








论文链接:https://arxiv.org/pdf/2402.17525
github链接:https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods
亮点直击
这篇综述旨在系统地分类和批判性地评估基于扩散模型的图像编辑领域的大量研究。
目标是提供一个综合性的资源,不仅能够综合当前的研究成果,还能指导这一快速发展的领域中的未来研究方向。
总结速览
解决的问题:
-
如何利用去噪扩散模型进行高质量的图像生成和编辑。
-
系统地分类和评估扩散模型在图像编辑中的应用。
提出的方案:
-
提供详尽的综述,涵盖扩散模型在图像编辑中的理论和实践。
-
提出系统的基准EditEval及创新指标LMM Score,用于评估文本引导的图像编辑算法。
应用的技术:
-
去噪扩散模型,用于逆转噪声过程生成高质量样本。
-
多模态条件方法和传统上下文驱动方法,应用于图像修复和扩展。
达到的效果:
-
为研究人员提供全面资源,系统分类研究成果。
-
指导未来研究方向,识别领域中的局限性和潜在创新机会。
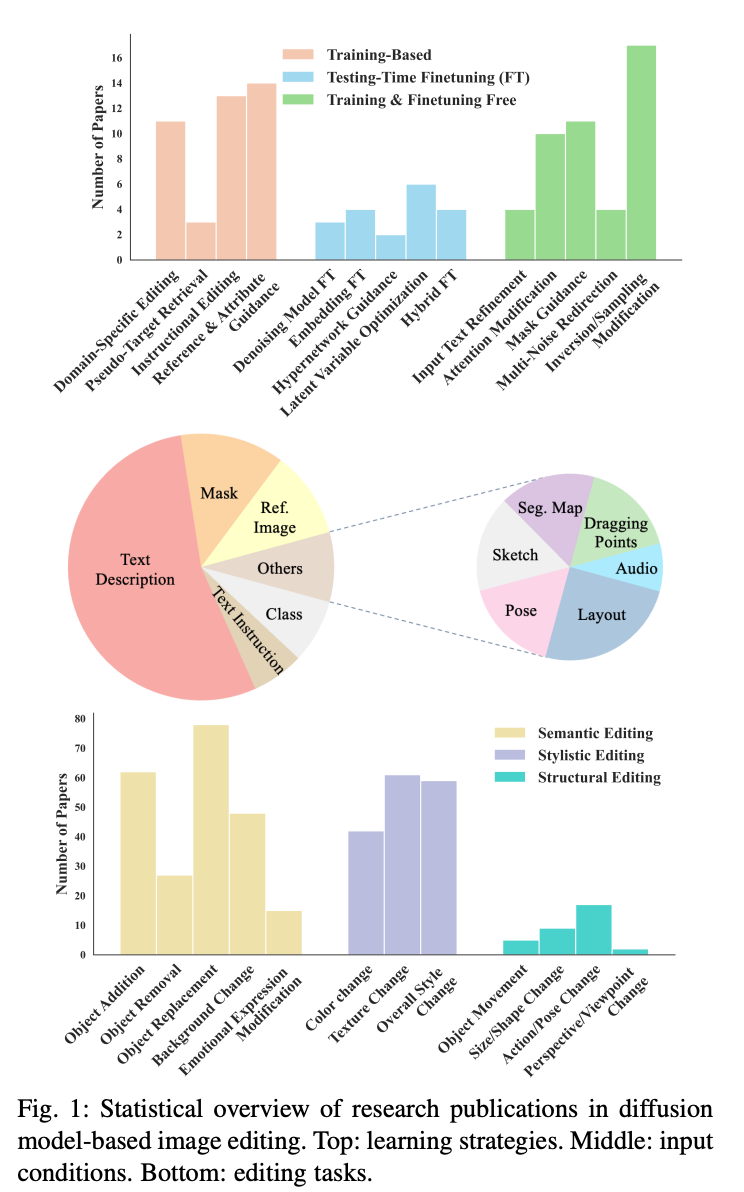
图像编辑的分类
除了扩散模型在图像生成、修复和增强方面取得的显著进展外,它们在图像编辑中也取得了显著突破,相较于之前占主导地位的GANs,提供了更好的可控性。与专注于从头创建新图像的图像生成以及旨在修复和提高退化图像质量的图像修复和增强不同,图像编辑涉及对现有图像在外观、结构或内容方面的修改,包括添加对象、更换背景和改变纹理等任务。
在这篇综述中,根据学习策略将图像编辑论文分为三大类:基于训练的方法、测试时微调的方法以及无需训练和微调的方法,分别在下文中详细阐述。此外,探讨了这些方法用于控制编辑过程的10种输入条件,包括文本、mask、参考(Ref.)图像、类别、布局、姿势、草图、分割(Seg.)图、音频和拖动点。
此外,调查了这些方法可以实现的12种最常见的编辑类型,并将其组织为以下定义的三个广泛类别:
-
语义编辑:此类别包括对图像内容和叙述的更改,影响所描绘场景的故事、背景或主题元素。此类别中的任务包括对象添加(Obj. Add.)、对象移除(Obj. Remo.)、对象替换(Obj. Repl.)、背景更改(Bg. Chg.)和情感表达修改(Emo. Expr. Mod.)。
-
风格编辑:此类别侧重于增强或改变图像的视觉风格和美学元素,而不改变其叙述内容。此类别中的任务包括颜色更改(Color Chg.)、纹理更改(Text. Chg.)和整体风格更改(Style Chg.),涵盖艺术风格和现实风格。
-
结构编辑:此类别涉及图像中元素的空间排列、定位、视点和特征的变化,强调场景中对象的组织和呈现。此类别中的任务包括对象移动(Obj. Move.)、对象大小和形状更改(Obj. Size. Chg.)、对象动作和姿势更改(Obj. Act. Chg.)以及透视/视点更改(Persp./View. Chg.)。
下表1全面总结了所调查论文的多视角分类,便于快速查找。
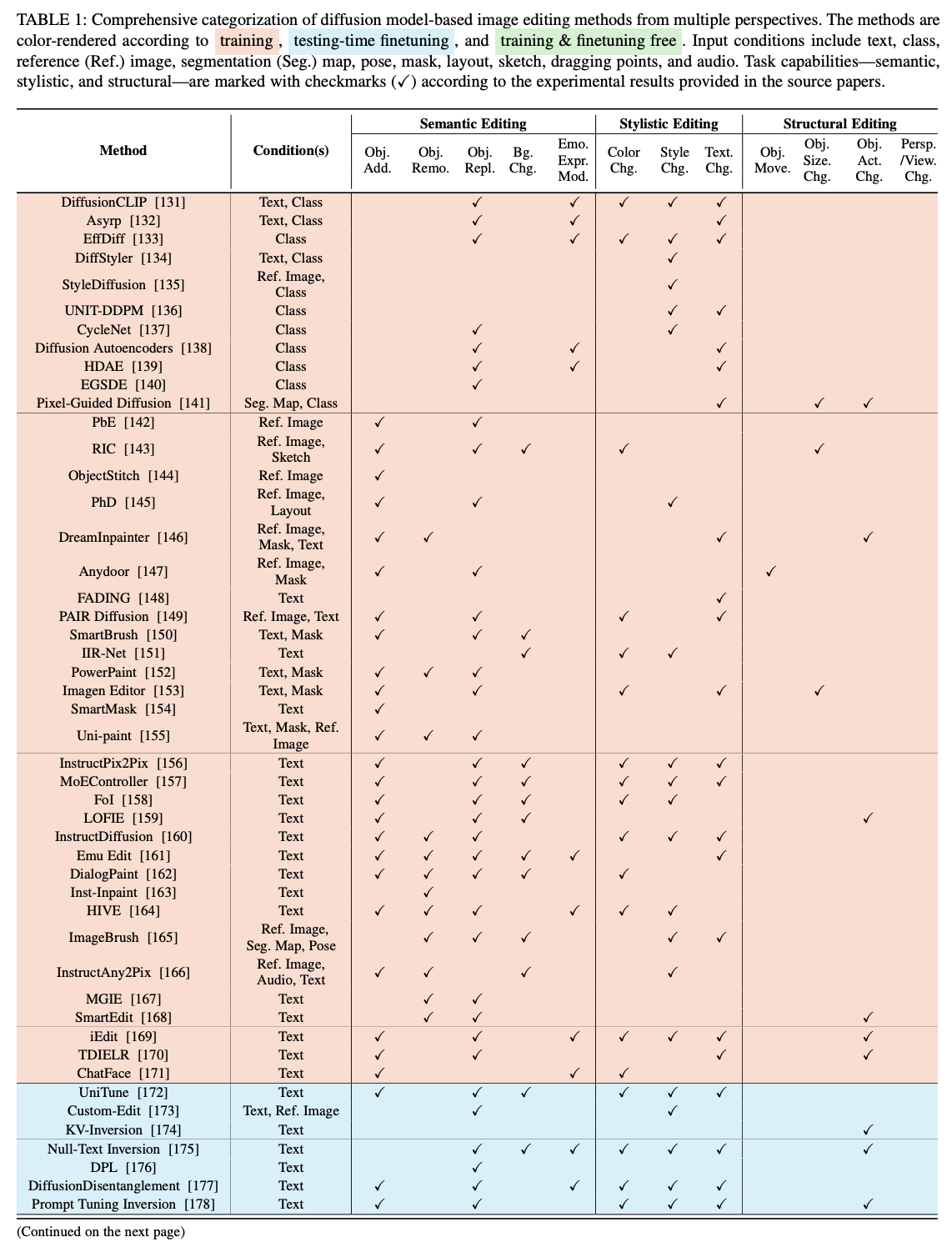
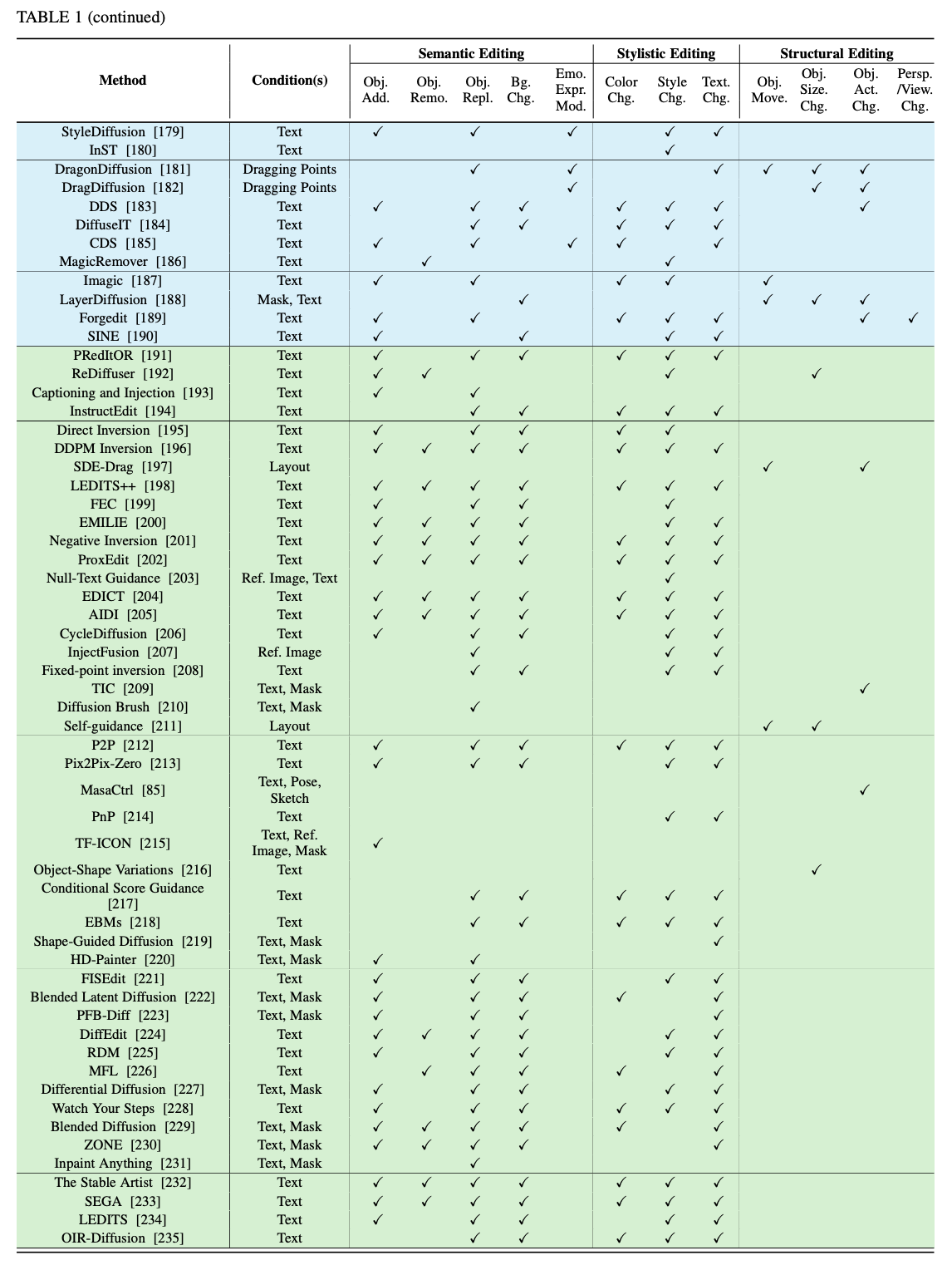
基于训练的方法
在基于扩散模型的图像编辑领域,基于训练的方法已获得显著关注。这些方法不仅因其在稳定训练扩散模型和有效建模数据分布方面的表现而引人注目,还因其在各种编辑任务中的可靠性能而受到重视。为了深入研究这些方法,根据其应用范围、训练所需条件和监督类型将其分为四大类,如下图2所示。此外,在每个主要类别中,根据核心编辑方法将其细分为不同类型。这种分类展示了这些方法的范围,从针对特定领域的应用到更广泛的开放世界用途。

弱监督下的特定领域编辑
在过去几年中,生成对抗网络(GANs)因其生成高质量图像的能力而被广泛应用于图像编辑。然而,扩散模型凭借其先进的图像生成能力,成为该领域的新焦点。扩散模型的一个挑战是在大数据集上训练时需要大量计算资源。为了解决这个问题,早期研究通过在较小的专用数据集上进行弱监督训练这些模型。这些数据集高度集中于特定领域,如用于人脸处理的CelebA和FFHQ,用于动物面部编辑和转换的AFHQ,用于对象修改的LSUN,以及用于风格转移的WikiArt。为了深入理解这些方法,根据其弱监督类型进行组织。
CLIP指导。受使用CLIP 进行文本引导图像编辑的GAN方法[240],[241]启发,多个研究将CLIP整合到扩散模型中。一个关键例子是DiffusionCLIP,它允许在训练和新领域中使用CLIP进行图像操作。具体来说,它首先使用DDIM反演将真实图像转换为潜在噪声,然后在反向扩散过程中微调预训练的扩散模型,通过源文本和目标文本提示之间的CLIP损失来调整图像属性。Asyrp 则专注于内部的语义潜在空间,称为h空间,在其中定义了由小型神经网络参数化的附加隐函数。然后,它在保持扩散模型冻结的情况下,在CLIP损失的指导下训练网络。DiffusionCLIP和Asyrp的简化流程的视觉比较如下图3所示。为了应对DiffusionCLIP中多步优化耗时的问题,EffDiff 引入了一种通过单步训练和高效处理的更快方法。

除了主要关注人脸编辑的方法之外,DiffStyler 和StyleDiffusion 针对艺术风格转移。DiffStyler使用CLIP指令损失来对齐目标文本描述和生成图像,同时使用CLIP美学损失来增强视觉质量。另一方面,StyleDiffusion引入了一种基于CLIP的风格解耦损失,以改善风格与内容的协调。
循环正则化。由于扩散模型能够进行域转换,因此在这些模型中也探索了像CycleGAN 这样的方法中常用的循环框架。例如,UNIT-DDPM在扩散模型中定义了一个双域马尔可夫链,使用循环一致性来正则化无配对图像到图像翻译的训练。类似地,CycleNet采用了以预训练的Stable Diffusion 为文本条件的ControlNet 作为骨干网络。在整个图像翻译循环中,它也使用了一致性正则化,这包括从源域到目标域的正向翻译以及反向方向的翻译。
投影和插值。在GANs中常用的一种技术是将两个真实图像投影到GAN的潜在空间中,然后在它们之间进行插值以实现平滑的图像操作,这一技术也被一些扩散模型用于图像编辑。例如,Diffusion Autoencoders引入了一个语义编码器,将输入图像映射到一个具有语义意义的embedding中,然后作为扩散模型重建的条件。在训练语义编码器和条件扩散模型后,任何图像都可以投影到这个语义空间中进行插值。然而,HDAE指出这种方法往往会丢失丰富的低级和中级特征。它通过增强框架以分层利用语义编码器和基于扩散的解码器的粗到细特征,旨在实现更全面的表示。
分类器引导。一些研究通过引入预训练的分类器进行引导来增强图像编辑性能。例如,EGSDE使用能量函数来指导采样,以实现逼真的无配对图像到图像翻译。该函数由一个时间相关的领域特定分类器和一个低通滤波器分别指定的两个对数势函数组成。对于细粒度图像编辑,Pixel-Guided Diffusion训练一个像素级分类器来估计分割图并用其梯度引导采样。
通过自我监督进行参考和属性指导
这类工作从单幅图像中提取属性或其他信息,以自监督的方式为基于扩散的图像编辑模型训练提供条件。它们可以分为两类:参考基础图像合成和属性控制图像编辑。
参考基础图像合成。为了学习如何合成图像,PbE 通过使用图像中对象边界框内的内容作为参考图像,边界框外的内容作为源图像,以自监督的方式进行训练。为了防止简单的复制粘贴解决方案,它对参考图像应用强增强,基于边界框创建任意形状的mask,并使用 CLIP 图像编码器压缩参考图像的信息,作为扩散模型的条件。在此基础上,RIC 将mask区域的草图作为控制条件进行训练,允许用户通过草图微调参考图像合成的效果。ObjectStitch 设计了一个内容适配器,以更好地保留参考图像的关键身份信息。同时,PhD 在冻结的预训练扩散模型上训练了一个修复和和谐模块,以有效引导mask区域的修复。为了保留参考图像的低级细节以进行修复,DreamInpainter 利用 U-Net 的下采样网络来提取其特征。在训练过程中,它向整个图像添加噪声,要求扩散模型在详细文本描述的指导下学习如何恢复清晰图像。此外,Anydoor 使用来自视频帧的图像对作为训练样本,以提升图像合成质量,并引入模块来捕捉身份特征、保留纹理和学习外观变化。
属性控制图像编辑。这类论文通常涉及增强预训练的扩散模型,并以特定图像特征作为控制条件来学习生成相应的图像。这种方法允许通过改变这些特定的控制条件进行图像编辑。经过年龄-文本-面部对的训练后,FADING 通过空文本反转和注意力控制进行年龄操控来编辑面部图像。PAIR Diffusion 将图像视为对象的集合,学习调节每个对象的属性,特别是结构和外观。SmartBrush 使用不同粒度的mask作为控制条件,使扩散模型能够根据文本和mask的形状修复mask区域。为了更好地保留与编辑文本无关的图像信息,IIR-Net 在所需区域执行颜色和纹理擦除。擦除后的图像被用作扩散模型的控制条件之一。
通过全面监督进行教学编辑
使用指令(例如,“去掉帽子”)来驱动图像编辑过程,而不是使用编辑后图像的描述(例如,“一只戴着帽子微笑的小狗”),似乎更自然、人性化,并且更符合用户的需求。InstructPix2Pix 是第一个学习根据人类指令编辑图像的研究。后续的研究在模型架构、数据集质量、多模态等方面进行了改进。因此,首先描述 InstructPix2Pix,然后根据其最显著的贡献对后续工作进行分类和展示。相应地,这些基于指令的方法的通用框架如下图 4 所示。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









