








论文链接:https://arxiv.org/pdf/2405.14785
项目链接:https://github.com/YangLing0818/EditWorld
扩散模型显著提升了图像编辑的性能。现有的方法通过各种方式实现高质量的图像编辑,包括但不限于文本控制、拖拽操作和mask修复。其中,基于指令的编辑因其在不同场景中方便有效地遵循人类指令而脱颖而出。然而,这些方法仍主要集中在添加、替换或删除等简单的编辑操作上,未能理解传达物理世界中现实动态特性的世界动态方面。因此,本研究提出了一个新的编辑任务,即世界指令图像编辑(EDITWORLD),定义并分类了基于各种世界场景的指令。本文使用一组大型预训练模型(如GPT-3.5、Video-LLava和SDXL)整理了一个包含世界指令的新图像编辑数据集。为了充分模拟图像编辑的世界动态,本文在整理的数据集上训练了EDITWORLD模型,并通过设计的后编辑策略提升了指令遵循能力。大量实验表明,本文的方法在这一新任务中显著优于现有的编辑方法。

介绍
文本到图像模型在扩散模型的显著发展下取得了巨大成功,如Stable Diffusion、DALL-E 2/3和RPG。为了提高可控性,文本引导的图像编辑取得了显著的进步。早期的研究如StyleGAN和CycleGAN能够实现合理的图像风格迁移。后续的模型主要从图像中提取关键特征,这些特征可以进一步融入文本到图像生成过程中,以生成具有参考图像风格和内容的图像。
为了使视觉编辑更加精确,一些方法尝试实现拖拽操作或基于附加mask进行局部图像操作。得益于如CLIP模型等多模态预训练方法的快速发展,许多方法利用富有表现力的跨模态语义控制来引导基于文本的图像编辑过程,而无需额外的手动操作或mask。
最近,基于指令的图像编辑方法通过教授图像编辑模型遵循人类指令,使普通用户能够通过自然命令方便、轻松地操作图像。例如,InstructPix2Pix 利用两个大型预训练模型(即 GPT-3 和 Stable Diffusion)生成大量的输入-目标-指令三元组示例数据集,并在该数据集上训练一个遵循指令的图像编辑模型。MGIE 进一步结合多模态大型语言模型(MLLMs),通过提供更具表现力的视觉感知指令来促进编辑过程。
尽管现有的基于文本和指令的方法在图像编辑中取得了高质量的结果,但它们忽视并且难以处理反映物理世界真实视觉动态的世界动态。例如,当被指示“给那个人戴上帽子”时,它们可以实现合理的结果,但在编辑“如果那个人滑倒了会发生什么”这样的指令时可能会失败。如上图1所示,无论是InstructPix2Pix还是MagicBrush都无法生成合理的编辑结果。
为了使图像编辑能够反映来自真实物理世界和虚拟媒体的复杂世界动态,本工作EDITWORLD引入了一项名为世界指令图像编辑的新任务,如上图1所示的数据示例。具体来说,本文定义并分类了多样的世界指令,并基于这些指令策划了一个新的多模态数据集,该数据集包含大量的输入-指令-输出三元组。该数据集的构建有两个分支:
- 本文利用GPT-3.5生成不同场景的世界指令,并采用文本到图像扩散模型,如SDXL和ControlNet,生成严格遵循世界指令的高质量输入-输出图像对。
- 本文从视频数据中选择两帧作为配对图像数据,这些图像在连续帧之间具有一致的身份,但由于视频运动而存在较大的空间变化或动态。然后,本文利用Video-LLava 和GPT-3.5生成相应的指令。
最后,本文使用精心整理的数据集微调了一个 instructPix2Pix 模型,并提出了一种zero-shot图像操纵策略,后期编辑以提高指令跟随能力并增强未编辑区域的外观一致性。大量实验表明,与以前的方法相比,本文的方法在世界指令图像编辑任务中实现了最新的(SOTA)结果。
总结本文的主要贡献如下:
- 提出了一项新的基础任务,称为世界指令图像编辑,该任务反映了物理世界和虚拟媒体中的真实动态。本文根据不同场景定义并分类世界指令。
- 利用一组大型预训练模型(包括GPT、多模态大模型(MLLM)和文本生成图像扩散模型)策划了一个新的多模态数据集用于世界指令图像编辑。这个精心整理的数据集还可以作为本文提出的编辑任务的新基准。
- 在该数据集上训练和改进了本文的基于扩散的图像编辑模型,在世界指令图像编辑任务中超越了之前的最新(SOTA)图像编辑方法,同时在传统编辑任务中也保持了竞争力的结果。
相关工作与讨论
基于扩散模型的文本引导图像编辑
最近在扩散模型(DMs)和多模态框架(如CLIP)方面的进展显著提升了文本到图像的生成能力,并展示了令人印象深刻的生成结果。基于这些基础,一些研究实现了使用条件扩散模型进行文本引导的图像编辑。例如,Blend Diffusion引入了一种基于mask的编辑方法,用于精确和无缝的图像操作。Prompt-to-Prompt通过修改交叉注意力,使图像与提示中的词语对齐,从而实现局部图像编辑。PAIR-diffusion提供了一种方法,可以独立编辑输入图像中每个mask区域的结构和外观。尽管这些方法表现出色,但它们高度依赖于详细的文本描述或精确的区域mask。相比之下,提供直接指令来修改特定区域或属性(如“将领带变成蓝色”)为普通用户提供了一种更加直接和用户友好的方式。
指令跟随图像编辑
基于指令的图像编辑旨在教导生成模型遵循人类编写的指令进行图像编辑,并已经取得了一些进展。例如,InstructPix2Pix 使用大型语言模型GPT-3和Prompt-to-Prompt来合成一个训练数据集,以获得专门用于指令跟随的图像编辑扩散模型。MagicBrush通过使用实际收集的图像数据集对InstructPix2Pix进行微调,增强了其能力。另一类研究利用多模态大型语言模型(MLLMs)来增强基于指令的图像编辑的跨模态理解。例如,MGIE通过与视觉相关的表达性指令共同学习MLLM和编辑模型,以提供明确的指导。尽管现有的图像编辑方法,特别是基于指令的图像编辑方法,已经能够在图像中进行简单的编辑操作,但它们仍然难以处理来自现实世界的指令,并且缺乏反映世界动态的图像对数据集。为了解决这个问题,本文提出了一种新的任务设定,即世界指令图像编辑,并在此设定下实现了最先进的性能。
利用大型预训练模型执行多模式任务
随着大规模预训练技术的发展,许多工作利用预训练大型模型中embedding的广泛知识(例如,多模态大型语言模型、SAM或Stable Diffusion),更有效地解决各种任务。在一些领域已经取得了显著成就,如图像编辑、视频编辑和文本到3D生成。本文的EDITWORLD利用一组大型预训练模型来处理图像和视频数据,并构建一个包含多样化输入-指令-输出三元组示例的多模态数据集,以增强世界指令图像编辑。
使用生成模型生成数据
深度模型通常需要大量数据进行训练。尽管互联网提供了丰富的数据资源,但往往缺乏监督学习所需的结构化配对数据。随着生成模型的进步,它们越来越被视为一种成本效益高的方式,用于为各种应用生成大量训练数据。本文所提出任务设置所需的配对数据在互联网上很少见。在这项工作中,本文设计了两个合成分支,即文本到图像生成和视频帧提取,并利用生成模型的组合来生成复杂且丰富的数据样本,用于世界指令图像编辑。
方法
世界指令的定义
指令引导的图像编辑旨在根据指令编辑输入图像。现有的方法已经有效地实现了对象替换、移除和添加。然而,现有的方法在模拟物理世界或虚拟媒体中的真实视觉动态方面仍然存在挑战。因此,在本节将介绍如何生成一个包含编辑三元组的多模态数据集,该数据集能够反映各种世界动态。本文首先定义并分类本文提出的世界指令。本文遇到的图像通常来源于物理世界或虚拟媒体。因此,本文将世界指令分为两大类:现实世界和虚拟世界。本文进一步将这两类世界指令细化为七个具体类别,基于不同的场景,如下表1所示。为了增强对不同世界指令的理解,本文提供了一个输入-指令-输出三元组的示例来实例化每种类型。
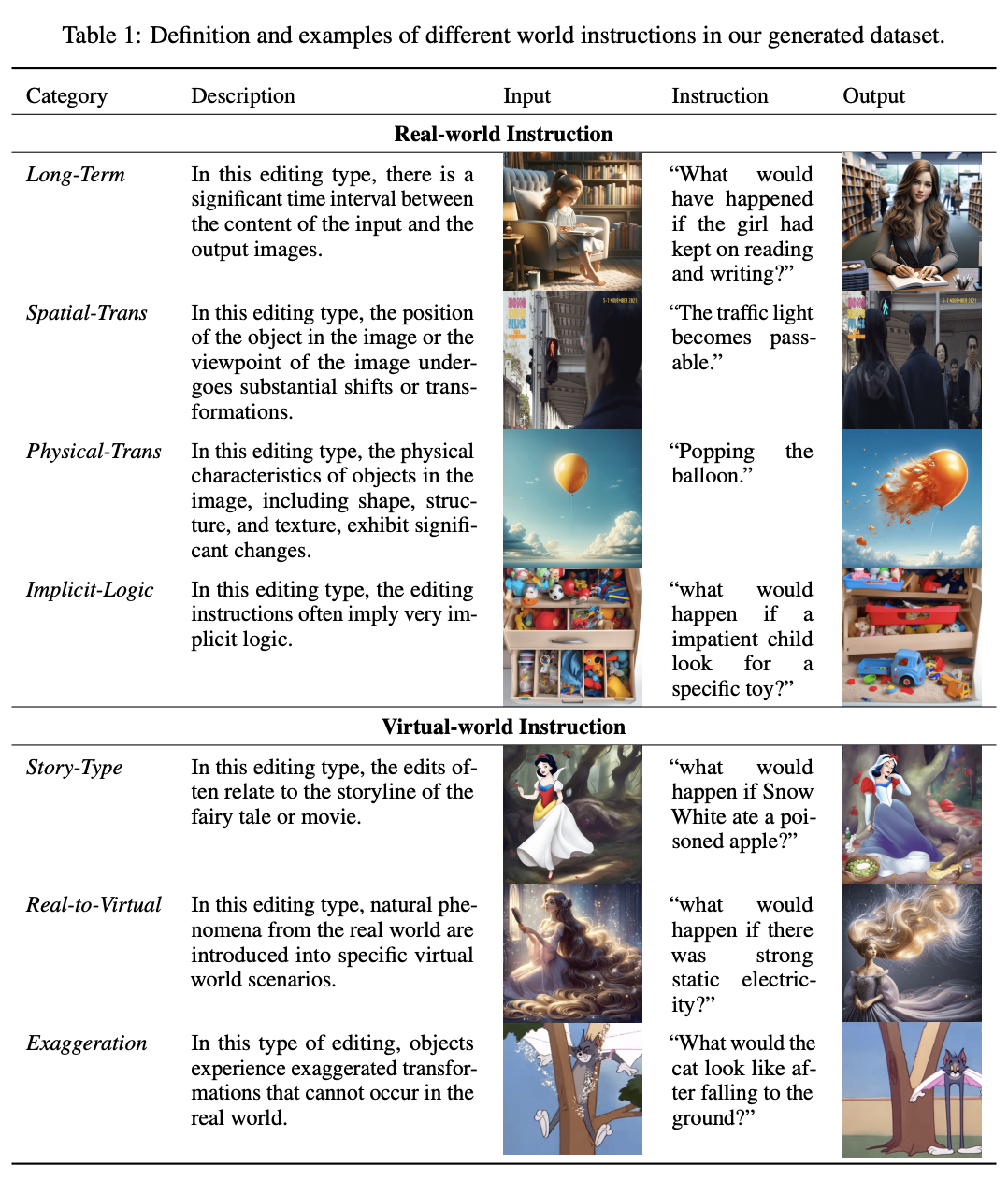
使用 World 指令生成数据集
多种场景的文生图
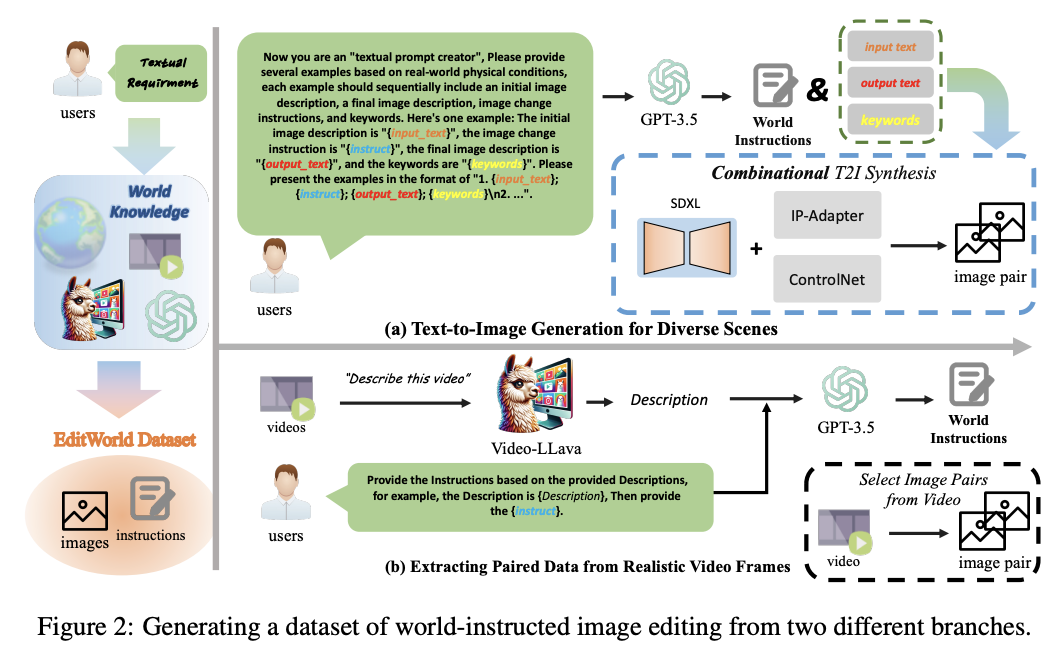
在这一部分,介绍了如何利用大型语言模型(LLMs)和文本到图像生成模型来生成大量的输入-指令-输出三元组。如下图2(a)所示,本文设计了一个模板来提示GPT-3.5合成一系列文本四元组(输入图像的提示 y ori y_{\text{ori}} yori、指令 y instr y_{\text{instr}} yinstr、输出图像的提示 y tar y_{\text{tar}} ytar 和关键词 { k 1 , k 2 , … , k n } \{k_1, k_2, \ldots, k_n\} {k1,k2,…,kn}),这些四元组用于后续生成输入-输出配对图像。其中,关键词用于表示需要编辑的部分。
组合文本到图像生成过程。 本文结合了预训练的SDXL文本到图像扩散去噪器 ϵ θ \epsilon_\theta ϵθ 来基于文本四元组合成输入图像 I ori I_{\text{ori}} Iori 和输出图像 I tar I_{\text{tar}} Itar。首先,为了定位编辑区域,本文在生成 I ori I_{\text{ori}} Iori 的过程中收集了关键词 k 1 , k 2 , … , k n k_1, k_2, \ldots, k_n k1,k2,…,kn 的交叉注意力图 M 1 , M 2 , … , M n M_1, M_2, \ldots, M_n M1,M2,…,Mn。本文使用阈值将这些注意力mask的每个像素 ( m , n ) (m, n) (m,n) 进行二值化,以创建二值mask M b M^b Mb。二值化过程定义如下:
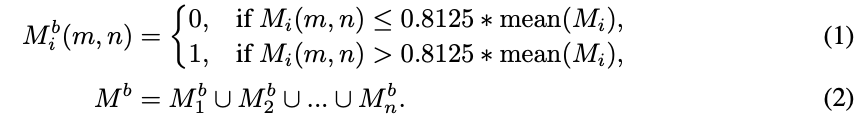
然后,为了保留非编辑区域,本文在 I ori I_{\text{ori}} Iori 的mask区域 M b M^b Mb 内进行图像修复,以文本提示 y tar y_{\text{tar}} ytar 合成 I tar I_{\text{tar}} Itar。 I ori I_{\text{ori}} Iori 使用LDM的VAE编码器 E E E 编码到潜在空间中, z ori ∼ E ( I ori ) z_{\text{ori}} \sim \mathcal{E}(I_{\text{ori}}) zori∼E(Iori),基于去噪的修复过程可以定义如下:
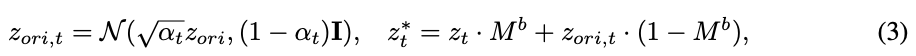
其中, z t z_t zt 表示去噪后的潜变量。为了进一步确保 I ori I_{\text{ori}} Iori 和 I tar I_{\text{tar}} Itar 之间的身份一致性,本文使用 IP-Adapter和 ControlNet F ctrl F_{\text{ctrl}} Fctrl 对 I tar I_{\text{tar}} Itar 进行额外的精细调整。具体来说,IP-Adapter 从原始图像 I ori I_{\text{ori}} Iori 中提取视觉特征 f ori f_{\text{ori}} fori,以指导精细调整过程,从而保持 I ori I_{\text{ori}} Iori 和 I tar I_{\text{tar}} Itar 之间的身份一致性。同时,ControlNet 利用 I tar I_{\text{tar}} Itar 的 canny 边缘图 m canny m_{\text{canny}} mcanny 来指导精细调整,从而保留 I tar I_{\text{tar}} Itar 的结构。精细调整后的 I tar I_{\text{tar}} Itar 的预测噪声表示为:
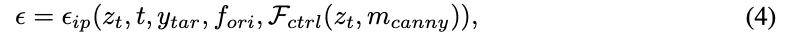
IP-Adapter的去噪器记作 ϵ i p \epsilon_{ip} ϵip。最后,本文采用MLLM作为判别器,使用语义对齐、身份一致性和图像质量作为标准,选择最合理和高质量的生成图像对作为本文的训练数据。通过这个文本到图像生成分支,可以获得的世界指令类型包括长期、物理转变、隐含逻辑、故事类型和现实到虚拟。
生成过程的表现力 值得一提的是,与使用Prompt-to-Prompt中简单交叉注意力操作生成训练数据的InstructPix2Pix相比,本文的文本到图像生成分支可以通过组合利用特定的预训练模型处理更复杂的图像变化。例如,在Prompt-to-Prompt中,输入输出文本修改只允许简单的词语变化,如“A snowman”到“A melted snowman”。相反,本文的方法允许从“A snowman stands in a winter wonderland surrounded by glistening snowflakes”到“A melted snowman, leaving behind a puddle of water and a few remnants of coal and carrot on the ground”的更复杂变化。这意味着EDITWORLD的数据集生成更加灵活和富有表现力,生成的数据可以包含更复杂的编辑场景。
从真实视频帧中提取配对数据
除了文本到图像分支生成的丰富数据外,本文还从视频数据集InternVid中提取配对数据,以增加数据集的现实性。具体来说,本文选择两个具有强身份一致性但由于某些运动导致的最大空间/视觉变化或动态的视频帧。这两个帧通常是视频故事线的起点和终点。然后,如上图2(b)所示,本文使用预训练的视频语言模型Video-LLava获取此视频故事线的描述。随后,本文使用GPT-3.5根据预定义格式将此描述转换为世界指令。通过这种方式,提取的首尾帧分别作为输入图像和输出图像。结合生成的指令,它们可以形成一系列输入-指令-输出三元组,用于扩充本文的编辑数据集。这种从视频数据中提取的三元组示例包括以下类型的世界指令:空间转换(Spatial-Trans)、物理转换(Physical-Trans)、故事类型(Story-Type)和夸张(Exaggeration)。
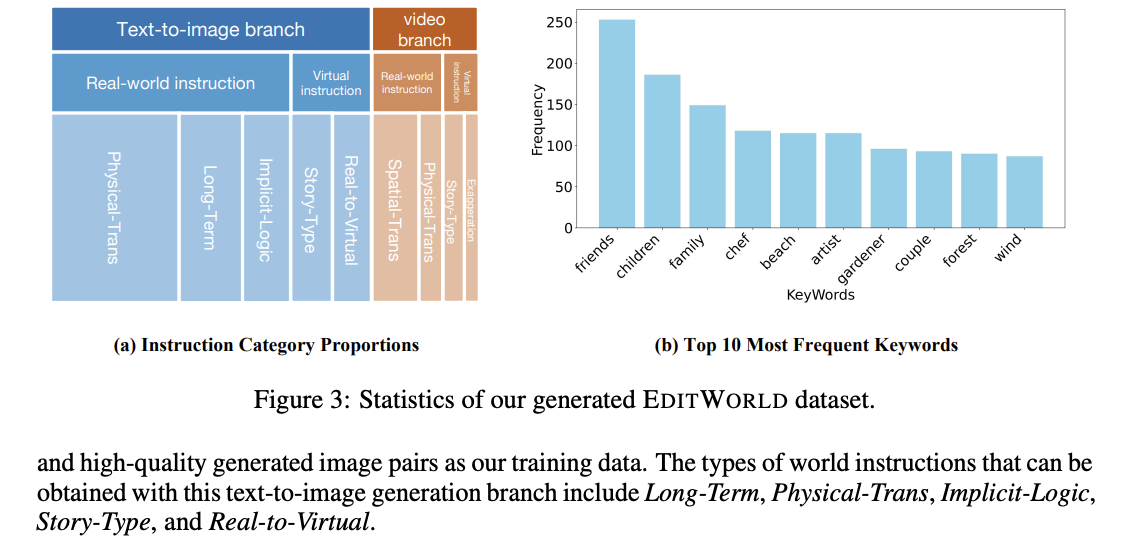
EDITWORLD 数据集的统计数据
为了提供更直观的理解,本文对数据集的细节进行了可视化。下图3(a)展示了EDITWORLD数据集在不同分支和指令类别下的分布情况。由于世界动态变化的不同类型数量有所不同(例如,物理世界的变化比虚拟世界的变化更为丰富),因此EDITWORLD数据集中各类世界指令的相应数据量也有所不同。此外,为了更全面地说明本文数据集的内容,下图3(b)展示了出现频率最高的20个关键词。另外,由于这两个分支生成的一些图像可能分辨率较低且缺乏合理性。
EDITWORLD的图像编辑模型
本文使用从两个分支构建的数据集来训练一个基于指令的图像编辑扩散模型(DM)。DM的输入条件包括指令 y instr y_{\text{instr}} yinstr 和输入图像 I ori I_{\text{ori}} Iori 的潜在编码 z ori z_{\text{ori}} zori。用于训练去噪器 ϵ θ \epsilon_{\theta} ϵθ 的监督函数如下:
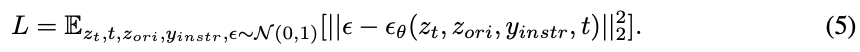
本文将训练后的扩散模型生成的结果定义为
I
gen
I_{\text{gen}}
Igen。按照 InstructPix2Pix中描述的无分类器指导方法,本文基于
I
ori
I_{\text{ori}}
Iori 和
y
instr
y_{\text{instr}}
yinstr 修改噪声估计如下:
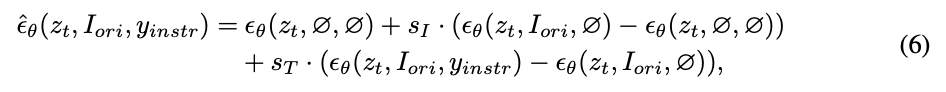
其中, s I s_I sI 和 s T s_T sT 表示指导尺度。
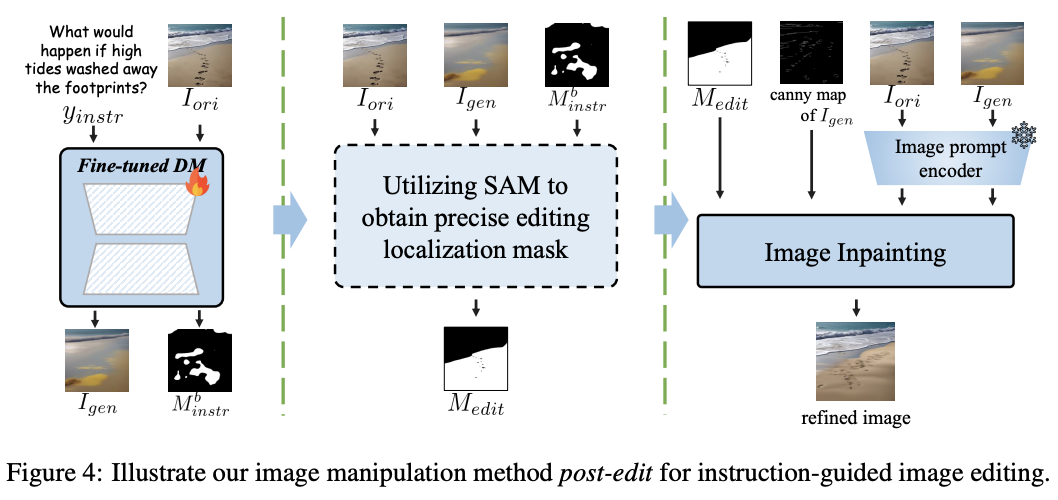
后编辑方法 微调后的扩散模型已经能够进行有效的基于世界指令的图像编辑。为了进一步优化生成结果,并尽量保持输入图像的非编辑区域,如下图4所示,本文提出了一种新的图像操作方法——后编辑,以优化编辑过程。具体来说,本文在推理过程中从 ϵ θ ( z t , I ori , ∅ ) \epsilon_{\theta}(z_t, I_{\text{ori}}, \varnothing) ϵθ(zt,Iori,∅) 中提取一个二值注意力mask M b instr M_{b_{\text{instr}}} Mbinstr,提供编辑位置的大致定位。然后,本文使用 SAM [64] 对 I gen I_{\text{gen}} Igen 和 I ori I_{\text{ori}} Iori 进行分割,并计算与 M instr b M_{{\text{instr}}}^b Minstrb 最大重叠的精确mask M gen M_{\text{gen}} Mgen 和 M ori M_{\text{ori}} Mori。随后,本文将 M gen M_{\text{gen}} Mgen 和 M ori M_{\text{ori}} Mori 的并集定义为mask M edit M_{\text{edit}} Medit,以增强编辑定位的精确度。虽然 I gen I_{\text{gen}} Igen 已经提供了合理的编辑结果,但通过将 M edit M_{\text{edit}} Medit、 I gen I_{\text{gen}} Igen 的 Canny 边缘图,以及 I ori I_{\text{ori}} Iori 的视觉特征放入图像修复过程中,本文的方法可以进一步提高 I gen I_{\text{gen}} Igen 的质量,同时很好地保留非编辑区域。
实验
实施细节
评估 本文随机选择了来自文本到图像分支的300个数据三元组和来自视频分支的200个数据样本进行测试。剩余的数据用于训练EDITWORLD的图像编辑模型。测试数据集中的每个测试数据三元组包括一个输入图像、一个指令和一个输出图像描述。本文使用CLIP分数作为度量标准,以评估生成的编辑结果是否与输出语义一致,从而判断该方法在世界指令编辑中的有效性。此外,由于世界指令编辑任务的复杂性,CLIP分数可能不足以准确评估某些情况下的图像编辑逻辑准确性。因此,本文引入了一种新的度量标准,称为MLLM分数,该标准利用多模态大型语言模型来评估各种方法在世界指令编辑任务中的指令遵循能力。
训练细节 EDITWORLD的数据生成和模型训练在4×80GB的NVIDIA A100 GPU上完成。模型使用InstructPix2Pix的权重进行初始化,并在本文提出的数据集上进行微调,总共训练了100个epoch。本文使用批量大小为64,图像分辨率为512×512。训练采用Adam优化器,学习率为 5 × 1 0 − 6 5 \times 10^{-6} 5×10−6。
定量评价
为了更准确地评估各种模型在不同场景下的世界指令图像编辑能力,本研究在不同数据类型下测试图像编辑能力,这些数据类型按七种指令和两个数据分支分类。本文在下表2中将本文的EDITWORLD与五种SOTA方法在不同类型的指令下进行了比较。
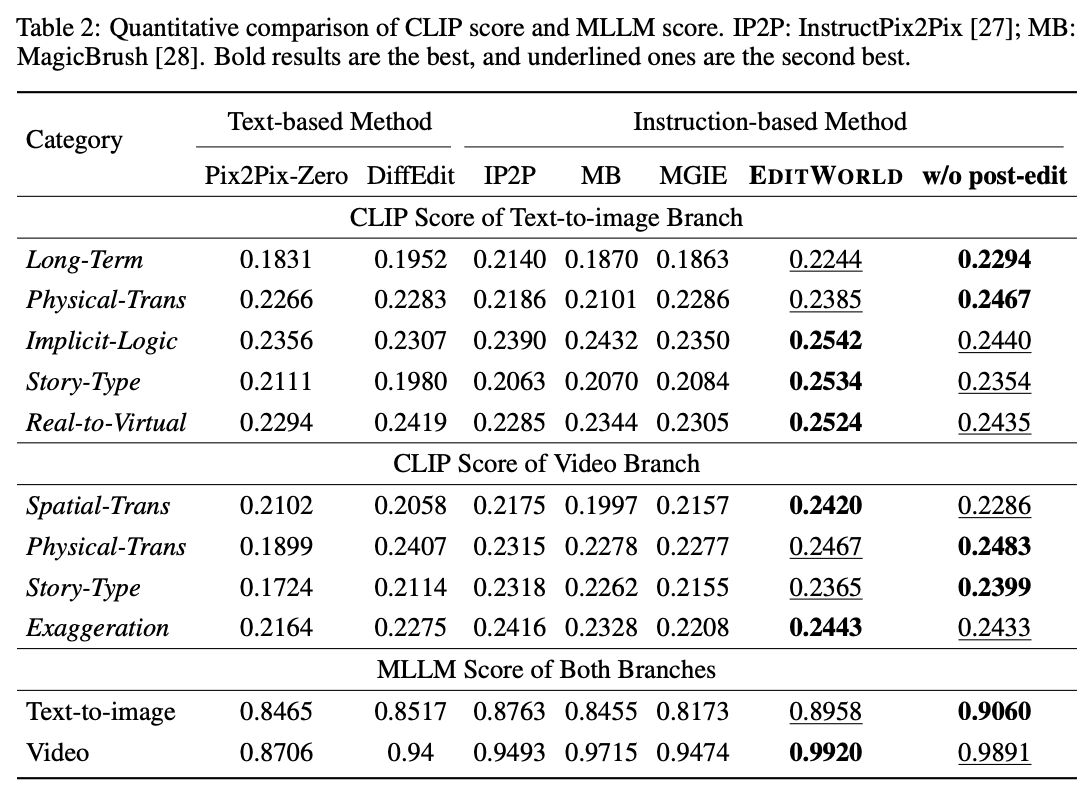
比较文本转图像和视频分支之间的编辑方法 由于本文在文本到图像和视频分支中的数据获取动机不同,本文分别评估了这些分支的编辑方法在测试数据集上的表现。在两个数据集中,本文的方法在CLIP分数和MLLM分数指标方面始终优于其他方法,展示了在世界指令编辑任务中的卓越编辑能力和稳定性。值得注意的是,本文的方法在不进行后期编辑的情况下仍保持了出色的表现,这突显了本文精心策划的数据集的有效性。
比较结果显示了两个测试数据集中性能提升的显著差异:在文本到图像分支的测试数据集中,本文的方法通常显著优于其他方法,这表明复杂的编辑场景对传统编辑方法仍然是一个挑战。与此同时,在视频分支的测试数据集中,本文的方法的改进不如在文本到图像分支的测试数据集中显著。本文将这种差异归因于从视频中提取的帧通常包含复杂的场景,主要主题并不突出。因此,在视频分支中,实现理想的编辑是具有挑战性的。
此外,尽管InstructPix2Pix在CLIP分数上高于其他基准方法,但这表明尽管InstructPix2Pix对指令响应有效,但它仍然难以保持输入图像的视觉质量,并在世界指令编辑中实现理想的图像编辑。
评估不同指令类别下的编辑方法性能 为了研究各种方法在世界指令编辑任务中不同场景下的编辑能力,本文评估了它们在七个不同指令类别中的表现。本文的方法在所有类别中均表现出色。尤其在长期变化(Long-Term)、物理转换(Physical-Trans)、空间转换(Spatial-Trans)、故事类型(Story-Type)和夸张(Exaggeration)等类别中,本文的方法表现尤为突出,因为这些类别涉及输入和输出图像之间的显著差异,同时保持了它们之间的相关性。传统编辑模型由于缺乏对世界动态的了解,在这些场景中无法生成合理的结果,从而突显了本文方法的有效性。
对于隐含逻辑(Implicit-Logic)和现实到虚拟(Real-to-Virtual)类别,这些指令复杂或抽象,输入和输出图像之间的变化微妙,有些变化类似于传统编辑任务中遇到的情况。现有的基于文本的编辑方法在这些类别中表现良好,因为它们直接提供了输出文本,简化了任务。相反,像InstructPix2Pix这样的基于指令的方法,由于使用了由大型语言模型(LLM)生成指令的数据集进行训练,在处理这些复杂指令时表现出色。尽管如此,本文的方法在这两个类别中仍然始终优于这些基线方法。
定性分析
为了展示EDITWORLD模型的编辑能力,本文随机选择了几个不同指令的示例进行可视化,如下图5和下图6所示。以往的编辑方法通常无法根据给定的文本或指令正确编辑图像,导致图像没有变化或出现不符合编辑要求的显著改动。相比之下,本文的方法能够根据给定的指令有效地编辑图像,生成高质量的结果。值得注意的是,尽管DiffEdit 和 MGIE能够保持输入图像的质量,但它们的可视化结果显示出对编辑指令的准确反映不足。


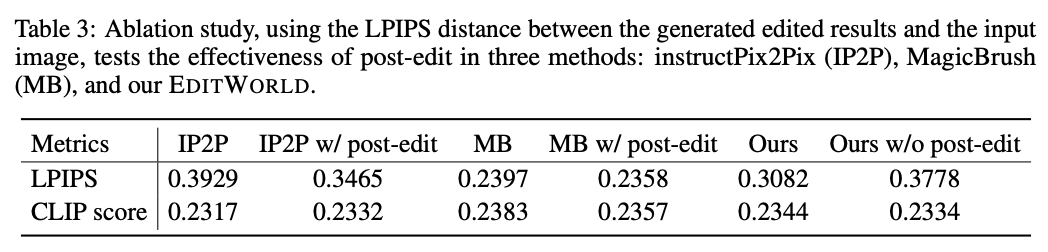
消融实验
为了验证本文提出的后期编辑方法能有效保留未编辑区域并保持高质量的编辑效果,同时在传统编辑任务中表现良好,本文进行了一个消融研究。本文选择了50个传统编辑测试数据集,包括18个用于“添加”的输入-指令-输出三元组,25个用于“更改”的三元组,以及7个用于“移除”的三元组。如下表3所示,应用后期编辑方法后,LPIPS指标显著改善,而CLIP评分保持一致。这表明本文的后期编辑方法可以在不降低编辑质量的情况下保留未编辑区域。同时,本文的EDITWORLD在CLIP评分上取得了与[27, 28]相当的结果,证实了其在传统编辑任务中的有效性。
总结
本文提出了一种新的图像编辑任务,称为世界指令图像编辑。该任务利用现实世界和虚拟世界中的不同场景提供图像编辑指令。本文对这些指令进行分类、定义并举例说明,并使用GPT、大规模多模态模型和文本生成图像模型从大量视频和文本中获取图像编辑数据。利用这些数据,本文构建了世界指令图像编辑任务的定量评估指标,并使用收集到的数据训练和改进图像编辑模型,在这一新的世界指令图像编辑任务中实现了最新的(SOTA)性能。


参考文献
[1] EDITWORLD: Simulating World Dynamics for Instruction-Following Image Editing

















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









