






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.LLMs for User Interest Exploration: A Hybrid Approach
本文介绍了一种混合层级框架,用于探索用户兴趣,该框架结合了大型语言模型(LLMs)和经典的推荐模型。传统的推荐系统通过学习过去的用户-项目交互并加强这些交互,从而受到强烈的反馈循环的限制,这反过来限制了新颖用户兴趣的发现。为了解决这个问题,本文提出了一个混合层级框架,该框架通过"兴趣簇"来控制大型语言模型和经典推荐模型之间的接口。“兴趣簇"的粒度可以由算法设计者明确确定。该框架通过首先使用语言表示"兴趣簇”,然后使用微调的LLM生成严格属于这些预定义簇的新颖兴趣描述。在低层次,它将这些生成的兴趣 grounded 到项目级策略中,通过限制经典推荐模型(在此案例中是一个基于 transformer 的序列推荐器),使其返回属于由高层次生成的簇的项目。作者在服务于数十亿用户的工业级商业平台上展示了这种方法的有效性。现场实验表明,这种方法在探索新颖兴趣和提高平台整体用户满意度方面取得了显著增长。
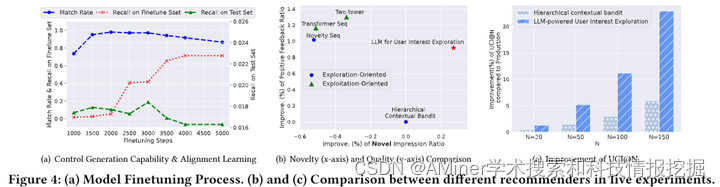
链接:https://www.aminer.cn/pub/66553aff01d2a3fbfc9fce9d/?f=cs
2.NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
本文介绍了NV-Embed模型,这是一种改进的大语言模型(LLM)通用嵌入模型。与基于BERT或T5的嵌入模型相比,仅解码器的大语言模型在通用文本嵌入任务上表现越来越好,包括基于密集向量的检索。作者通过多种架构设计和训练方法来提高LLM作为多功能嵌入模型的性能,同时保持其简洁和可复现性。在模型架构方面,提出了隐性注意力层来获取池化嵌入,这比均值池化或使用LLM的最后一个标记嵌入一致地提高了检索和下游任务的准确性。为了增强表示学习,去掉了LLM在对比训练期间的因果注意力掩码。在模型训练方面,引入了两阶段对比指令调优方法。第一阶段在检索数据集上应用对比训练,利用批量负样本和精心筛选的难负样本。在第二阶段,将各种非检索数据集融入指令调优,这不仅提高了非检索任务的准确性,也提高了检索性能。结合这些技术,使用仅 publicly available 数据的NV-Embed模型,在Massive Text Embedding Benchmark (MTEB)上取得了记录高分的69.32,排名第一,包括56个任务,涵盖检索、重排序、分类、聚类和语义文本相似性任务。值得注意的是,该模型在MTEB基准(也称为BEIR)的15个检索任务上也获得了最高的59.36分。
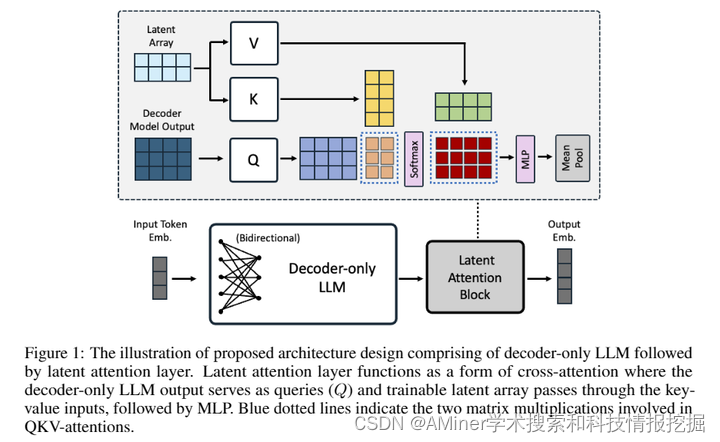
链接:https://www.aminer.cn/pub/665556f401d2a3fbfcdca611/?f=cs
3.Devil’s Advocate: Anticipatory Reflection for LLM Agents
本文介绍了一种新方法,该方法为大型语言模型(LLM)智能体提供了自我反思的能力,从而在解决复杂任务时增强了智能体的一致性和适应性。该方法促使LLM智能体将给定任务分解为可管理的子任务(即制定计划),并持续反思其行动的适用性和结果。我们实现了一种三重的自我反思干预:1)在执行行动之前,对可能的失败和替代补救措施进行预期反思,2)在行动后与子任务目标对齐,并根据需要回溯补救措施,以确保在计划执行中做出最大努力,3)在计划完成后进行全面审查,以改进未来的策略。通过在WebArena中部署和实验这种方法(一种零样本方法),用于Web环境中的实际任务,我们的智能体表现出优于现有零样本方法的性能。实验结果表明,我们以自我反思为驱动的方法不仅通过执行计划的强大机制增强了智能体应对未预见到挑战的能力,而且还通过减少完成任务所需的试验和计划修订次数提高了效率。
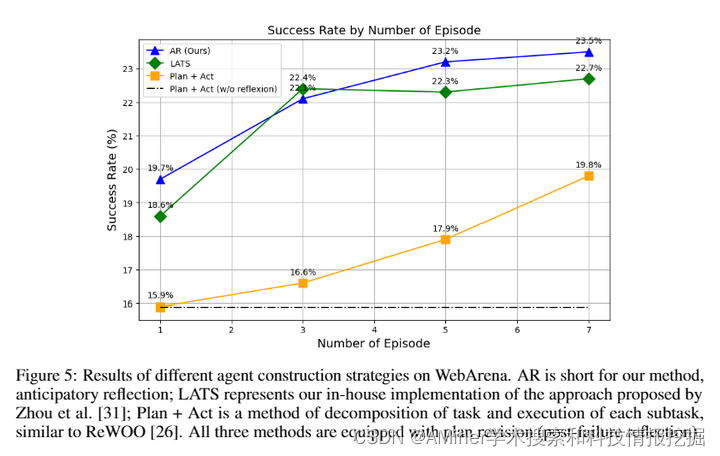
链接:https://www.aminer.cn/pub/66553aff01d2a3fbfc9fce71/?f=cs
4.Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
这篇论文探讨了大型语言模型(LLM)是否能够用自然语言忠实地表达它们固有的不确定性。作者认为,如果LLM对于同一个问题给出两个相互矛盾的答案的可能性相等,那么它生成的回答应该反映出这种不确定性,比如通过对其答案进行限定(例如,“我不确定,但我觉得…”)。作者将忠实响应不确定性形式化为模型对其所做断言的内在信心与其传达的决断性之间的差距。这种示例级别的度量可以可靠地表明模型是否反映了其不确定性,因为它同时惩罚过度和不足的限定。作者在几个知识密集型的问题回答任务上评估了各种对齐的LLM表达不确定性的能力。研究结果表明,现代LLM在忠实地传达它们的不确定性方面表现得很差,需要更好的对齐以提高它们的可靠性。
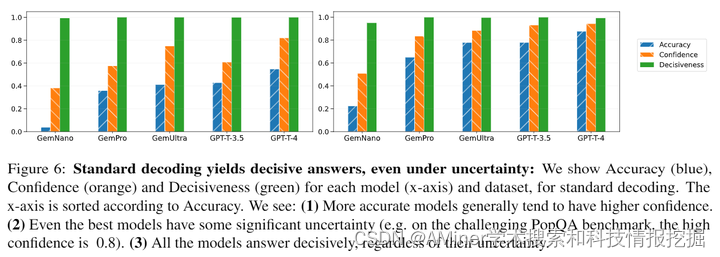
链接:https://www.aminer.cn/pub/66553aff01d2a3fbfc9fd109/?f=cs
5.Distributed Speculative Inference of Large Language Models
这篇论文介绍了一种名为分布式投机推理(DSI)的新分布式推理算法,该算法在大型语言模型(LLM)的推理加速方面比投机推理(SI)和传统的自回归推理(非-SI)都要快。与其他SI算法一样,DSI适用于冻结的LLM,无需训练或架构修改,同时保留了目标分布。尽管之前的研究在SI方面取得了实证加速效果(与非-SI相比),但通常需要一个快速且准确的草稿LLM。然而,实际中,现成的LLM通常没有与之匹配的足够快且准确的草稿师。论文指出,当使用较慢或不太准确的草稿师时,SI的性能会低于非-SI。作者通过证明DSI在任何草稿师下都比SI和非-SI快来填补这一差距。通过协调目标和草稿师的多实例,DSI不仅比SI快,而且还支持不能通过SI加速的LLM。论文中的模拟实验显示,在现实环境中,DSI可以使现成的LLM推理速度提高1.29-1.92倍。
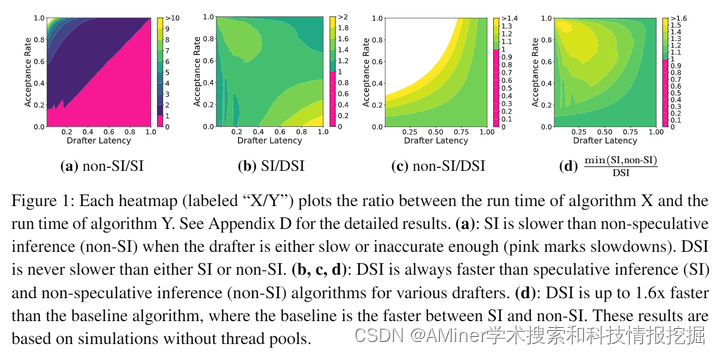
链接:https://www.aminer.cn/pub/664ff4d301d2a3fbfc51cf28/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









