






Gork 3 发布不到一周, DeepSeek 仍然在“开源周”的时间, Anthropic 平台空降推出首个双思维大模型——Claude 3.7 Sonnet,将模型行业的“狂卷时代”推到一个新高度。

目录
1.Claude 3.7 Sonnet 测试
2.Claude 3.7 Sonnet 相关介绍
2.1 双思维模型
2.2 API 定价
3.模型行业现状
3.1 模型功能能力提升
3.2 垂直领域明显
4.模型评测的重要性
4.1 置信的评测榜单
4.2 高难度评测集
4.1 创新的评测模式
01.Claude 3.7 Sonnet 测试
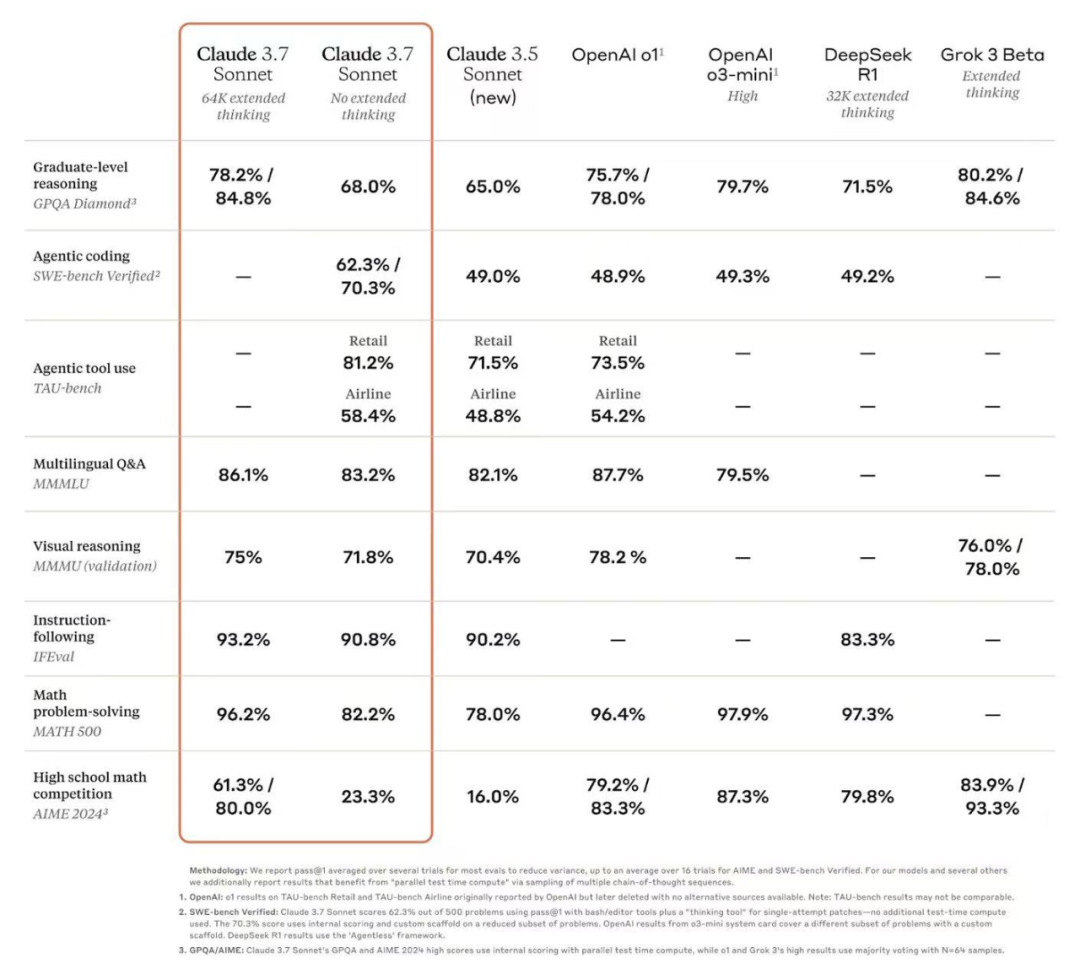
前日凌晨 2 点 Anthropic 放出大招,推出 Claude 3.7 Sonnet 及 Claude Code。Claude 产品的主管 Alex Albert 称 Claude 3.7 Sonnet 是“迄今为止最智能的模型”,业内也充满了好奇,但是不是最智能还需要实际测试,基于以下实测场景看看 Claude 3.7 Sonnet 的完成度如何。
测试1:基于赫尔曼·梅尔维尔的故事《巴特比,抄写员》创作一款具有独特机制的视频游戏

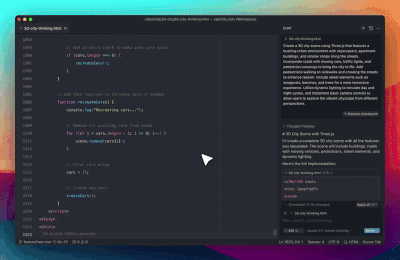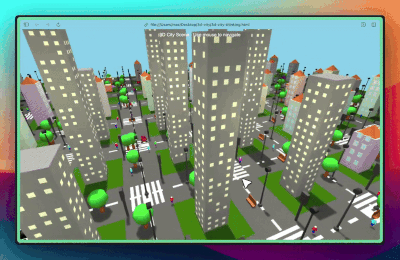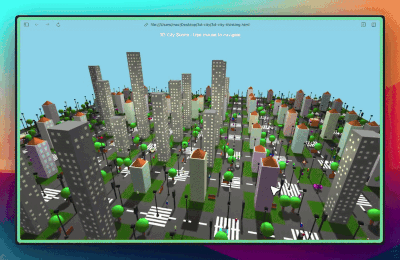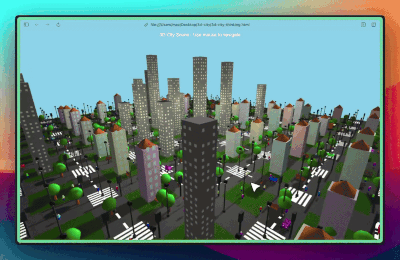
测试2:创建一个 3D 城市场景
测试3:一个三角球在十二边形内弹跳,每次弹跳时球都会改变颜色,背景是太空
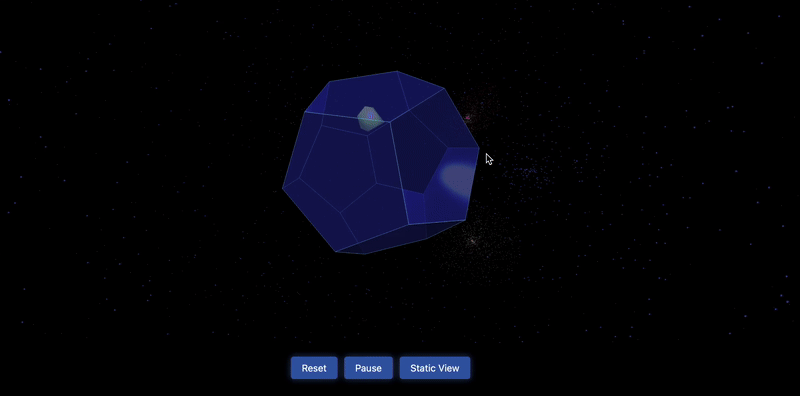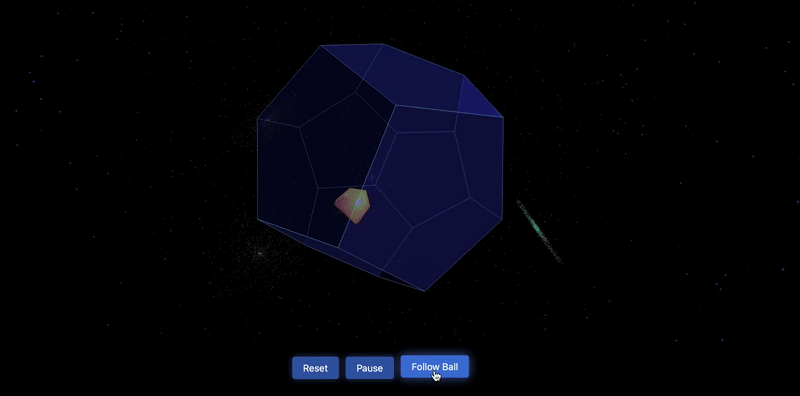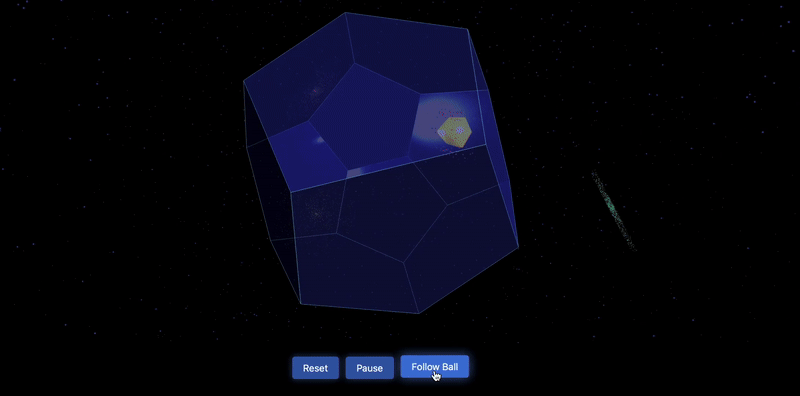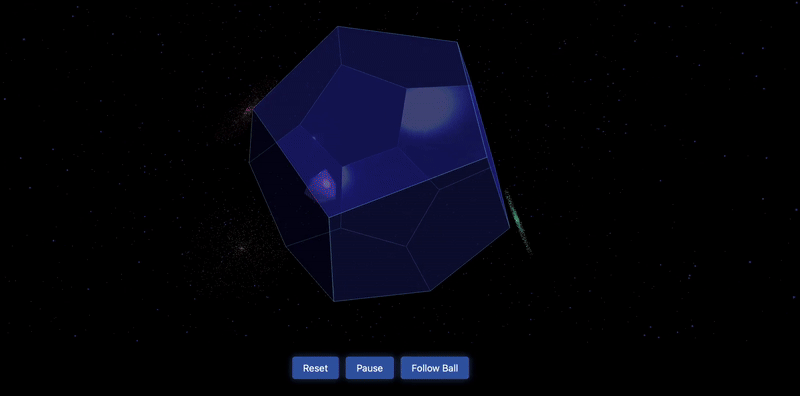
测试4:多米诺骨牌效应
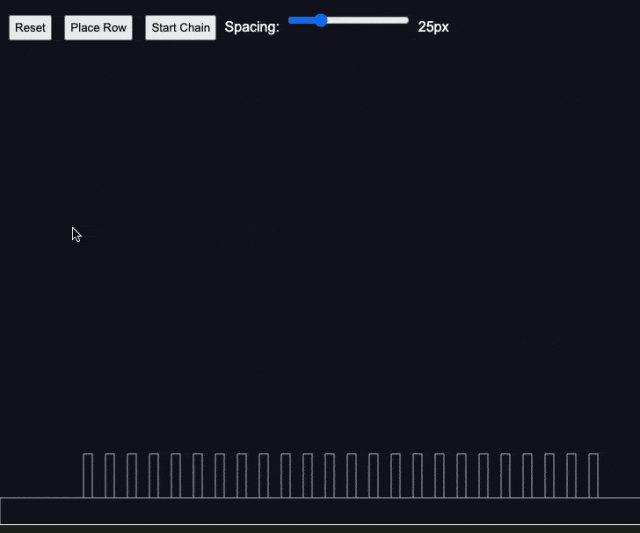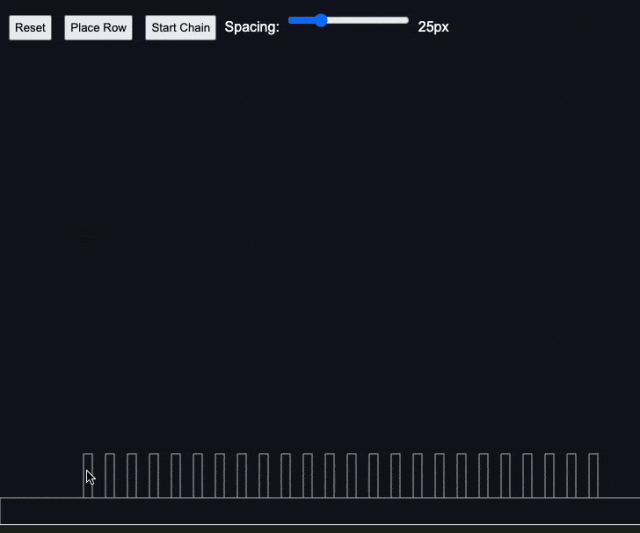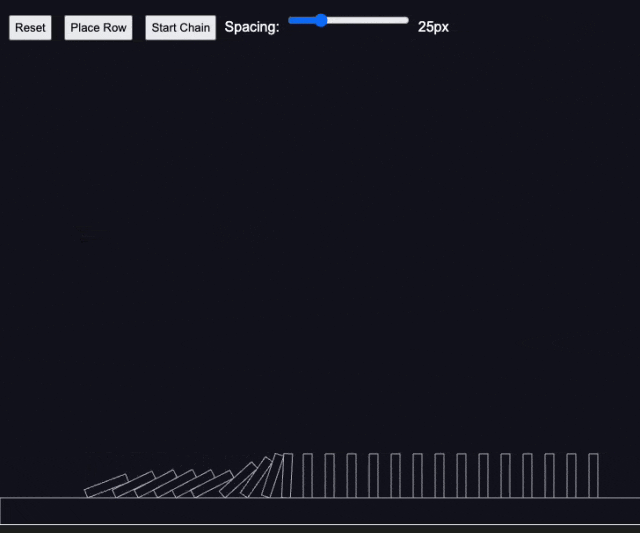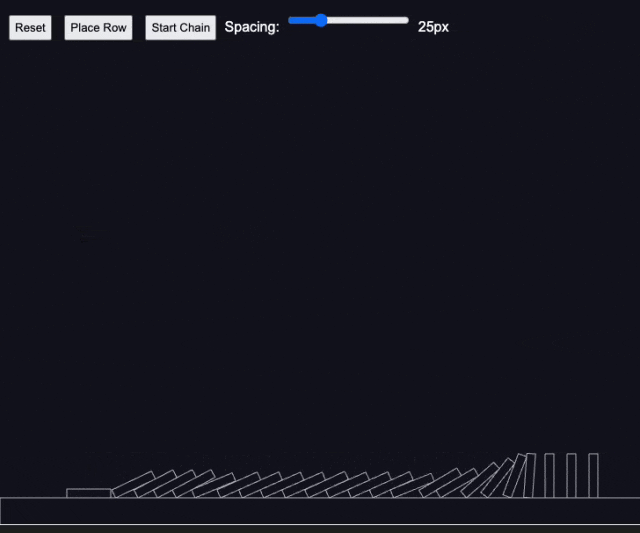
国外资深 AI 媒体人 Rowan Cheung 在测试后也惊叹 Claude 3.7 Sonnet 的编程能力。
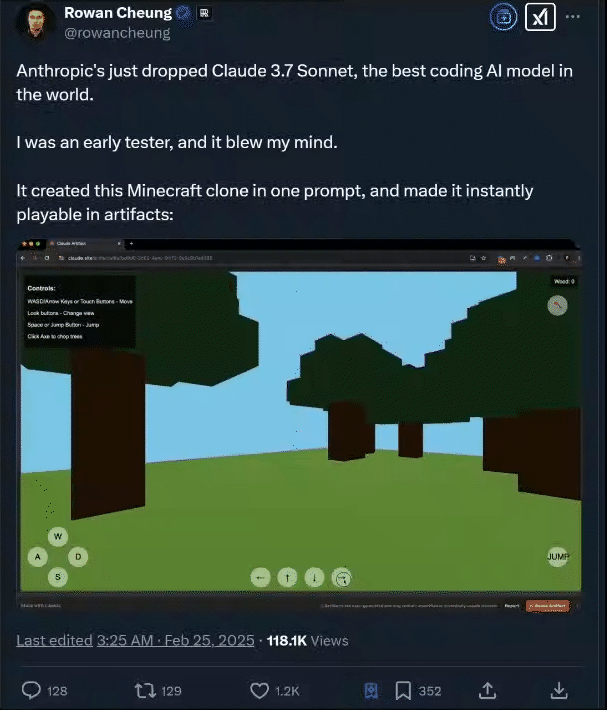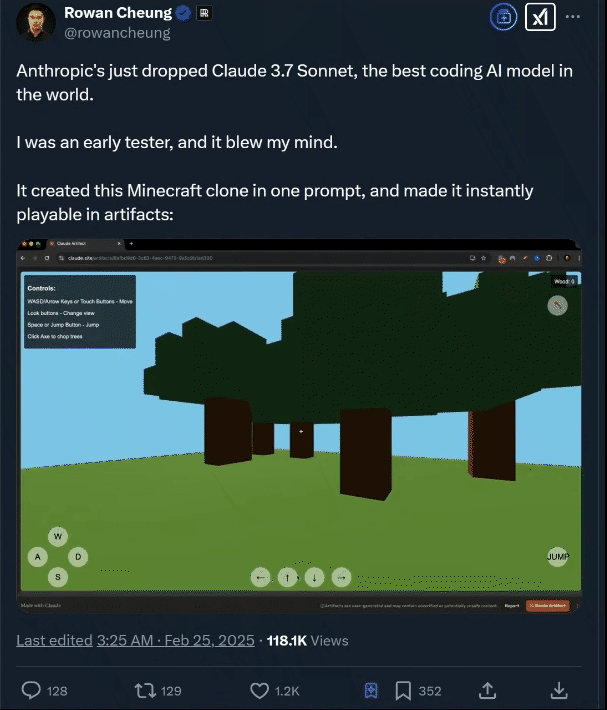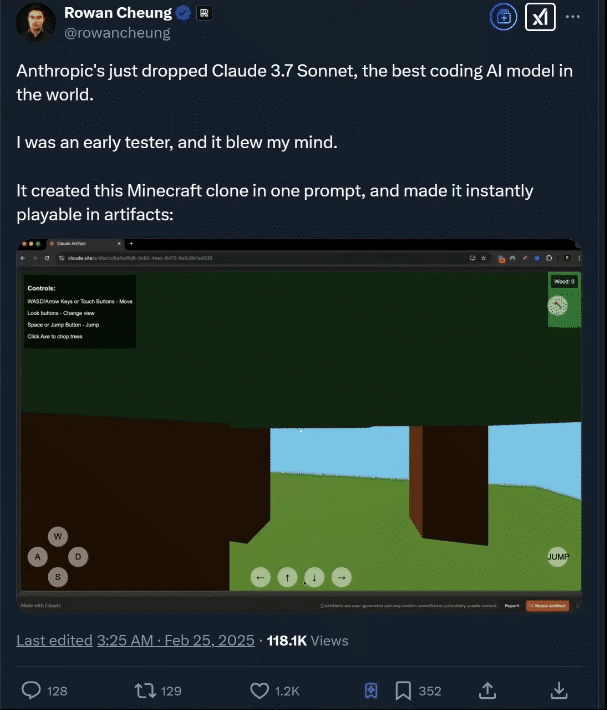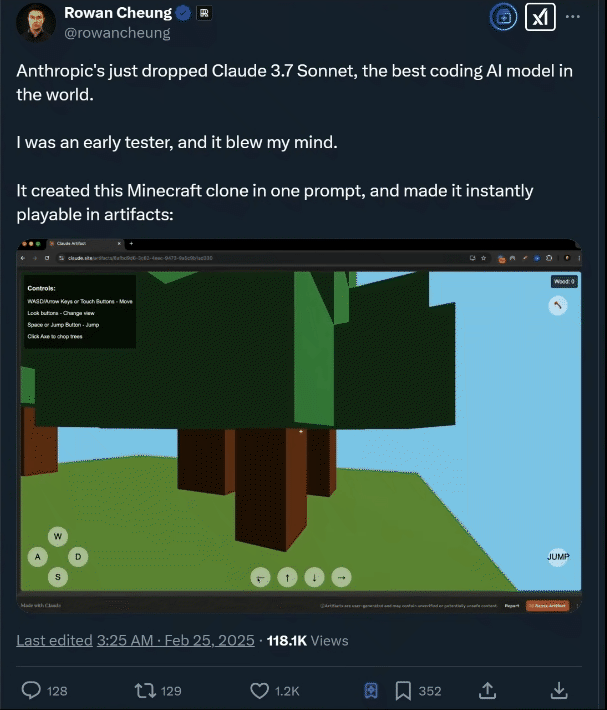
02.Claude 3.7 Sonnet 介绍
虽然 Claude 3.7 Sonnet 在编程代码的实测表现确实亮眼,但大家更关注 Alex Albert 提到的第二个信息点“ Claude 3.7 Sonnet 是世界上第一个普遍可用的混合推理模型”,类似于将 Deepseek 的“ V3 版本 ”和“ R1版本”结合到一起的模型。如果说 DeepSeek R1 代表着专家混合(MoE)架构模型的成功,那么Claude 3.7 Sonnet 代表着另外一种新的技术架构在模型训练上取得更大的收益。
2.1 双思维模型
Claude 3.7 Sonnet 支持双重输出模式,即支持标准输出模式以及深度推理模式。基于这样的双思维模式,在实际应用中,用户可以自由选择是让 Claude 3.7 Sonnet 快速作答,还是让其进行更长时间的深度思考。在标准模式下,它是 Claude 3.5 Sonnet 的升级版;切换到扩展思考( Extended Thinking )模式(可简单理解为推理),它会在回答前进行自我反思,大幅提升在数学、物理、指令理解和编程等复杂任务上的表现。
扩展思考模式显著提升了 Claude 3.7 Sonnet 的性能表现主要为5点
-
复杂数学问题准确率大幅提高
-
逻辑推理和分析任务能力显著增强
-
推理过程更加详尽透明,提升用户信任度
-
为开发者提供模型优化的重要依据
-
增强模型安全性,便于监控和干预潜在风险
在这样的双思维模式下,模型表现如何,也有网友做了实测
prompt:设xxx 和yyy是正整数,满足x2+y2=2025x^2+y^2= 2025x2+y2=2025。求 xxx 和 yyy 的所有可能值。
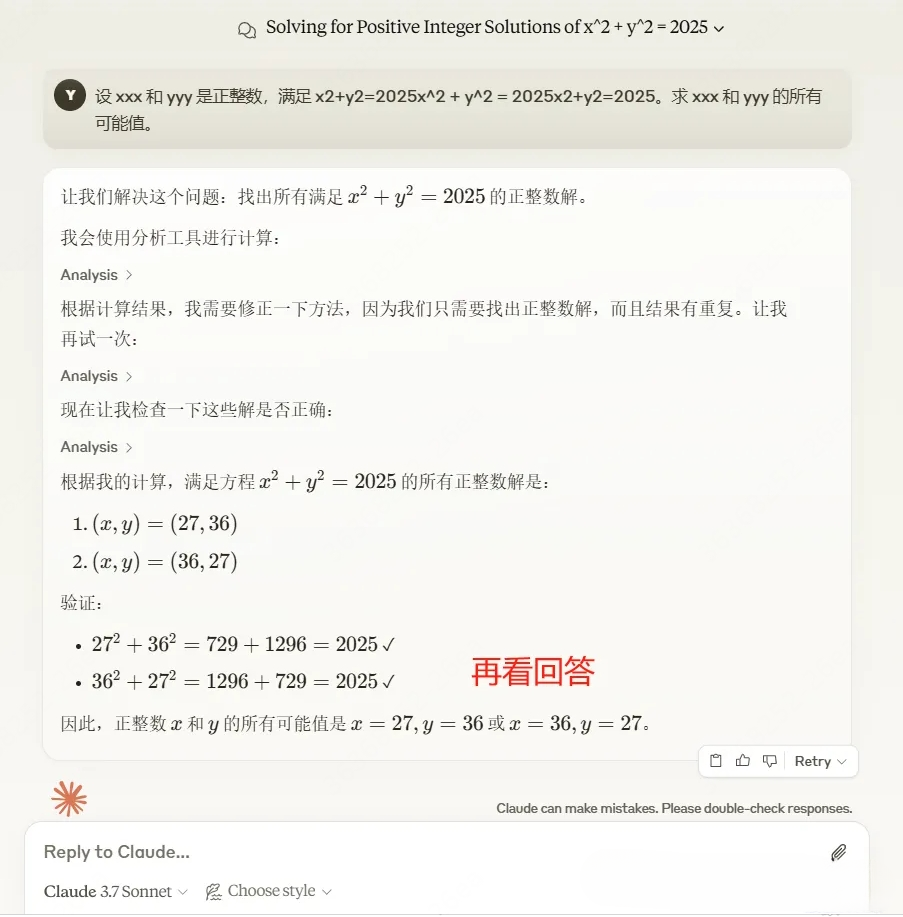
第一个问题 Claude 3.7 Sonnet 回答对了,接下来就是它的写作能力。

但它本次给的仿写结果就不太好,出现了幻觉,胡诌了“2025年2月24日马云亲自宣布通义千问 5.0 全面开源”

与 GPT-4o 的仿写结果对比,仍有相当大的差距
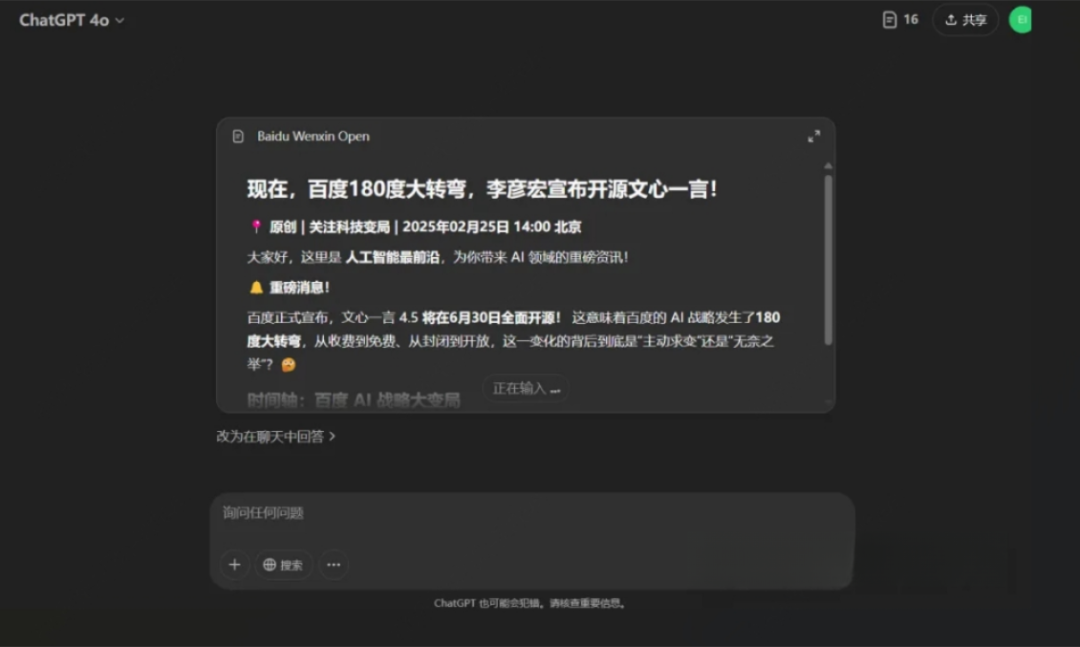
注:该测试内容来自公众号G人工智能
在 Claude 3.7 Sonnet 的双思维模式下,文本创造能力还是存在缺陷,模型的多维度的能力考察仍需要更全面的评测集进行测试,我们也一直在探索更全面更专业的评测集。
关注我们可以及时获取更多评测相关内容和资讯。
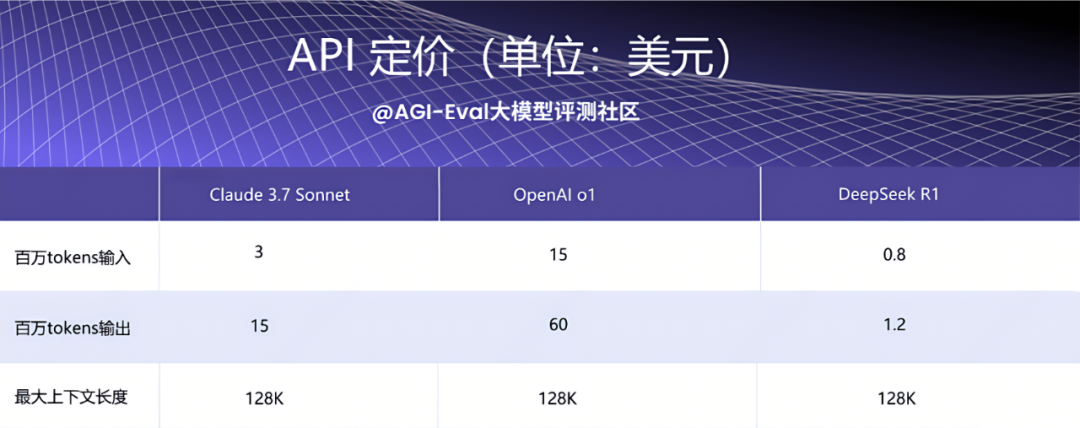
2.2 API 定价
目前 Claude 3.7 Sonnet 已经正式上线了,免费用户和付费用户都可以使用。但是免费用户不能使用深度思考模式而付费用户可以,API 的定价上相对也比较合理。性价比如何还需要结合模型表现,后期我们也会根据平台的能力榜单及各厂商的 API 定价,对各模型的性价比排名做一次深度解析。
03.模型行业现状
当然,Claude 3.7 Sonnet 的出现进一步加速了当前大模型的开发节奏,从 DeepSeek-R1 到 Open AI 发布的 L3级智能体「Operator」,模型探索越来越深,截止到 2 月 27 日已经有 20+ 的模型进行了迭代更新,且每个模型迭代的产品性能都显著的提升,细分方向也愈发明显, 2025 年的大模型“狂卷时代”全面升级, AI 开发技术愈加成熟,产品能力也愈发显著。
3.1 模型功能能力提升
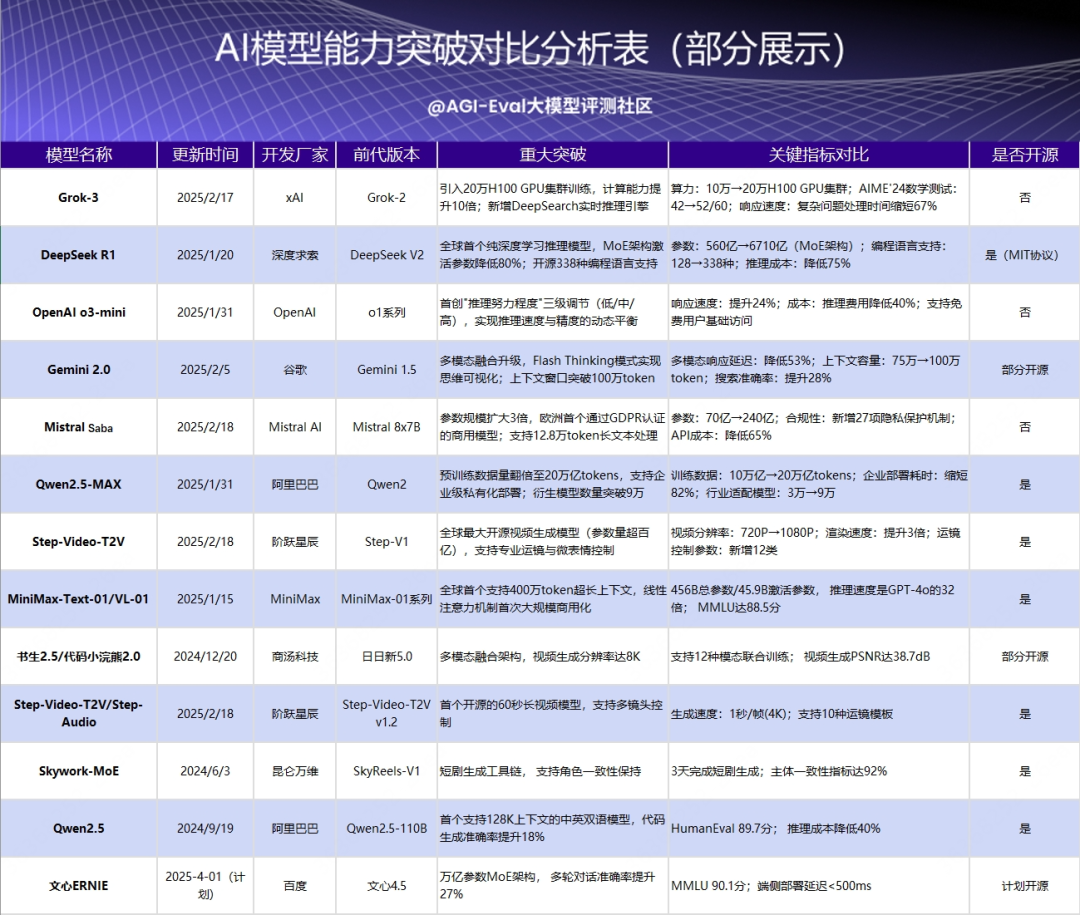
可以看到越来越多的模型厂商选择了开源,大大的推动了技术迭代效率提升,使得研发门槛降低,DeepSeek-R1 作为全球首个 OSI 认证纯开源大模型,通过开放技术路径打破欧美信息垄断,其低成本特性显著降低研发门槛,如河南云飞科技仅投入12 万美元就完成病虫害模型开发。这类开源模式为全球开发者提供创新训练思路,推动 AI 技术迭代效率跃升,加速产业生态发展。
3.2 垂直领域明显
模型厂商也在积极进行商业落地,利用大模型的产品能力在金融、医疗、教育、游戏等不同行业为应用场景赋能。
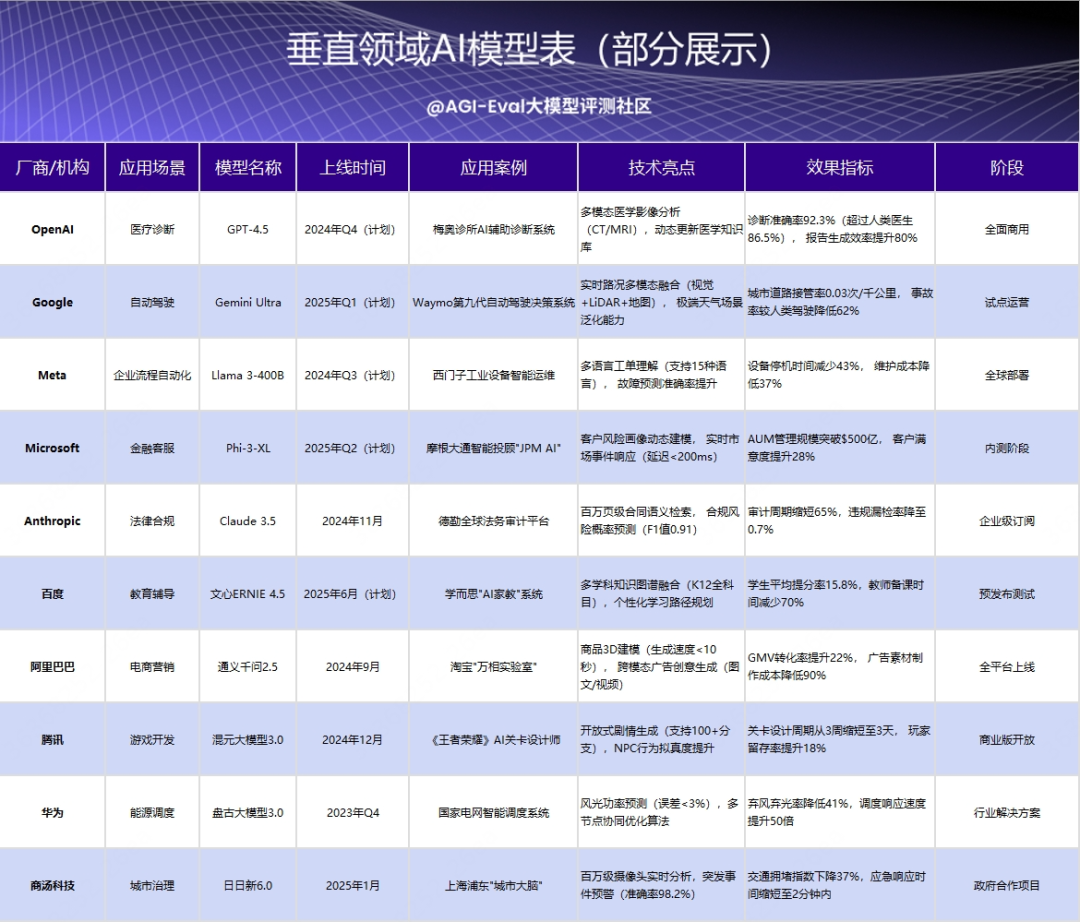
目前大模型开发正加速向垂直领域深度适配,企业倾向选择轻量低成本的专用模型,替代通用大模型二次开发。如北京儿童医院临床病历、ChatLaw 法律案例库案例。还有国内厂商依托政策驱动场景落地,如广西政府征集糖业、新能源汽车等专用垂直模型,推动"人工智能+制造"国家战略与实体经济融合。
04. 模型评测的重要性
模型从能力到领域都在不断加速发展,针对模型能力的评测变得越来越重要, 现在模型发布时都会对外宣称自己模型是最强模型,Gork 3 发布时,马斯克也说 Gork 3 是最强模型。
深层次的问题还是现在业内缺少更客观公正的第三方机构,仅自己公司认证最强的说法,可信度也在打折。许多厂商和公司发版前会用一些公开评测集内部测试,评测集一旦被公开还是存在数据被穿越的可能性,评测结果可能会失真,所以一些技术报告或者宣发报告时都有不一样的数值。
4.1 置信的评测榜单
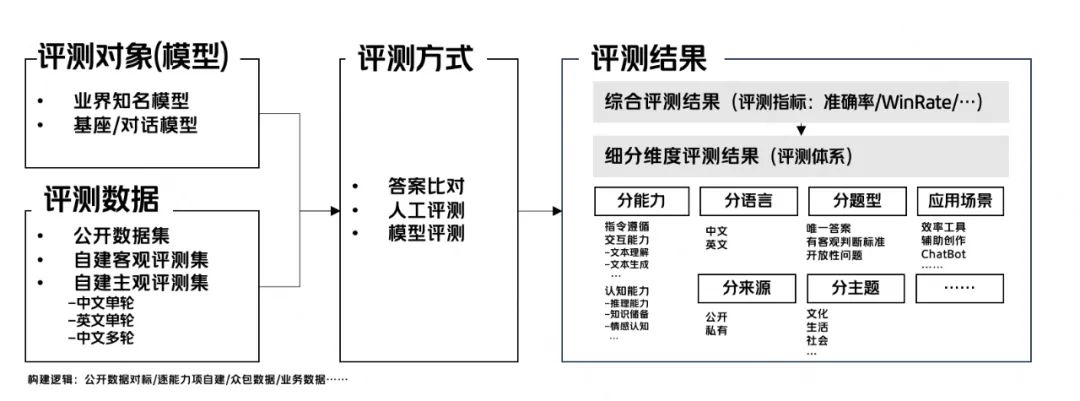
对此,我们平台构建了10W 量级私有数据,防止数据穿越,保证评测的置信度和公正性。

平台也结合各公开评测方案的基础上,自建了涵盖多种评测方式、海量私有化数据集的大语言模型评测方案。同时采用自动+人工评测的方式,评测准确率在 98% 以上,保证评测结果的准确率。最终推出一个全面、准确、科学、公正的评测榜单【https://agi-eval.cn/mvp/topRanking】。
4.2 高难度评测集
随着模型能力的提升,特别是推理系模型的能力攀升,需要更高难度的评测集。我们构建了私有的高难度数据集 Math Pro Bench & OI Bench 。
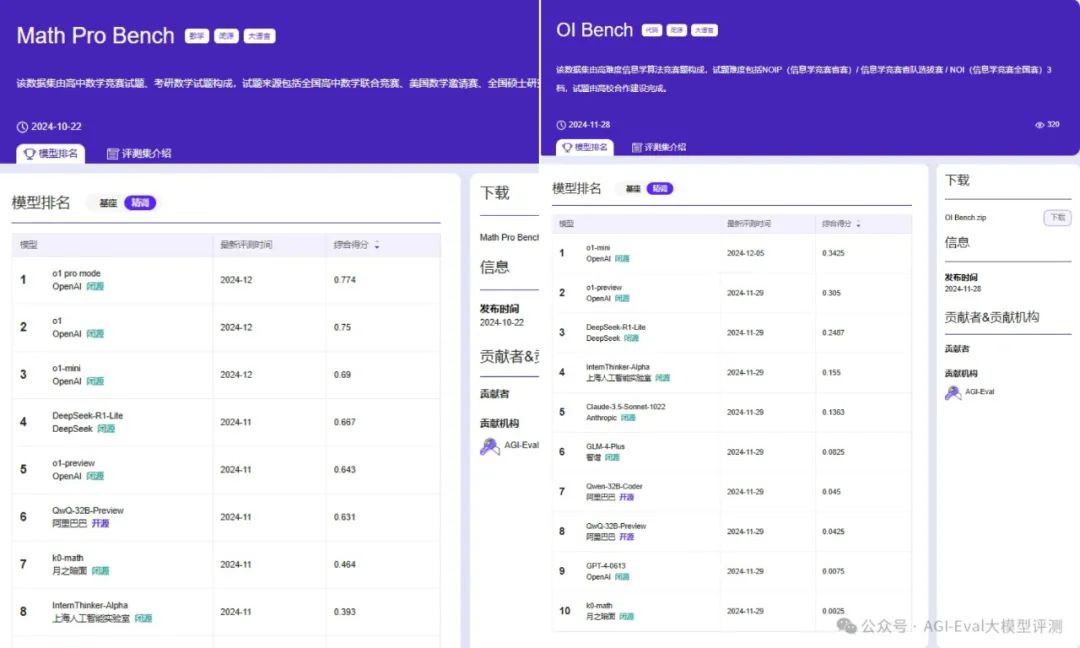
之前也做过高难度评测集能力的测试,欢迎大家查看
AGI-Eval评测社区,公众号:AI科技评论PK OpenAI o1,国产模型在高难度数学和算法竞赛的能力几何?
除高难度的评测集,最近更新了一个包含1500多个多回合任务的大型评测集,【CapaBench】评测集涵盖了多个领域,包括在线购物、导航规划、票务订购、操作系统、机器人控制、数学和定理证明等,可点击官网查看。
详细内容可查看往期内容
AGI-Eval社区,公众号:AGI-Eval大模型评测【AGI-Eval评测数据 NO.2】CapaBench 揭示 LLM 智能体中各个模块的作用
4.3 创新的评测方式
鉴于传统评测方式难以充分反映模型的真实水平,AGI-Eval 创新性地提出了人机协作评测模式【https://agi-eval.cn/llmArena/home】。在这种模式下,参与者可以与最新的大模型共同完成任务,既有助于提高任务完成度又便于建立更加直观的区分度。

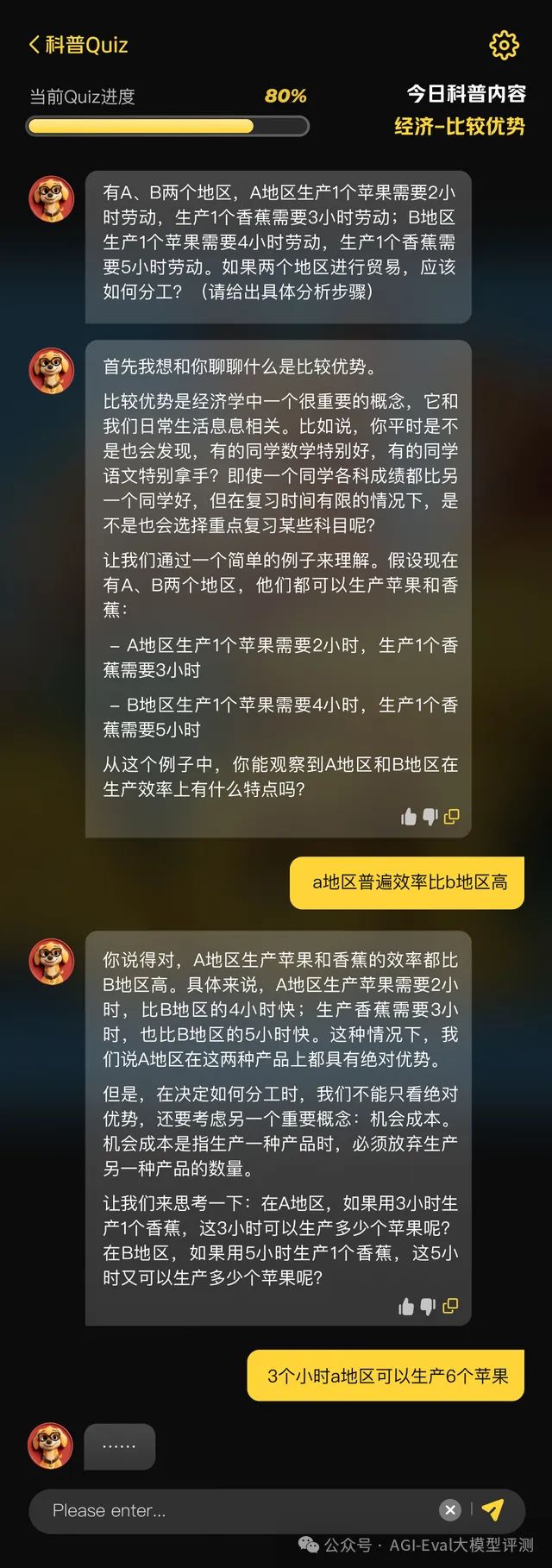
前段时间还推出10分钟Quiz人机产品化评测方案【https://agi-eval.cn/llmArena/mobile/home】,待测模型需要在同一套 System prompt 下指导真实用户学习一个知识点并完成 Quiz,基于模型与用户的高质量多轮对话数据,产出更加高置信度的评测结论。

















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









