






ELMo:将上下文当作特征,但是无监督的语料和我们真实的语料还是有区别的,不一定符合我们特定的任务,是一种双向的特征提取。
OpenAI GPT: 通过transformer decoder学习出来一个语言模型,不是固定的,通过任务 fine-tuning,用transfomer代替ELMo的LSTM。
OpenAI GPT其实就是缺少了encoder的transformer:当然也没了encoder与decoder之间的attention。
OpenAI GPT虽然可以进行fine-tuning,但是有些特殊任务与pre-training输入有出入,单个句子与两个句子不一致的情况,很难解决,还有就是decoder只能看到前面的信息。
GPT适用于生成任务(自回归语言模型,任务更难但潜力更大), BERT适合判别。
GPT1大概1亿参数,BERT-base类似, BERT-large大概3.4亿
类似GPT2大概13亿参数
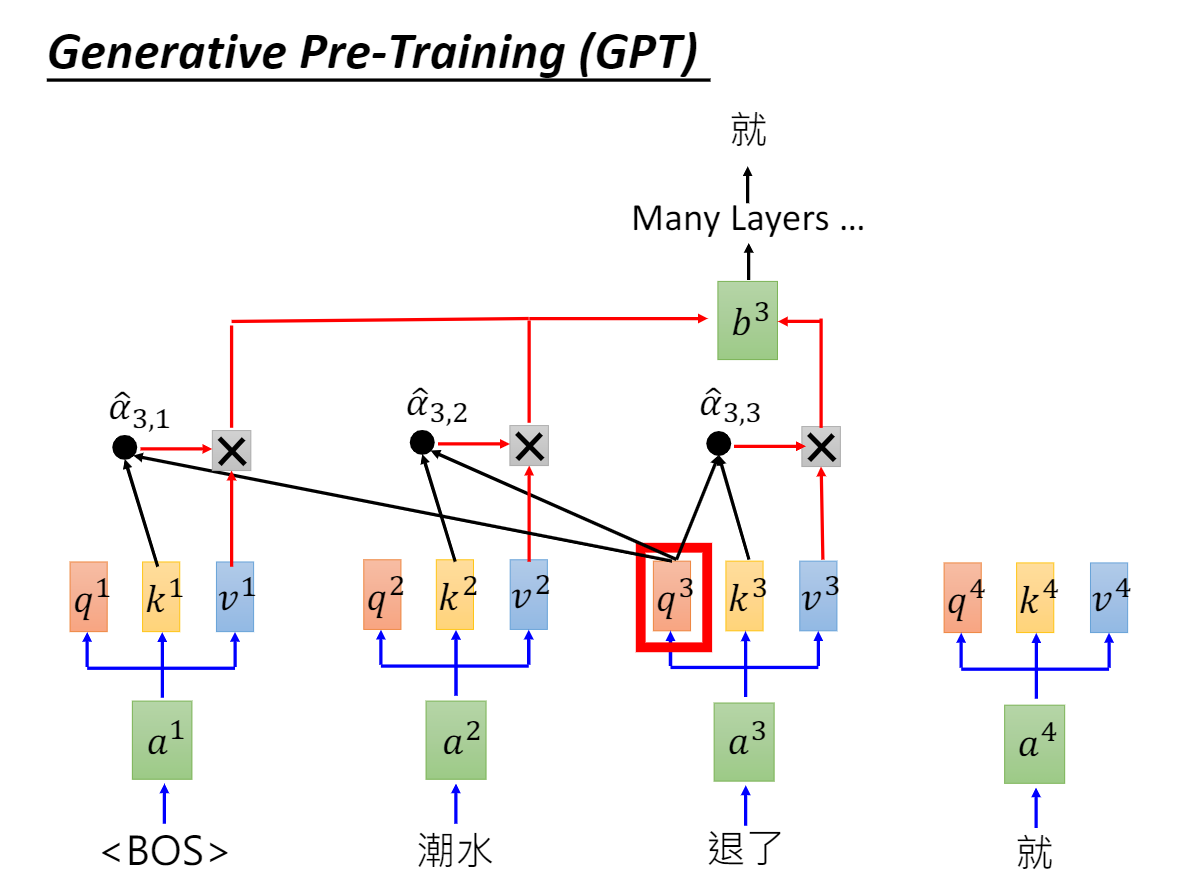
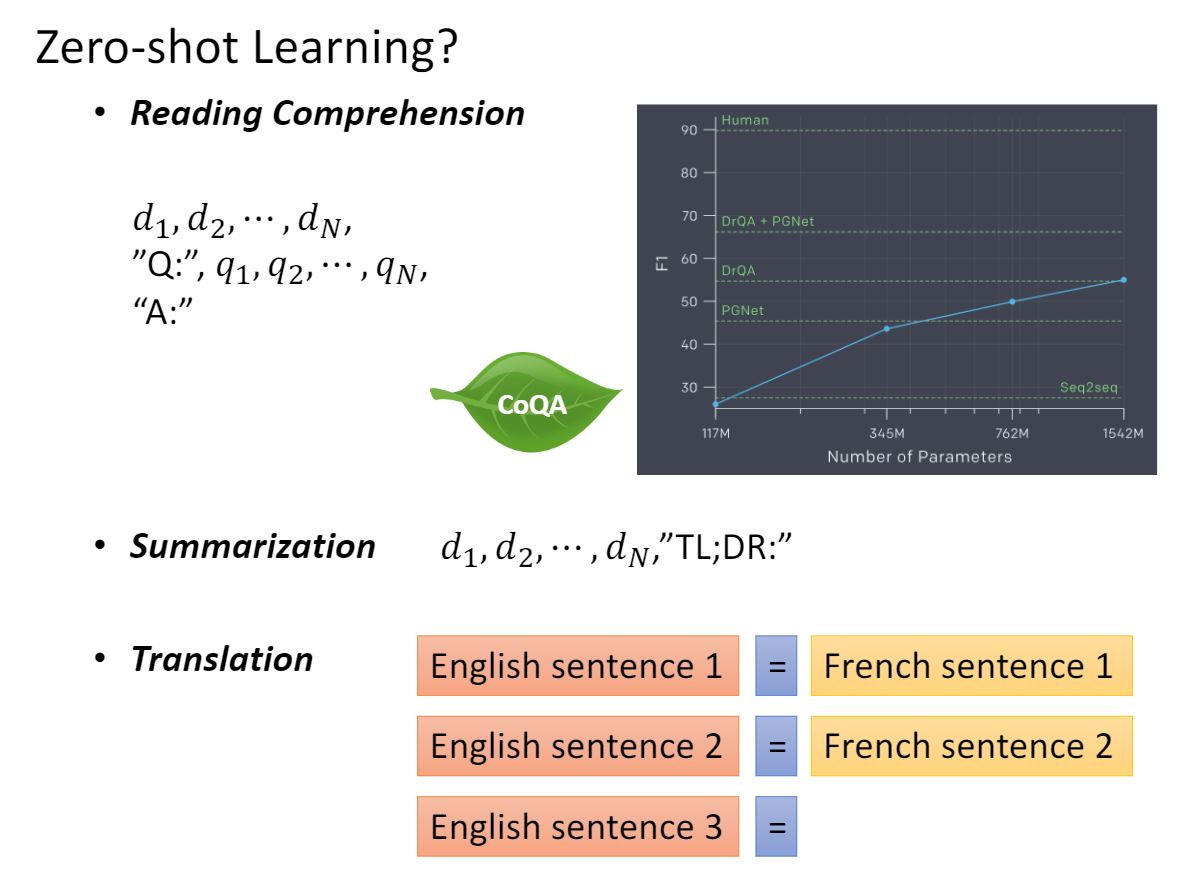

True LM (预训练没有句子级别任务)

有监督微调时:

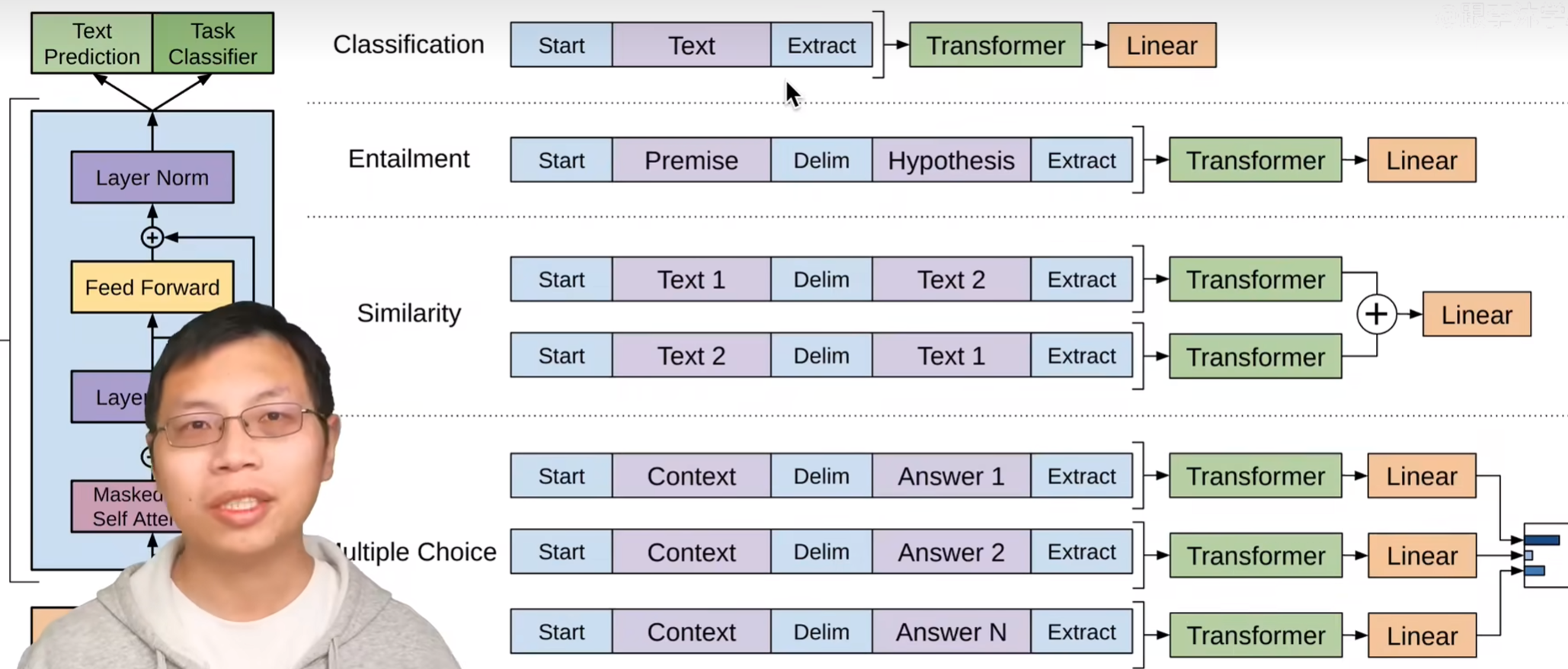
拿Transformer Encoder的输出的最后一个向量,送入前馈网络+Softmax
下游任务损失 + alpha 预训练损失
初始词元, 间隔词元,抽取词元, 构成输入序列,Transformer抽取特征,送入线性层,分类
四个任务
- 分类:句子A
- 蕴含:句子A, 句子B假设, True, False, None, 3分类
- 相似性: Text1,Text2, 相不似相似True/False; 交换顺序Text2,Text1, 相不似相似True/False(单向的,交换顺序不一样,有必要)。抽取特征相加,线性,分类
- 多选择(QA, 摘要): 一个上下文,多个答案, 分别用Transformer编码,多分类
Bert-Base对标GPT1, 12层,768维,12头
WordsCorpus 800M words
如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓
















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









