






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Increasing the LLM Accuracy for Question Answering: Ontologies to the Rescue!
这篇论文探讨了如何提高基于大型语言模型(LLM)的问答系统(QA)的准确性。目前的研究表明,与直接在SQL数据库上回答问题的系统相比,采用企业SQL数据库的知识图/语义表示的LLM-QA系统能获得更高的准确性。作者先前的基准研究显示,通过使用知识图,准确性可以从16%提高。本文提出了一种新方法,包括两个部分:基于本体的查询检查(OBQC)和LLM修复。OBQC通过利用知识图的本体来检查LLM生成的SPARQL查询是否与本体的语义相匹配,而LLM修复则使用LLM和错误解释来修复SPARQL查询。实验结果显示,该方法将整体准确性提高到了72%,比之前提高了8%,比直接在SQL上操作准确性高20%。这表明,引入本体,即知识图的语义表示,能够显著提高LLM驱动的问答系统的准确性。
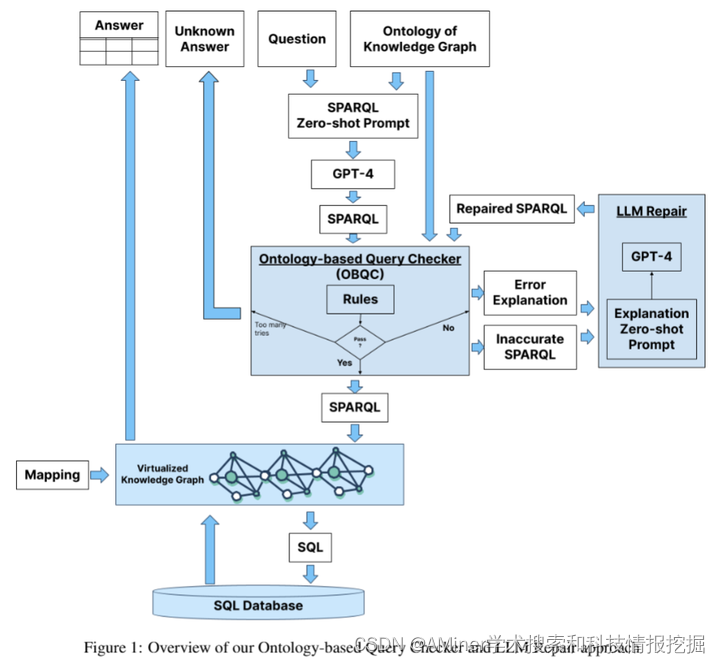
链接:https://www.aminer.cn/pub/664c008501d2a3fbfcde7278/?f=cs
2.Large Language Models Meet NLP: A Survey
这篇论文的摘要指出,尽管大型语言模型(如ChatGPT)在自然语言处理(NLP)任务中表现出了惊人的能力,但系统地研究它们在这一领域潜力的研究还相对较少。本研究旨在填补这一空白,探讨以下问题:(1)大型语言模型目前在NLP任务中是如何应用的?(2)传统NLP任务是否已经可以通过LLMs解决?(3)LLMs在NLP的未来方向是什么?为了回答这些问题,该论文首先为理解LLMs在NLP中的当前进展提供了一个统一的概述,并引入了一个统一的分类法,包括参数固定应用和参数调整应用。此外,该论文还总结了新的研究前沿及其相关挑战,旨在激发进一步的创新性进展。该论文希望为LLMs在NLP中的潜力和局限性提供有价值的见解,同时为构建有效的NLP LLMs提供实践指南。

链接:https://www.aminer.cn/pub/664d525901d2a3fbfc38a0fb/?f=cs
3.PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
文章指出,大规模语言模型(LLM)在理解能力上表现出惊人的水平,但在推理阶段面临GPU内存使用方面的挑战,这限制了它们在如聊天机器人等实时应用中的可扩展性。为了解决这一问题,研究者们将计算过的键值(KV缓存)存储在GPU内存中。现有的方法通过修剪预计算的KV缓存来减少内存使用,但它们忽视了层与层之间的相互依赖以及预计算过程中巨大的内存消耗。本文提出了一种新的方法PyramidInfer,该方法通过保留层级的关键词汇来压缩KV缓存,并基于注意力权重的一致性提取对未来世代有影响的重要键值。研究发现,影响未来世代的关键键值数量随着层级的降低而减少。实验证明,PyramidInfer方法在保持性能的同时,通过减少计算的键值数量显著节省了内存,并将吞吐量提高了2.2倍,与Accelerate方法相比,在KV缓存中减少了超过54%的内存消耗。
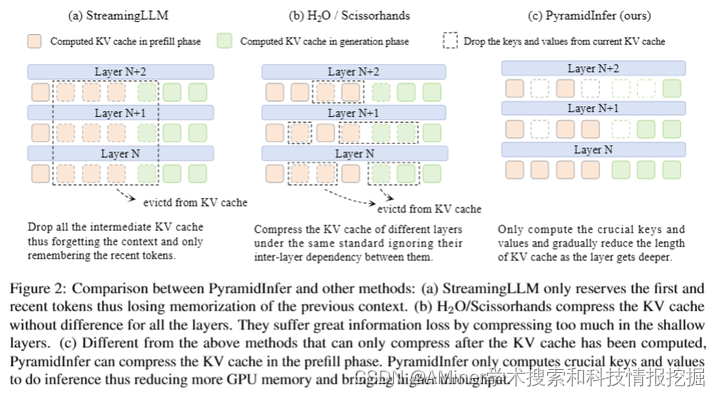
链接:https://www.aminer.cn/pub/664d525901d2a3fbfc38a036/?f=cs
4.Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
这篇论文介绍了一种名为Uni-MoE的新型多模态大型语言模型,它采用了混合专家(MoE)架构,能够处理多种模态。Uni-MoE的特点是具有用于统一多模态表示的模态特定编码器和连接器。为了提高训练和推理效率,研究团队在大型语言模型中实现了稀疏的MoE架构,通过模态级数据并行和专家级模型并行来实现。为了增强多专家之间的协作和泛化能力,提出了一种渐进式训练策略,包括使用不同连接器进行跨模态对齐,使用跨模态指令数据训练模态特定专家以激活专家偏好,以及利用低秩适应(LoRA)对混合多模态指令数据进行Uni-MoE框架调整。研究团队在多种多模态数据集上评估了指令调整后的Uni-MoE,实验结果表明,Uni-MoE在处理混合多模态数据集时能显著减少性能偏差,同时提高了多专家之间的协作和泛化能力。
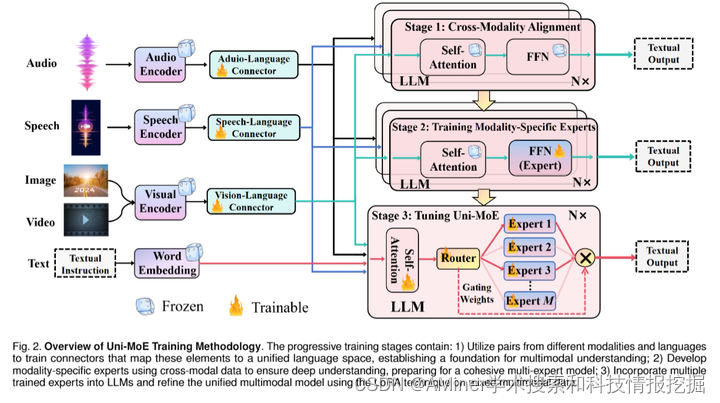
链接:https://www.aminer.cn/pub/664c008501d2a3fbfcde70b9/?f=cs
5.Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving
本文探讨了大型语言模型(LLMs)的元认知能力,即它们对自身思考和推理过程的直观知识。研究表明,当前最佳的LLMs不仅具有推理过程,也具备元认知知识,例如能够根据任务给出技能和程序的命名。文章主要在数学推理的背景下探讨这一点,开发了一种引导式交互程序,让一个强大的LLM给数学问题分配合理的技能标签,然后让它执行语义聚类以获得更粗略的技能标签家族。这些粗略的技能标签对人类来说是可解释的。为了验证这些技能标签对LLM的推理过程有意义且相关,文章进行了以下实验:(a) 要求GPT-4为数学数据集GSM8K和MATH中的训练问题分配技能标签。(b) 当使用LLM解决测试问题时,向它展示完整的技能标签列表,并要求它识别所需的技能。然后,它会被呈现与该技能标签相关联的随机选择的已解决示例问题。这提高了包括代码辅助模型在内的几个强大LLM在GSM8k和MATH上的准确性。文章提出的方法虽然应用于数学问题,但它是领域无关的。
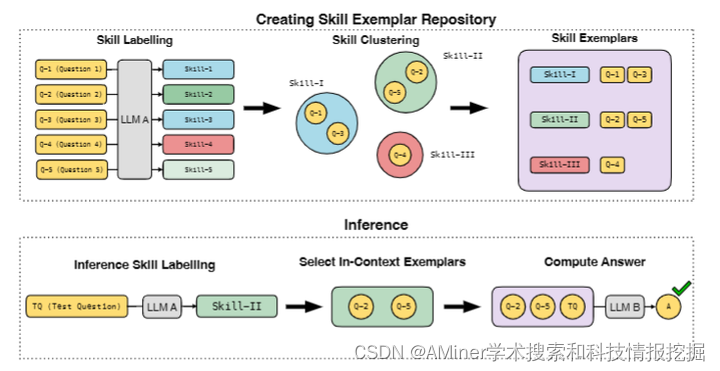
链接:https://www.aminer.cn/pub/664c009901d2a3fbfcde866d/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









