式在应用中非常重要。然而数值的精确度是有限的,并且用浮点类型存储的数据是离散且有限的。例如下面的代码:
float a = 3.1415927f;
float b = 3.1415928f;
if(a == b)
{
printf("a is equal to b\n");
}
else
{
printf("a is not equal to b\n");
}
在与IEEE-754标准兼容的体系结构中,其输出为:a is equal to b。在这个例子中,这两个值都不能在浮点型变量a和b所在的有限比特位中存储。因此,两者的数值只能被近似存储,这样的话两者的值就恰好相等了。浮点型数值不能精确存储,只能在四舍五入后再存储。例如,在前面例子中,使用默认的近似舍入,将不可精确表示的1数值表示成最接近的数值。还有一些其他的舍入方式,例如,向零取舍(向绝对值最小的方向舍入)、向上取舍、向下取舍。
浮点编程中需要考虑的另一个方面是浮点数的粒度问题。像上面所讨论的。浮点数的粒度比整数来说要好得多。然而浮点数只能在离散的区间间隔内存存储数据。随着浮点数值离零越来越远(在正负两个方向上),表示数值的区间也会随着增大,如下图所示:

可以使用C语言中的数学函数nextafterf,从一个给定值找到下一个最高位浮点数。下表通过一些数字说明了一个浮点数和下一个之间的区间间隔意味着在任何可能产生极端数值的应用中,对数值进行四舍五入会对输出有很大的影响。

在浮点数值上进行操作的指令被称为浮点指令。CUDA支持所有在浮点数上常见的算术运算,如加法、乘法、除法和减法。就像上面提到的,CUDA和其他遵循IEEE-754双标准的编程模式支持两种浮点精确:32位和64位。这些不同的格式也分别被称为单精度和双精度。因为双精度浮点数的位数是单精度浮点数的两倍,所以双精度可以表示更多的数值。这意味着双精度浮点数既有更好的细粒度又有比单精度值更大的数值范围。例如,以之前所用的浮点精度为例,它使用的是双精度浮点数而不是单精度浮点数
double a = 3.1415927;
double b = 3.1415928;
if(a == b)
{
printf("a is equal to b\n");
}
else
{
printf("a is not equal to b\n");
}
当使用双精度变量存储时,a和b的最近似的表示值是不同的,最后的结果为:a is not equal to b。
内 部 函 数 和 标 准 函 数
除了单精度和双精度操作的区别,CUDA还将所有算数函数分成内部函数和标准函数。标准函数用于支持可对主机和设备进行访问并标准化主机和设备的操作。标准函数包含来自于C标准数学库的数学运算,如sqrt、exp和sin。单指令运算如乘法和加法。也包含在标准函数中。CUDA内置函数只能对设备代码进行访问。在编程中,如果一个函数是内部函数或是内置函数,那么在编译时对它的行为会有特殊响应,从而产生更积极的优化和更专业化的指令生成。这对CUDA内部函数来说是真实可信的。事实上,许多三角函数是直接在GPU硬件上实现的,因为它们中的大部分是用图形应用计算的(变换、旋转和其他在3D可视化应用上的操作)。
在CUDA中,许多内部函数与标准函数是有关联的,这意味着存在与内部函数功能相同的标准函数。举个例子,标准函数中的双精度浮点平方根函数也就是sqrt。有相同功能的内部函数是__dsqrt_rn。还有执行单精度浮点除法运算的内部函数:__fdividef。内部函数分解成了比与它们等价的标准函数更少的指令。这会导致内部函数比等价的标准函数更快,但数值精度却更低。因此可以在同一应用中交替使用标准函数和内部函数,但是它们在性能和数值精确度上会有所不同。标准函数和内部函数大大增加了CUDA应用程序的灵活性。它们作为细粒度旋钮,可以在运行操作基础上调整性能和数值精确度。
原 子 操 作 指 令
一条原子操作指令用来执行一个数学运算,此操作是一个独立不间断的操作,且没有其他线程的干扰。当一个线程在一个变量上成功完成一个原子操作时,那么不管有多少线程正在访问这个变量,这个变量的状态已经发生了改变。因为原子操作指令阻止了多个线程之间相互干扰,它们可以对跨线程共享数据进行“读-改-写”操作(例如,读取当前值,增大它的值,然后写入新的值)。在GPU这样的高并发执行环境中,保证“读-改-写”操作的完整性尤为重要。CUDA提供了在32位或64位全局内存或共享内存上执行“读-改-写”操作的原子函数。
所有计算能力位1.1或以上的设备都支持原子操作,Kepler型全局原子内存操作比Fermi型操作更快,吞吐量也显著提高了。这可能会使之前因高度依赖原子操作而被认为不适合GPU执行的CUDA型应用能够有好的性能表现。
与标准函数和内部函数类似,每个原子函数都能实现一个基本的数学运算,如加法、乘法或减法。不同于目前介绍过的其他指令类型,当原子操作指令在两个竞争线程共享的内存空间进行操作时,会有一个定义好的行为。可以用下面这个核函数来帮助理解这个概念:
__global__ void incr(int *ptr){
int temp = *ptr;
temp = temp + 1;
*ptr = temp;
}
这个核函数从一个内存位置上读取一个数据,同时将其值加一,然后将得到的值写回到相同位置。注意,这里没有使用线程ID来改变正在被访问的内存位置,内核启动时每个线程都会从相同地址读写。如果启用一个含32个线程的线程块来运行这个核函数,那么会得到什么样的输出?事实是,结果是不确定的。这是因为不止一个线程对同一内存位置进行写操作,这叫做数据竞争,或者称为对内存的不安全访问。数据竞争的定义是两个或多个独立的正在执行的线程访问同一个地址,并且至少其中一个访问会修改该地址。直到程序真正被执行时,才能知道在这个过程中哪一个线程赢得了胜利。因此,对于这个例子或任何会发生数据竞争的应用程序来说,其结果是不能事先确定的。
幸好,使用原子操作指令可以避免这种事情的发生。原子操作指令是通过CUDA API访问的函数,例如:int atomicAdd(int *M, int V);大多数的原子函数是二进制函数,能够在两个操作数上进行操作。它们把一个内存位置M和一个数值V作为输入。与原子函数相关的操作在V上执行,数值V早已存储在内存地址*M中了,然后将运算结果写道同样的内存位置中。
原子运算函数分为3种:算术运算函数、按位运算函数和替换函数。原子算术函数在目标内存位置上执行简单的算术运算,包括加、减、最大、最小、自增和自减等操作。原子替换函数可以用一个新值来替换内存位置上原有的值,它可以是有条件的也可以是无条件的。不管替换是否成功,原子替换函数总是会返回最初存储在目标位置上的值。atomicExch可以无条件地替换已有的值。如果当前存储的值与由GPU线程调用指定的值相同,那么atomiCAS可以有条件的替换已有的值。如下所示,回调前面的自增核函数:
__global__ void incr(int *ptr){
int temp = *ptr;
temp = temp + 1;
*ptr = temp;
}
可以使用atomicAdd函数来重写自增内核程序。atomicAdd在原子级使数值V与存储在内存位置M中的数值相加。更新后的自增内核使用以下语句来增大存储在地址ptr上的数值1,并在增大之前返回存储在ptr上的数值。
__global__ void incr(__global__ int *ptr){
int temp = atomiAdd(ptr,1);
}
随着这些变化的发生,此内核的行为已经有了明确的定义。如果启动32个线程,存储在*ptr所指位置上的值应该是32。另一方面,如果你的应用程序不需要所有线程都成功地增大数值,那么会怎样?如果我们只关心位于同一线程束中的一个或者几个线程能否成功运行呢?观察如下代码:
__global__ void check_threadhold(int *arr, int threshold, int *flag)
{
if(arr[blockIdx.x * blockDim.x + threadIdx.x] > threshold)
{
*flag = 1;
}
}
这里,每一个线程都在将数值与阈值进行比较。如果该值在阈值以上,则设置全局标志。假设所有的线程都在同一个全局标志上运行,如果多个数值在阈值之上,那么给标志位赋值的操作就是不安全的。可以使用atmicExch来消除这种不安全访问:int atomicExch(int *M, int V);atomicExch无条件地用V替换存储在M的值,并返回原来存储在M中的值。用atomicExch重写check_threshold内核来去除对标志位的不安全访问。
__global__ void check_threadhold(int *arr, int threshold, int *flag)
{
if(arr[blockIdx.x * blockDim.x + threadIdx.x] > threshold)
{
atomicExch(flag,1);
}
}
在这种情况下,如果使用了不安全的访问,仍然可以保证至少有一个线程会成功写入*flag。使用atomicExch实际上并没有修改这个内核的行为。对一个应用程序来说,在check_threshold中简单地使用不安全的访问且能正确执行是有可能的。事实上,使用atomicexch等原子操作可能会显著降低其性能。当使用这种优化时必须非常小心,因为这种运算并不依赖于每个线程可见的运算结果。如果用check_threshold来统计高于阈值地数值数量,那么这种不安全访问将是无效的。
原子操作指令在高并行运行环境如GPU中是很强大的。它们提供了一种安全地方法来操作被成百上千个线程所共享地数据。虽然原子函数没有精确度上的顾虑(而内部函数需要考虑精确度),但是他们的使用可能会严重降低性能。

















 7196
7196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









