






前言:作为一款强大的本地运行大型语言模型(LLMs)的框架,Ollama 为开发者、数据科学家和技术用户提供了更大的控制权和灵活性。本文介绍 Ollama 的环境变量设置,常用 CLI 命令及其运行示例。环境变量用于配置 Ollama 的运行环境和行为,CLI 命令用于与本地大模型的交互和管理。
本文为 Ollama 系列的第二篇文章。上一篇文章对 Ollama 的特性、应用场景和安装步骤进行了介绍:大模型本地部署开源框架 Ollama 介绍。
环境变量设置
环境变量用于配置 Ollama 的运行环境和行为,以下是一些常见的环境变量及其用途:
网络配置
- OLLAMA_HOST:定义 Ollama 服务器的协议和主机地址。默认为
127.0.0.1:11434,仅本机地址可通过 11434 端口访问该服务。可以通过此变量自定义 Ollama 服务的监听地址和端口,例如设置为0.0.0.0:8080,可允许其他电脑访问 Ollama(如:局域网中的其他电脑)。默认使用 http 协议。若要使用 https 协议,可设置为:https://0.0.0.0:443 - OLLAMA_ORIGINS:配置允许跨域请求的来源列表。默认包含
localhost、127.0.0.1、0.0.0.0等本地地址以及一些特定协议的来源。通过设置此变量,可以指定哪些来源可以访问 Ollama 服务,例如OLLAMA_ORIGINS=*,https://example.com允许所有来源以及https://example.com的跨域请求。
模型管理
- OLLAMA_MODELS:指定模型文件的存储路径。默认为用户主目录下的
.ollama/models文件夹。通过设置此变量,可以自定义模型文件的存储位置,例如OLLAMA_MODELS=/path/to/models将模型存储在指定的路径下。 - OLLAMA_KEEP_ALIVE:控制模型在内存中的存活时间。默认为 5 分钟。负值表示无限存活,0 表示不保持模型在内存中。此变量用于优化模型加载和运行的性能,例如
OLLAMA_KEEP_ALIVE=30m可以让模型在内存中保持 30 分钟。 - OLLAMA_LOAD_TIMEOUT:设置模型加载过程中的超时时间。默认为 5 分钟。0 或负值表示无限超时。此变量用于防止模型加载过程过长导致服务无响应,例如
OLLAMA_LOAD_TIMEOUT=10m可以将超时时间设置为 10 分钟。 - OLLAMA_MAX_LOADED_MODELS:限制同时加载的模型数量。默认为 0,表示不限制。此变量用于合理分配系统资源,避免过多模型同时加载导致资源不足,例如
OLLAMA_MAX_LOADED_MODELS=4可以限制同时加载 4 个模型。 - OLLAMA_MAX_QUEUE:设置请求队列的最大长度。默认为 512。此变量用于控制并发请求的数量,避免过多请求同时处理导致服务过载,例如
OLLAMA_MAX_QUEUE=1024可以将队列长度设置为 1024。 - OLLAMA_MAX_VRAM:设置 GPU 显存的最大使用量(以字节为单位)。默认为 0,表示不限制。此变量用于控制 GPU 资源的使用,避免显存不足导致的问题,例如
OLLAMA_MAX_VRAM=8589934592可以将显存限制为 8GB。 - OLLAMA_GPU_OVERHEAD:为每个 GPU 预留的显存(以字节为单位)。默认为 0。此变量用于确保每个 GPU 有一定的显存余量,避免显存不足导致的问题,例如
OLLAMA_GPU_OVERHEAD=1073741824可以为每个 GPU 预留 1GB 的显存。
性能与调度
- OLLAMA_NUM_PARALLEL:设置同时处理的并行请求数量。默认为 0,表示不限制。此变量用于优化服务的并发处理能力,例如
OLLAMA_NUM_PARALLEL=8可以同时处理 8 个并行请求。 - OLLAMA_SCHED_SPREAD:允许模型跨所有 GPU 进行调度。默认为
false。启用此变量可以提高模型运行的灵活性和资源利用率,例如OLLAMA_SCHED_SPREAD=1可以启用跨 GPU 调度。
调试与日志
- OLLAMA_DEBUG:启用额外的调试信息。默认为
false。开启此变量可以获取更多的调试日志,帮助排查问题,例如OLLAMA_DEBUG=1可以启用调试模式。 - OLLAMA_NOHISTORY:禁用 readline 历史记录。默认为
false。启用此变量可以避免保存命令历史记录,例如OLLAMA_NOHISTORY=1可以禁用历史记录。 - OLLAMA_NOPRUNE:在启动时不清理模型文件。默认为
false。启用此变量可以保留所有模型文件,避免不必要的清理操作,例如OLLAMA_NOPRUNE=1可以禁用模型文件的清理。
特性开关
- OLLAMA_FLASH_ATTENTION:启用实验性的 Flash Attention 特性。默认为
false。此变量用于测试和使用新的注意力机制特性,例如OLLAMA_FLASH_ATTENTION=1可以启用 Flash Attention。 - OLLAMA_MULTIUSER_CACHE:为多用户场景优化提示缓存。默认为
false。启用此变量可以提高多用户环境下的缓存效率,例如OLLAMA_MULTIUSER_CACHE=1可以启用多用户缓存优化。
代理设置
- HTTP_PROXY:设置 HTTP 代理服务器地址。此变量用于配置 Ollama 在进行 HTTP 请求时使用的代理服务器,例如
HTTP_PROXY=http://proxy.example.com:8080可以让 Ollama 使用指定的 HTTP 代理。 - HTTPS_PROXY:设置 HTTPS 代理服务器地址。此变量用于配置 Ollama 在进行 HTTPS 请求时使用的代理服务器,例如
HTTPS_PROXY=https://proxy.example.com:8080可以让 Ollama 使用指定的 HTTPS 代理。 - NO_PROXY:设置不使用代理的地址列表。此变量用于指定哪些地址在进行请求时不使用代理,例如
NO_PROXY=localhost,example.com可以让 Ollama 在访问localhost和example.com时不使用代理.
Ollama 还提供了与硬件、底层库相关的环境变量,详情可查看 Ollama 源码。
CLI 命令
Ollama 常用的 CLI 命令见下表:
| 命令 | 用途 |
| ollama serve | 在本地系统上启动 Ollama。 |
| ollama create <new_model> | 从现有模型创建一个新模型,用于定制或训练。 |
| ollama show <model> | 显示特定模型的详细信息,例如其配置和发布日期。 |
| ollama run <model> | 运行指定的模型,使其准备好进行交互。 |
| ollama pull <model> | 将指定的模型下载到您的系统。 |
| ollama list | 列出所有已下载的模型。 |
| ollama ps | 显示当前正在运行的模型。 |
| ollama stop <model> | 停止指定的正在运行的模型。 |
| ollama rm <model> | 从您的系统中移除指定的模型。 |
在终端,输入上面的命令 + '-h',可查看具体命令的帮助文档(如,ollama show -h, 可查看 show 命令的帮助文档)。下面列出每个命令的具体用法和示例。
启动 Ollama
在本地系统上启动 Ollama:ollama server
PS C:\Windows\system32> ollama serve -h
Start ollama
Usage:
ollama serve [flags]
Aliases:
serve, start
Flags:
-h, --help help for serve
Environment Variables:
OLLAMA_DEBUG Show additional debug information (e.g. OLLAMA_DEBUG=1)
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
OLLAMA_KEEP_ALIVE The duration that models stay loaded in memory (default "5m")
OLLAMA_MAX_LOADED_MODELS Maximum number of loaded models per GPU
OLLAMA_MAX_QUEUE Maximum number of queued requests
OLLAMA_MODELS The path to the models directory
OLLAMA_NUM_PARALLEL Maximum number of parallel requests
OLLAMA_NOPRUNE Do not prune model blobs on startup
OLLAMA_ORIGINS A comma separated list of allowed origins
OLLAMA_SCHED_SPREAD Always schedule model across all GPUs
OLLAMA_FLASH_ATTENTION Enabled flash attention
OLLAMA_KV_CACHE_TYPE Quantization type for the K/V cache (default: f16)
OLLAMA_LLM_LIBRARY Set LLM library to bypass autodetection
OLLAMA_GPU_OVERHEAD Reserve a portion of VRAM per GPU (bytes)
OLLAMA_LOAD_TIMEOUT How long to allow model loads to stall before giving up (default "5m")模型管理
1. 列出所有已下载的模型。
PS C:\Windows\system32> ollama list -h
List models
Usage:
ollama list [flags]
Aliases:
list, ls
Flags:
-h, --help help for list
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
2. 查看某个模型的详细信息
PS C:\Windows\system32> ollama show -h
Show information for a model
Usage:
ollama show MODEL [flags]
Flags:
-h, --help help for show
--license Show license of a model
--modelfile Show Modelfile of a model
--parameters Show parameters of a model
--system Show system message of a model
--template Show template of a model
Environment Variables:
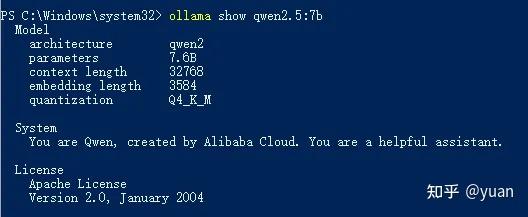
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)如下图,可查看大模型的参数数量、上下文长度、嵌入长度等信息:
3. 显示正在运行的大模型
PS C:\Windows\system32> ollama ps -h
List running models
Usage:
ollama ps [flags]
Flags:
-h, --help help for ps
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)![]()
4. 停止指定的正在运行的模型
PS C:\Windows\system32> ollama stop -h
Stop a running model
Usage:
ollama stop MODEL [flags]
Flags:
-h, --help help for stop
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
5. 删除已下载的大模型
PS C:\Windows\system32> ollama rm -h
Remove a model
Usage:
ollama rm MODEL [MODEL...] [flags]
Flags:
-h, --help help for rm
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
6. 下载大模型
PS C:\Windows\system32> ollama pull -h
Pull a model from a registry
Usage:
ollama pull MODEL [flags]
Flags:
-h, --help help for pull
--insecure Use an insecure registry
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)运行大模型
尽管我们可以通过第三方的 Web UI 等方式与基于 Ollama 部署的本地大模型进行交互,但通过 run 命令的方式与大模型交互,具有以下的优点:
- 直接在终端运行 run 命令,可便捷高效地验证本地部署的大模型的响应效果
- 记录保存大模型的响应:可将大模型的响应记录到本地文件。
- 基于 run 命令开发自动化执行的脚本,定时调度执行,实现与大模型交互的自动化工作流程。
run 命令的帮助文档:
PS C:\Windows\system32> ollama run -h
Run a model
Usage:
ollama run MODEL [PROMPT] [flags]
Flags:
--format string Response format (e.g. json)
-h, --help help for run
--insecure Use an insecure registry
--keepalive string Duration to keep a model loaded (e.g. 5m)
--nowordwrap Don't wrap words to the next line automatically
--verbose Show timings for response
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
OLLAMA_NOHISTORY Do not preserve readline history下面是使用 run 的例子。
ollama run <model> [PROMPT]
PS C:\Windows\system32> ollama run qwen2.5:7b "请介绍一下机器学习"
当然,我很乐意为您介绍机器学习。
机器学习是一种人工智能技术,它使计算机能够在不进行明确编程的情况下从数据中学习。简单来说,就是让机器通过学习数据来识
别模式、做出决策,并能够随着时间的推移改善其性能。
### 1. 基本概念
- **训练集和测试集**:在机器学习中,通常会将数据分为训练集(用来训练模型)和测试集(用来验证模型的效果)。
- **特征**:这些是用于描述数据的数据点。例如,在预测房价的模型中,房屋面积、卧室数量等可以作为特征。
### 2. 算法类型
机器学习算法主要可分为三类:
1. **监督学习**:在这种方法中,训练数据被标记,并且目标是对新数据进行预测或分类。
- 例如:通过已标注的电子邮件(垃圾邮件/非垃圾邮件)来构建一个自动过滤垃圾邮件的系统。
2. **无监督学习**:在没有标记的数据的情况下进行分析和模式识别。通常用于探索性数据分析中,如聚类。
- 例如:根据用户购买行为将顾客分组,发现潜在的目标市场。
3. **强化学习**:该方法让机器通过与环境交互来学习最佳行动策略。
- 例如:AlphaGo使用强化学习打败了世界围棋冠军李世石。
### 3. 应用领域
- **自然语言处理**:如情感分析、文本摘要等;
- **计算机视觉**:如图像识别、物体检测等;
- **推荐系统**:如根据用户历史行为推荐商品或内容;
- **医疗健康**:如疾病诊断预测模型;
- **金融风控**:风险评估与管理。
### 4. 技术栈
进行机器学习项目通常需要以下技能和工具:
- **编程语言**:Python是最常用的语言,因为它有丰富的库支持。
- **数据处理**:如Pandas、NumPy等包用于数据清洗和预处理。
- **模型构建与训练**:Scikit-learn, TensorFlow, PyTorch等库提供了大量的机器学习算法实现。
- **可视化工具**:Matplotlib, Seaborn, Plotly等帮助理解和展示结果。
### 5. 挑战
尽管机器学习带来了许多机遇,但也面临着挑战:
- 数据隐私和安全问题;
- 缺乏高质量的数据集会影响模型的准确性;
- 解释性问题(即对模型决策过程的理解);
- 过度拟合或欠拟合现象。
总之,机器学习是当今世界最激动人心的技术之一。随着数据量的增长以及算法的进步,它将在更多领域发挥重要作用。可将大模型的响应结果,保存到本地文件:ollama run <model> [PROMPT] > output.txt
如,ollama run qwen2.5:7b "若要系统的学习金融知识,有哪些途径?" > fin_learning_advice.txt,可将大模型响应结果保存到 fin_learning_advice.txt。
ollama run qwen2.5:7b "若要系统的学习金融知识,有哪些途径?" > fin_learning_advice.txt可使用 run 命令,对一个文本文件的内容进行总结:
选取了 Ollama 的一段代码:https://github.com/ollama/ollama/blob/main/server/prompt.go,使用 qwen2.5-coder:7b 总结该段代码的内容。
PS D:\llm_learning> Get-Content "prompt.go" | ollama run qwen2.5-coder:7b "请总结一下这段代码的内容。"
这段代码定义了一个用于处理聊天消息的函数 `chatPrompt`,该函数主要用于生成用于下一个聊天回合的提示和图像数据。以下是
对代码内容的详细总结:
1. **包和导入**:
- 包名为 `server`。
- 导入了多个外部包,包括标准库、第三方库(如 `github.com/ollama/ollama/api`, `github.com/ollama/ollama/llm`,
`github.com/ollama/ollama/model/mllama`, `github.com/ollama/ollama/template` 等)以及一些内部包。
2. **类型和变量**:
- 定义了一个 `tokenizeFunc` 类型,表示一个接受上下文和字符串并返回整数切片和错误的函数。
- 定义了一个全局变量 `errTooManyImages`,表示vision模型不支持每条消息多个图像。
3. **chatPrompt 函数**:
- 该函数接受一个上下文、一个模型实例、一个分词函数、一个选项结构体、一组聊天消息和一组工具。
- 根据模型是否为Mllama家族(通过 `checkMllamaModelFamily` 函数判断),确定图像的编码方式。
- 遍历输入的消息,截取符合条件的消息并构建提示字符串。
- 处理图像数据,并将其添加到返回的图像列表中。
4. **checkMllamaModelFamily 函数**:
- 该函数检查模型配置中的 `ModelFamilies` 是否包含 "mllama",以确定模型是否为Mllama家族。
5. **错误处理**:
- 函数中包含了多个错误处理逻辑,例如当消息包含多个图像时返回 `errTooManyImages`。
- 使用 `slog.Debug` 记录调试信息。
总结来说,这段代码的主要功能是根据输入的聊天消息和模型配置,生成用于下一个聊天回合的提示字符串和图像数据。它处理了消
息的截取、分词、图像编码和错误处理等步骤。本文介绍了 Ollama 的环境变量设置与常用CLI 命令,本地运行大模型的有趣示例。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 3610
3610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









