








文章链接:https://arxiv.org/pdf/2310.11448
git链接: https://zju3dv.github.io/4k4d/
本文旨在实现动态3D场景在4K分辨率下的高保真和实时视图合成。最近,一些动态视图合成方法在渲染质量方面表现出色。然而,在渲染高分辨率图像时,它们的速度仍然有限。为解决这个问题,本文提出了4K4D,一种支持硬件光栅化的4D点云表示,能够实现前所未有的渲染速度。本文的表示基于4D特征网格构建,因此点云被自然地正则化并可以进行稳健优化。此外,设计了一种新颖的混合外观模型,显著提升了渲染质量,同时保持了效率。此外,开发了一种可微分的深度剥离算法,以有效地从RGB视频中学习所提出的模型。实验表明,在使用RTX 4090 GPU的情况下,本文的表示在1080p分辨率下可以在DNA-Rendering数据集上以超过400 FPS的速度进行渲染,在4K分辨率下可以在ENeRF-Outdoor数据集上以80 FPS的速度进行渲染,比以往方法快30倍,并实现了最先进的渲染质量。

方法
给定捕捉动态3D场景的多视角视频,目标是重建目标场景并实时执行新视角合成。为此,研究者们使用空间雕刻算法提取场景的粗点云,并建立基于点云的神经场景表示,该表示可以从输入视频中稳健地学习,并支持硬件加速渲染。
下图2展示了所提模型的概述。首先描述如何基于点云和神经网络表示动态场景的几何和外观。然后,开发了一种可微分深度剥离算法,用于渲染表示,该算法由硬件光栅化器支持,从而显著提高了渲染速度。最后,讨论如何在输入RGB视频上优化所提模型。
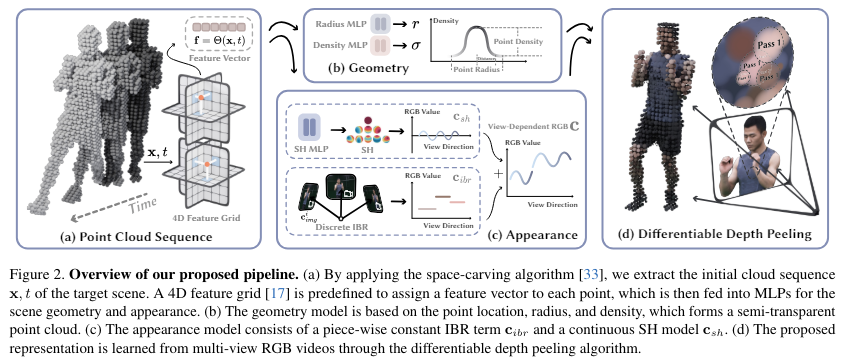
使用点云建模动态场景
4D embedding。给定目标场景的粗点云,使用神经网络和特征网格来表示其动态几何和外观。具体而言,本文的方法首先定义了六个特征平面:θ、θ、θ、θ、θ和θ。为了在帧t中为任意点x分配一个特征向量f,采用K-Planes的策略,使用这六个平面来建模一个4D特征场:
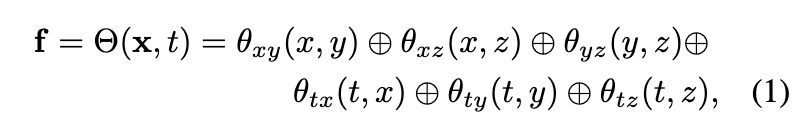
其中, 是输入点, 表示拼接运算符。更多实现细节请参考K-Planes。
几何模型。基于粗点云,动态场景几何通过学习每个点的三个条目来表示:位置 、半径 和密度 。使用这些点条目,计算体渲染时与图像像素 u 对应的空间点 x 的体积密度。点的位置 被建模为一个可优化的向量。半径 r 和密度 通过将方程 (1) 中的特征向量 输入到 网络来预测。
外观模型。如上面图 2c 所示,使用图像混合技术和球谐函数 (SH) 模型来构建混合外观模型,其中图像混合技术表示离散的视角依赖外观 ,SH 模型表示连续的视角依赖外观 。对于帧 t 中的点 ,其在视角方向 下的颜色为:
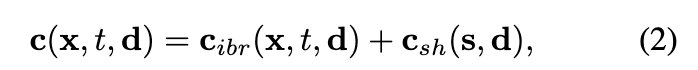
其中,s 表示点 处的 系数。
离散的视角依赖外观 基于输入图像推理。具体而言,对于一个点 ,首先将其投影到输入图像中以检索相应的 RGB 颜色 。然后,为了混合输入的 RGB 颜色,根据点坐标和输入图像计算相应的混合权重 。请注意,混合权重与视角方向无关。接下来,为了实现视角依赖效果,根据视角方向选择 N′ 个最近的输入视角。最后,颜色 计算为 。由于 N′ 个输入视角是通过最近邻检索获得的,因此 cibr 在视角方向上不可避免地是离散的。为了实现连续的视角依赖效果,附加了由 SH 模型表示的精细级别颜色 ,如上面图 2c 所示。
在实践中,本文的方法通过将方程 (1) 中的点特征 传递到 网络来回归 系数 s。为了在图像混合模型 中预测混合权重 ,首先将点 投影到输入图像上以检索图像特征 ,然后将其与点特征 f 拼接,并将其输入到另一个 网络中以预测混合权重。图像特征 使用 2D CNN 网络提取。
讨论。本文的外观模型是实现动态场景的低存储、高保真和实时视图合成的关键。有三种替代方法来表示动态外观,但它们的表现无法与本文的模型相提并论。
-
在每个点上定义显式 SH 系数,如在 3D 高斯分裂 中。当 SH 系数的维度较高且动态场景的点数量较大时,该模型的大小可能太大,无法在消费级 GPU 上训练。
-
基于 MLP 的 SH 模型。使用 MLP 来预测每个点的 SH 系数可以有效地减少模型大小。然而,本文的实验发现基于 MLP 的 SH 模型难以渲染高质量图像。
-
连续视角依赖的图像混合模型,如 ENeRF。使用图像混合模型表示外观比仅使用基于 MLP 的 SH 模型具有更好的渲染质量。然而,ENeRF 中的网络将视角方向作为输入,因此无法轻松预计算,从而限制了推理期间的渲染速度。
与这三种方法相比,本文的外观模型结合了离散图像混合模型 和连续 SH 模型 。图像混合模型 提升了渲染性能。此外,由于其网络不将视角方向作为输入,它支持预计算。SH 模型 实现了任何视角方向的视角依赖效果。在训练期间,本文的模型使用网络表示场景外观,因此其模型大小合理。在推理期间,预计算网络输出以实现实时渲染。
可微分深度剥离
研究者们提出的动态场景表示可以使用深度剥离算法渲染成图像。得益于点云表示,能够利用硬件光栅化器显著加速深度剥离过程。此外,使这一渲染过程可微分也很容易,从而能够从输入的 RGB 视频中学习本文的模型。
研究者们开发了一个自定义着色器来实现包含 K 次渲染通道的深度剥离算法。考虑一个特定的图像像素 u。在第一次通道中,本文的方法首先使用硬件光栅化器将点云渲染到图像上,为像素 u 分配最近的点 。记点 的深度为 。随后,在第 k 次渲染通道中,所有深度值 小于上一通道记录深度 的点都被丢弃,从而得到像素 u 的第 k 近的点。丢弃较近的点在自定义着色器中实现,因此它仍然支持硬件光栅化。在 K 次渲染通道之后,像素 u 有一组排序的点 。
基于点 ,使用体渲染合成像素 u 的颜色。像素 u 的点 的密度是基于投影点和像素 u 在2D图像上的距离定义的。

其中, 是摄像机投影函数。 和 r 分别是点 的密度和半径。在训练过程中,使用 PyTorch实现投影函数,因此方程 (3) 自然是可微的。在推理过程中,利用硬件光栅化过程高效地获得距离 ,这通过 OpenGL 实现。
记点 的密度为 。像素 u 的体渲染颜色公式如下:
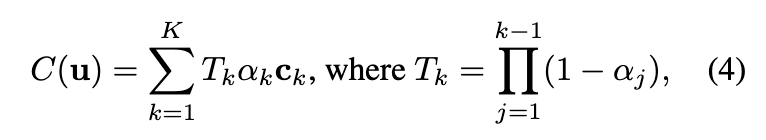
其中, 是点 的颜色,如方程 (2) 所述。
训练
给定渲染的像素颜色 ,将其与真实像素颜色 进行比较,以端到端的方式使用以下损失函数来优化模型:
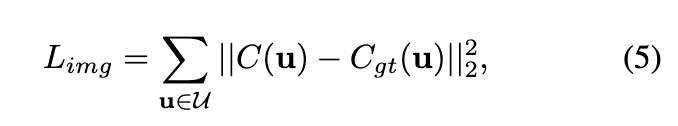
其中, 是图像像素的集合。除了均方误差损失 外,还应用感知损失 。
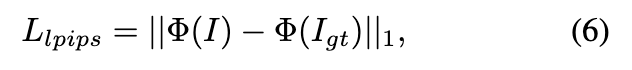
其中, 是感知函数(一个 VGG16 网络),I 和 分别是渲染和真实图像。感知损失计算从 VGG 模型提取的图像特征之间的差异。实验中表明,它有效地提高了渲染图像的感知质量。
为了规范,本文提出的表示优化过程,还额外应用mask监督到目标场景的动态区域。仅渲染动态区域的点云以获得它们的mask,其中像素值由以下公式得到:
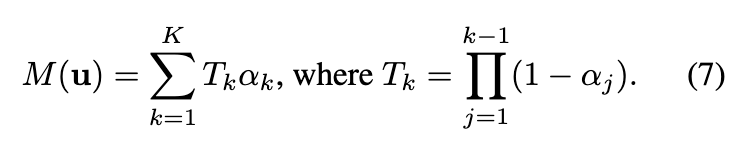
mask损失定义如下:
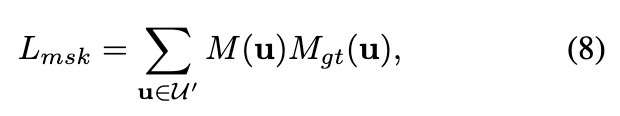
其中,表示渲染mask的像素集合,而 是2D动态区域的地面真实mask。这有效地通过将其限制在视觉外壳中,规范了动态区域几何优化的过程。
最终的损失函数定义如下:
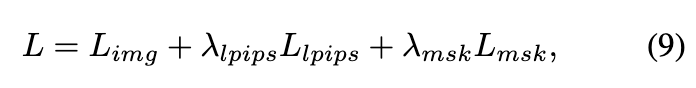
其中, 和 是控制对应损失权重的超参数。
推理
训练完成后,采用几种加速技术来提升模型的渲染速度。首先,在推理之前预先计算点位置 p、半径 r、密度 、SH 系数 s 和颜色混合权重,这些数据存储在主内存中。在渲染过程中,这些属性被异步地流式传输到显卡上,通过重叠光栅化和内存复制来实现最优的渲染速度。应用这一技术后,运行时计算仅包括深度剥离评估和球谐函数评估 (Eq.(2))。其次,将模型从32位浮点数转换为16位,以实现高效的内存访问,这提高了帧率约20,并且经验证没有可见的性能损失,如表6所示。第三,不可微分深度剥离算法的渲染通道数 K 从15减少到12,同样提高了20 FPS 的速度,而视觉质量无变化。
实现细节
优化
4K4D 使用 PyTorch 框架进行训练。使用 Adam 优化器,学习率为 5e−3,通常在序列长度为 200 帧的情况下,模型会在约 800k 次迭代后收敛,这在单个 RTX 4090 GPU 上大约需要 24 小时。具体而言,点位置的学习率设置为,正则化损失权重 λ和λ 设置为 1e−3。训练过程中,不可微分深度剥离的通道数 K 设置为 15,最近输入视图的数量 N′ 设置为 4。本文的方法的渲染速度是基于 RTX 3090 GPU 报告的,除非另有说明。
点云初始化
利用现有的多视角重建方法来初始化点云。对于动态区域,使用分割方法 在输入图像中获取它们的mask,并利用空间雕刻算法提取它们的粗略几何信息。对于静态背景区域,利用前景mask沿所有帧计算背景像素的mask加权平均,生成不包含前景内容的背景图像。然后,在这些图像上训练一个 Instant-NGP模型,从中获取初始点云。初始化后,动态区域每帧通常包含约 250k 个点,静态背景区域通常包含约 300k 个点。
实验
数据集和评估指标
在多个广泛使用的多视角数据集上训练和评估本文的方法 4K4D,包括 DNA-Rendering、ENeRF-Outdoor、NHR和 Neural3DV。
-
DNA-Rendering: 这个数据集使用 4K 和 2K 相机记录了动态人类和物体的 10 秒视频片段,帧率为 15 FPS,采集了 60 个视角。由于录制了复杂的服装和快速移动的人物,这个数据集非常具有挑战性。在 DNA-Rendering 的 4 个序列上进行实验,其中将 90% 的视角作为训练集,其余作为评估集。
-
ENeRF-Outdoor: 这个数据集在室外环境中使用 1080p 相机以 30FPS 记录了多个动态人物和物体。选择了三个包含 6 个不同演员(每个序列选择了 2 个演员)的 100 帧序列来评估本文的方法 4K4D。这个数据集对于动态视角合成具有挑战性,因为同一个片段中不仅有多个移动的人物和物体,而且由于人物的阴影,背景也是动态的。
遵循 Im4D 和 NeuralBody 的做法,在 DNA-Rendering 和 NHR 数据集上评估动态区域的指标,可以通过预定义人物的 3D 边界框并将其投影到图像上来获得。对于 ENeRF-Outdoor,联合训练前景的动态几何和外观以及背景的动态外观,以获得整体图像的渲染结果。所有图像在评估时都会按比例调整大小,如果原始分辨率超过 2K,则缩放比例为 0.375。在实验中,DNA-Rendering 的渲染图像大小为 1024×1224(和 1125×1536),ENeRF-Outdoor 的分辨率为 960×540。Neural3DV 视频和 NHR 的分辨率分别为 1352×1224 和 512×612(和 384×512)。
对比实验
对比结果 在 DNA-Rendering数据集上的定性和定量比较如下图5和表1所示。

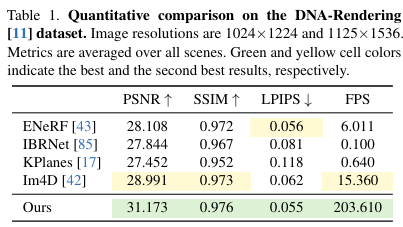
从表 1 可以明显看出,本文的方法 4K4D 的渲染速度比当前最先进的实时动态视角合成方法ENeRF快30倍,并且在渲染质量上表现更优秀。即使与并行工作相比,本文的方法 4K4D 仍然实现了 13 倍的加速,并且能够产生一致性更高质量的图像。如图 5 所示,KPlanes无法恢复高度详细的 4D 动态场景的外观和几何特征。其他基于图像的方法 能够产生高质量的外观效果。然而,它们往往在遮挡和边缘处产生模糊的结果,导致视觉质量的降低,最多能保持交互式帧率。相反,本文的方法 4K4D 可以以超过 200 FPS 的速度生成更高保真度的渲染结果。图 3 和表 2 提供了在 ENeRF-Outdoor数据集上的定性和定量结果。即使在具有多个演员和动态背景的挑战性 ENeRF-Outdoor 数据集上,本文的方法 4K4D 仍然能够取得显著更好的结果,同时以超过 140 FPS 的速度进行渲染。ENeRF在这个具有挑战性的数据集上产生模糊的结果,而 IBRNet的渲染结果在图像边缘处含有黑色伪影,如图 3 所示。K-Planse在重建动态人物和变化背景区域上失败。

消融研究
在 DNA-Rendering数据集的 150 帧序列 0013 01 上进行了消融研究。定性和定量结果如下图6和表4至表7所示。

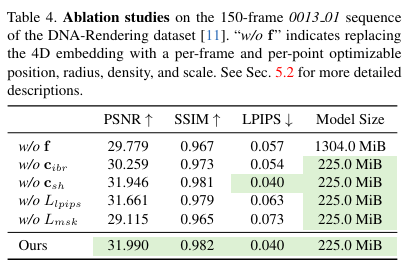


4D embedding消融研究 "w/o f" 变体移除了提出的 4D embedding模块,并将其替换为每帧和每点可优化的位置、半径、密度和比例。如上面图 6 和表 4 所示,"w/o f" 变体在没有 4D embedding模块 的情况下产生模糊和噪声的几何效果,从而导致渲染质量的下降。
混合外观模型消融研究 "w/o " 变体移除了外观公式 Eq. (2) 中的 ,这不仅导致恢复的外观细节减少,还显著阻碍了几何质量。增加 SH 系数的额外度数并未导致显著的性能变化(PSNR 30.202 对比 30.328)。相比之下,本文提出的方法能够以更好的细节产生高保真度的渲染效果。
损失函数消融研究 如表 4 所示,移除 项不仅降低了感知质量(LPIPS 分数),还导致其他性能指标的降低。对于高度动态的 DNA-Rendering 数据集,遮罩损失 Lmsk 有助于规范动态几何的优化过程。
存储分析 对于 150 帧序列 0013 01 场景,本文的方法 4K4D 的存储分析列在表 5 中。由于其显式表示,点位置 p 占据了模型尺寸的大部分。本文方法的最终存储成本每帧少于 2 MB,包括源视频。DNA-Rendering的输入图像以 JPEG 格式提供。使用 FFmpeg 的 HEVC 编码器将所有输入图像的帧编码为视频,编码质量因子设置为 25。编码后,观察到 LPIPS 没有变化(0.040),SSIM 没有损失(0.982),PSNR 只降低了 0.42%(31.990 对比 31.855),表明方法 4K4D 对于输入图像的视频编码具有鲁棒性。对于以视频形式编码的输入图像,基于图像的渲染的存储开销每帧仅为 0.419 MB,渲染质量几乎没有变化。
作者预计算了点云上的物理属性以实现实时渲染,每帧大约需要 2 秒。尽管预计算的缓存尺寸较大(0013 01 的一帧为 200 MB),但这些预计算的缓存仅驻留在主存储器中,并没有显式存储在磁盘上,这对现代个人电脑来说是可行的。这使得表示形式成为一种压缩形式,磁盘文件大小较小(每帧 2 MB),但所包含的信息非常丰富(每帧 200 MB)。
渲染速度分析
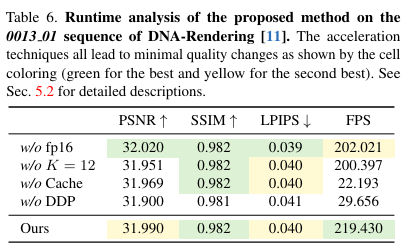
本文引入了多种优化技术来加速方法 4K4D 的渲染速度,这些技术仅由研究者们提出的混合几何和外观表示方法实现。在上面表6中,分析了这些提议技术在 DNA-Rendering 数据集的 150 帧序列 0013 01 上的有效性和质量影响。
计算的有效性
为了实现实时渲染,预计算并缓存了所有点的位置 p、半径 r、密度 和 SH 系数 s,并存储在主存储器中。由于研究者们将外观表示分割为常数项 和视角相关项 ,还可以预计算并缓存所有源图像的每帧权重 w 和颜色 。对于 DNA-Rendering数据集的 150 帧 60 视角场景的 0013 01,这些缓存每帧占据大约 200MB 主存储器。本文呢方法所实现的预计算实现了 10 倍的速度提升(Ours vs. “w/o Cache”)。
可微深度剥离 本文还与传统的基于 CUDA 的可微分点云渲染技术(PyTorch3D 提供的)进行比较,以验证提出的可微分深度剥离算法的有效性。本文提出的可微分深度剥离算法和 PyTorch3D的实现都使用了与 Eq. (4) 相同的体积渲染方程。如表 6 所示,本文的方法比基于 CUDA 的方法快了超过 7 倍。
其他加速技术
-
“w/o fp16” 变体使用原始的 32 位浮点数进行计算。
-
“w/o K = 12” 变体在深度剥离算法中使用了 15 个渲染通道,与训练时相同。使用 16 位浮点数和 12 个渲染通道都可以实现 20FPS 的加速。
不同GPU和分辨率上的渲染速度 本文还报告了在不同硬件(RTX 3060、3090 和 4090)以及不同分辨率(720p、1080p 和 4K(2160p))上的渲染速度(见表 7)。这里报告的渲染速度包含了交互式 GUI 的开销(“w/ GUI”),因此略低于报告的速度。4K4D 即使在使用普通硬件渲染 4K(2160p)图像时也能实现实时渲染,如表中所示。
结论与讨论
本文提出了一种基于神经点云的表示方法,称为4K4D,用于实时渲染4K分辨率的动态3D场景。在4D特征网格上构建了4K4D,以自然地规范化点,并开发了一种新颖的混合外观模型,用于高质量渲染。此外,本文开发了一种可微分深度剥离算法,利用硬件光栅化流水线有效优化和高效渲染所提出的模型。在实验中,展示了4K4D不仅实现了最先进的渲染质量,而且在渲染速度上表现出了超过30倍的提升(在RTX 3090上,1080p分辨率超过200FPS)。
然而,本文的方法仍然存在一些局限性。4K4D无法生成跨帧的点对应关系,这对于某些下游任务至关重要。此外,4K4D的存储成本随视频帧数线性增加,因此在建模长体积视频时会面临困难。如何建模点对应关系和减少长视频的存储成本,可能是未来研究中的两个有趣问题。
参考文献
[1] 4K4D: Real-Time 4D View Synthesis at 4K Resolution















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









