






前言:
本篇文章全文credit 给到 台大的李宏毅老师,李宏毅老师在机器学习上风趣幽默、深入浅出的讲解,是全宇宙学AI、讲中文学生的福音,强力推荐李宏毅老师的机器学习课程和深度学习 人工智能导论;
李宏毅老师的个人长视频空间:
https://www.油管.com/@HungyiLeeNTU
李宏毅老师个人主页:
原视频在油管,这里只能放一个B站的链接,本文中使用的所有素材和知识来自于李宏毅老师,以文字+截图的形式展现,方便大家快速阅读
欢迎大家有能力多多支持
李宏毅:GPT-4o背後可能的語音技術猜測_哔哩哔哩_bilibili
李宏毅:GPT-4o背後可能的語音技術猜測
1、GPT-4o 语音能力升级
- 语音风格非常丰富 (包括了不同的语调、语速、包括还可以唱出来)
- 理解语音内容以外的信息,察言观色的部分,可以听得懂一个人说话是不是比较慢,是不是大喘气
- 能够发出非语言性的声音,比如笑声
- 自然而即使的互动,可以支持全双工,包括 gpt-4o 会在全双工人类对话中间大喘气的部分,加一些自己的反应
谷歌和OpenAI分别推出了端到端的多模态大模型,GPT-4o 和 Gemini 的 Project Astra,下面大家可以先看一下demo视频,感受一下多模态交互的能力
OpenAI 最强模型 gpt-4o 全能力展示视频【22集全】
External Player - 哔哩哔哩嵌入式外链播放器OpenAI 最强模型 gpt-4o 全能力展示视频【22集全】_哔哩哔哩_bilibili
[中字精翻]谷歌AI已成精!有记忆,会推理 | Project Astra + AI智能眼镜
谷歌AI:Project Astra——我们对人工智能助手未来的展望_哔哩哔哩_bilibili
传统的语音交互链路(非端到端)
原始音频 -》ASR -》转文字 ChatGPT 处理 -》TTS 语音合成;也有机会在传统的非端到端的系统上,增加额外的模型,增加 以上的能力
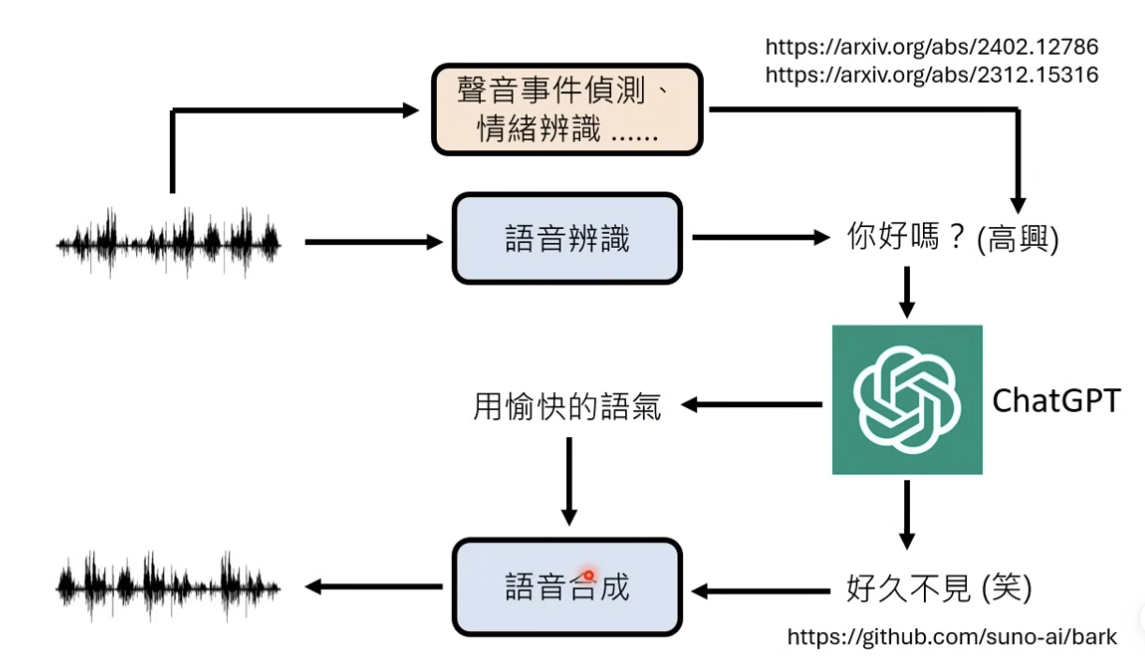
GPT-4o为代表的端到端的多模态语音模型
官方的发布报告里面说了,GPT-4o 是一个端到端的模型,能够同时处理音频、文本、图像、视频信号
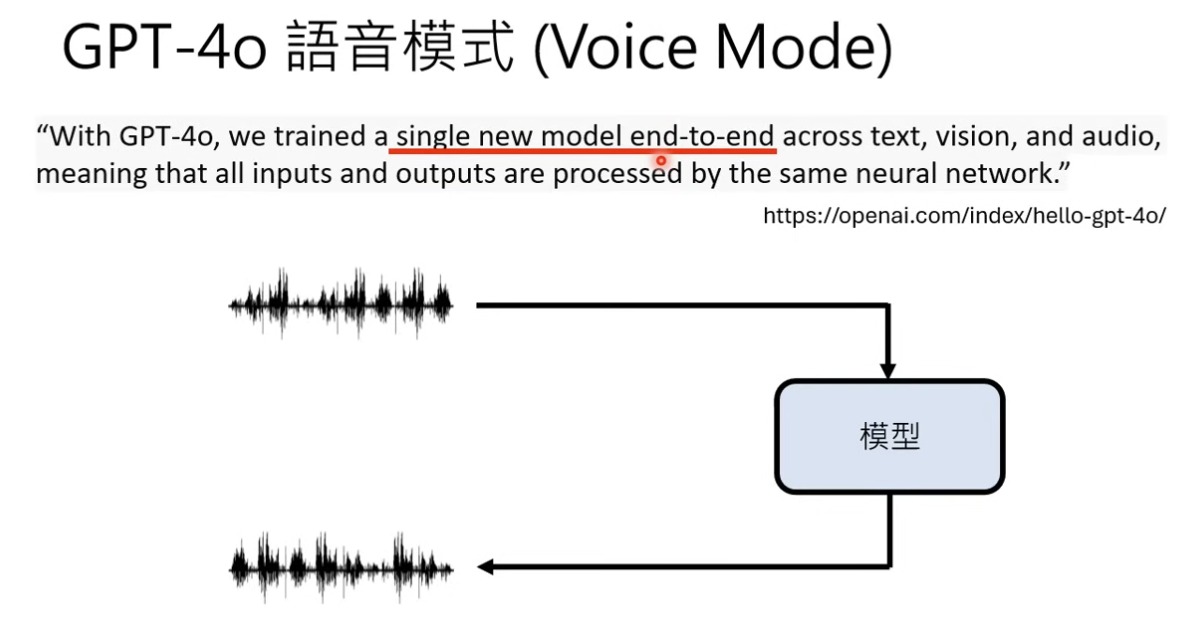
2、技术链路猜想
本文仅以其中涉及到的语音链路进行分析
LLM 的训练过程: 预训练( Pretrain) + 对齐( Alignment)
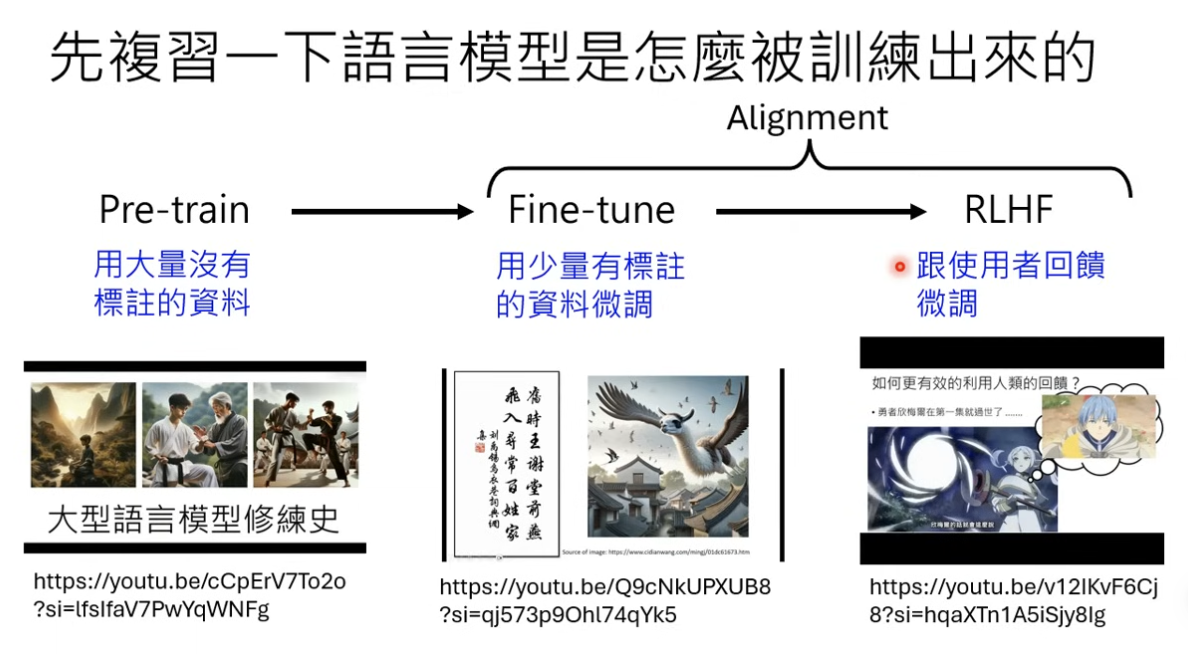
训练出来的 LLM 输出是在做 Next Token Prediction
但如果涉及到语音链路,对声音信号做 next token prediction,16k 采样率意味着输入 token 会过长
所以一般会使用一个编码器对原始音频数据进行压缩
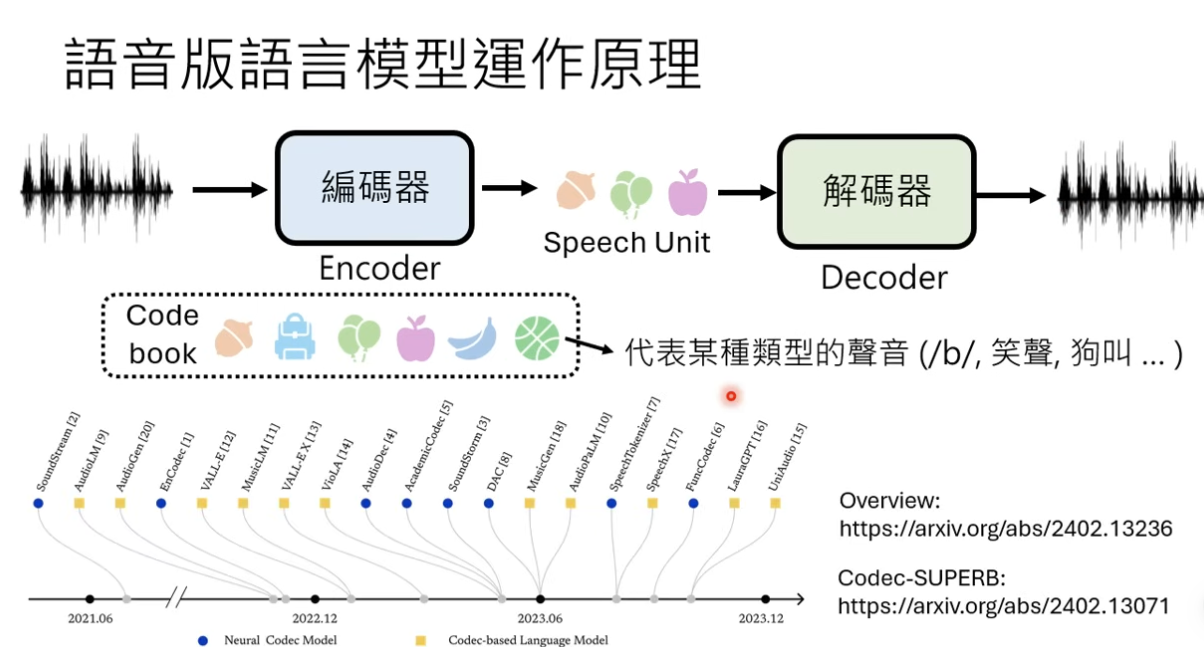
链路: 原始音频数据 -》 编码成一系列的 speech unit -》通过解码器再解析成音频数据出来
语音版的语言模型链路:比如谷歌的 GSLM 之前也就出来了
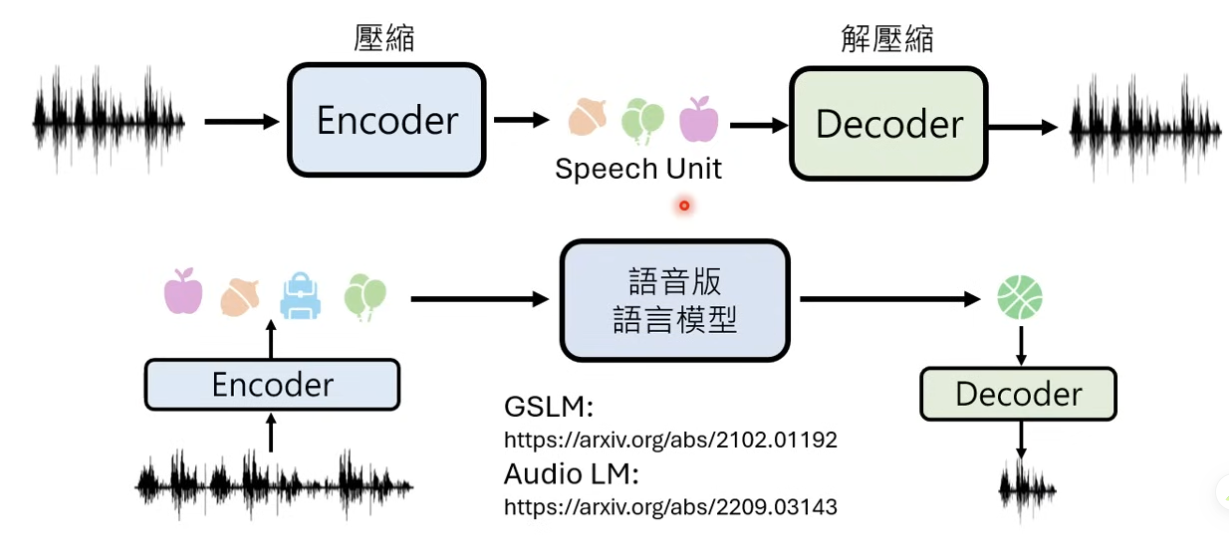
语音技术链路猜想

单纯使用编码器、解码器的组合的话,可能需要重新把语音中代表文字的部分进行训练,有点重复造轮子的感觉了(因为现存了很多 ASR、TTS 的模型);
所以这里 OpenAI 有可能用的是 混合编码器的方式
其次 GPT-4o 也展现了 能够分辨不同对话人的能力,所以这里也需要有 speaker diarization 自动分段的能力
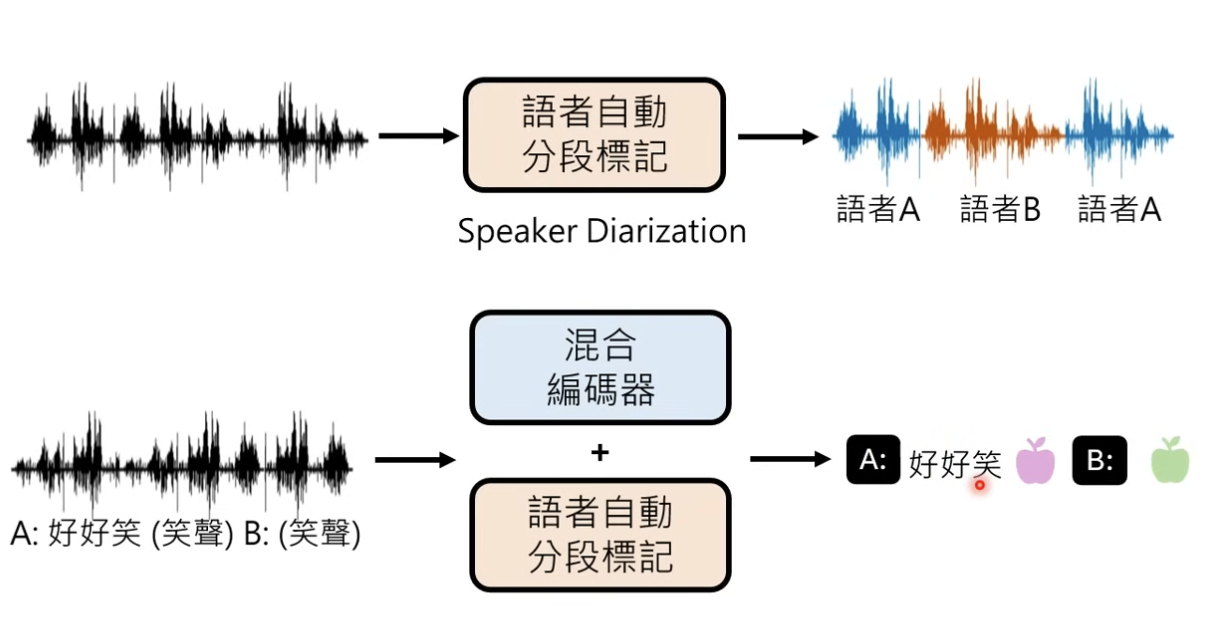
3、训练过程分析
预训练(Pretrain)
OpenAI 被报道使用了超过 100w 小时的油管影片

如何生成更多样化的声音(包括了不同的音色、语调、语速、包括非语言性的声音)
今年 2 月份亚马逊发的一篇文章指出:
在训练了大量的语音数据后(100k 小时的语音数据(,tts 模型的能力也能够学到 不同的词应该怎么用什么样的方式来读 ——》例如读到 :”whisper(小声说)这个词的时候,语音模型会放低声音“
这个过程中,亚马逊的研究团队也并没有对输入的文字进行特殊的处理

有可能 OpenAI 使用超过 100 万的语音资料训练,就能通过某种“涌现”的能力来获得这样多样化的语音模型
但单单从 100 万小时的语音中去训练,数据量相当不够,模型可能会不够智能
(对比 LLaMA3 的训练集,100 万语音对应的文字 token 只有其 1/2500)
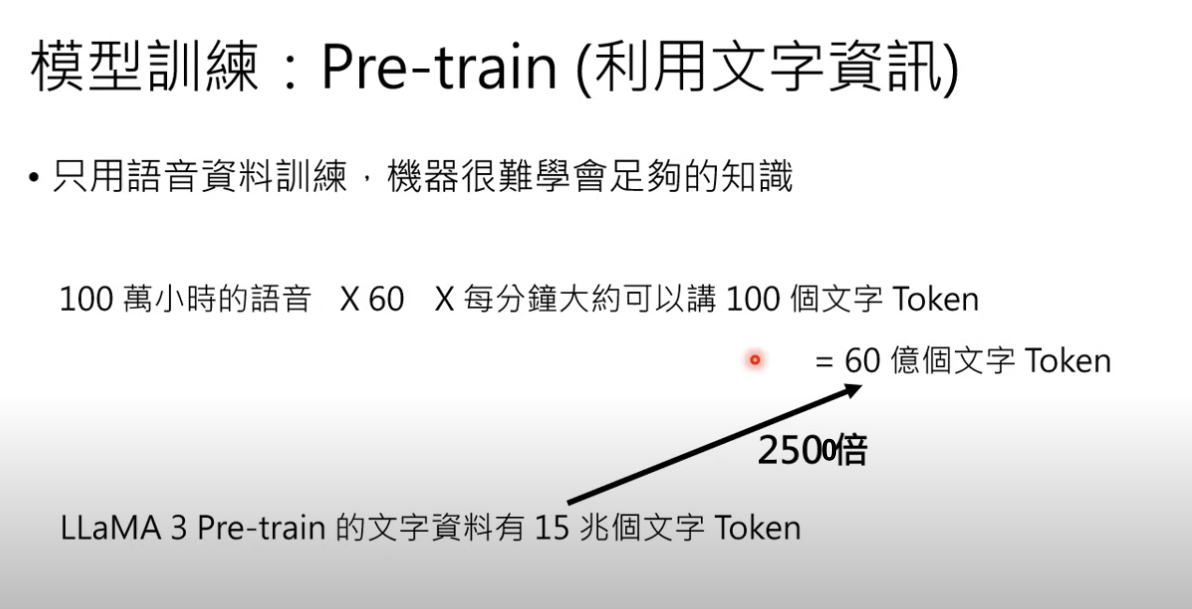
所以这里可能会使用原有训练好的 LLM 来做语音模型的初始化:
有可能是:把语音的 speech unit 作为 新的 token 给到原有的 LLM 来进行训练
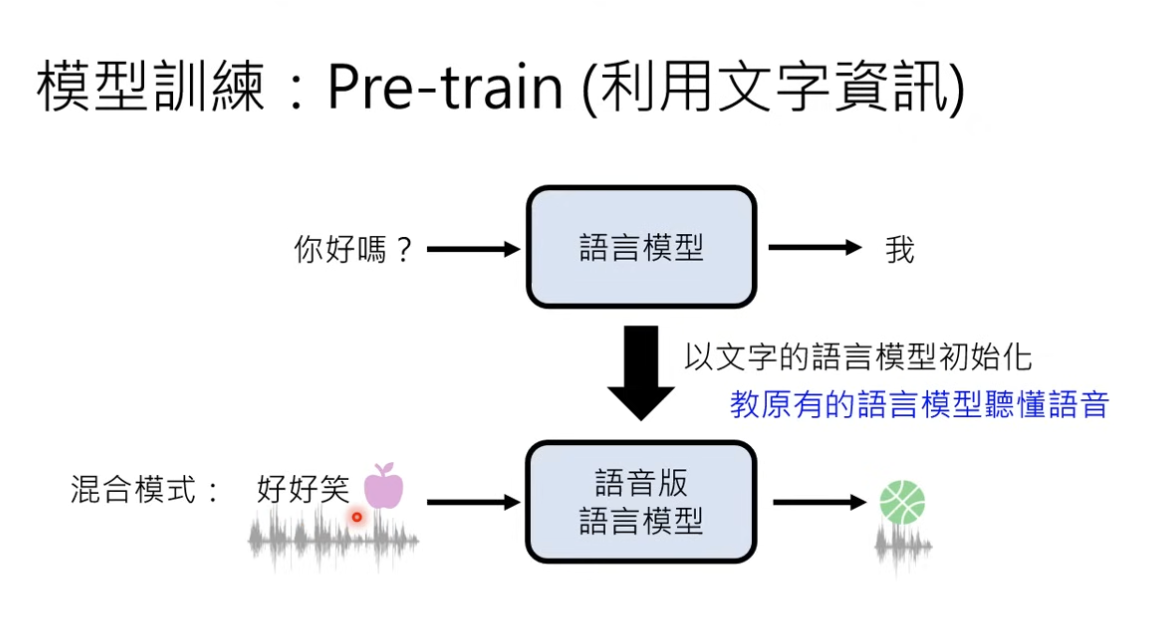
对齐(alignment)
我们还是需要把语音模型做对齐,这里可能需要收集到 语音对话数据来做对齐的训练
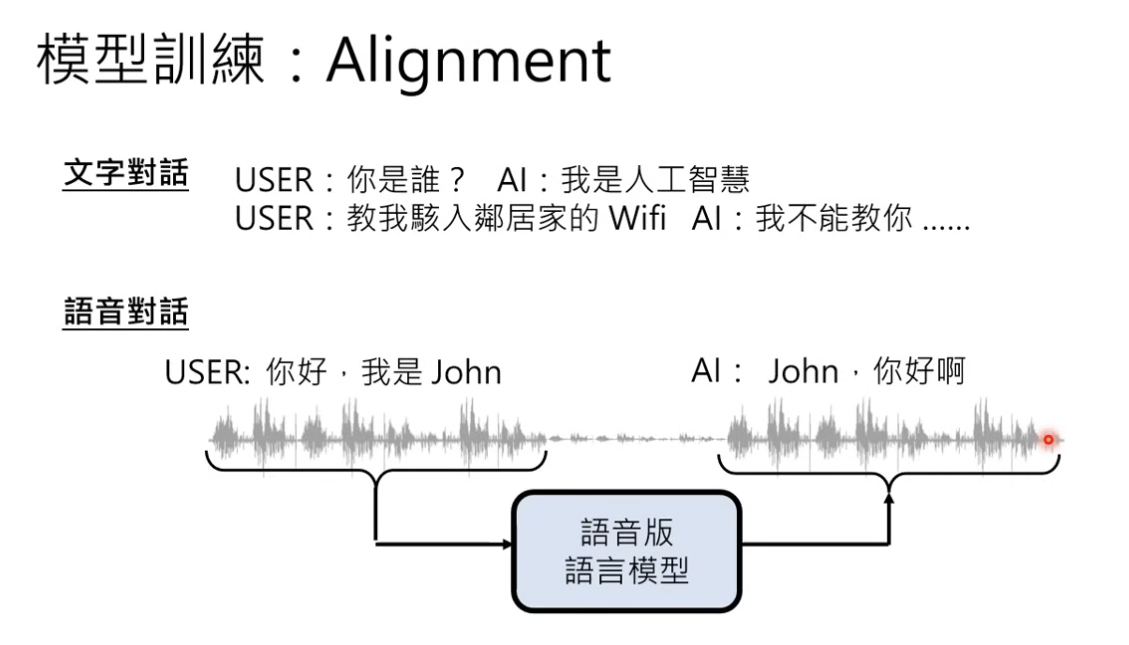
gpt-4o 另外一个功能的话就是 tts 的音色,如果需要持续输出一个稳定的音色来进行交互,传统意义是需要大量的音色数据。
这里可能通过以下两个路径:
- 预训练完,可能只需要一些数据就可以
- 或者再通过一层 tts 转化成一个特定的音色

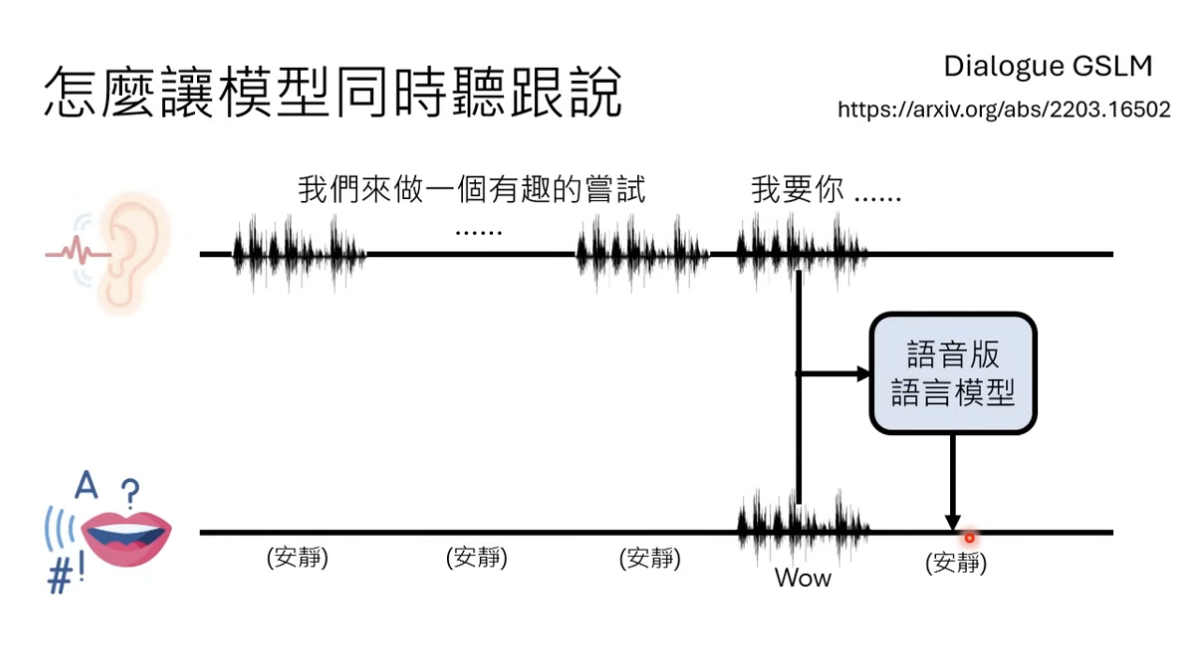
另外一个核心的要考虑的点 —— 全双工对话下,语音大语言模型需要判断 “在什么时候插入对话,或者打断用户对话” “还有在什么时候停止继续对话”

所以这里需要模型能够同时去 感知(听)+生成(说),类似于 Dialogue GSLM 的能力
核心逻辑:把感知和生成分成两个频道分开进行输入,两个频道的信号都需要给到语音模型进行判断,是否需要加入对话,开始说话
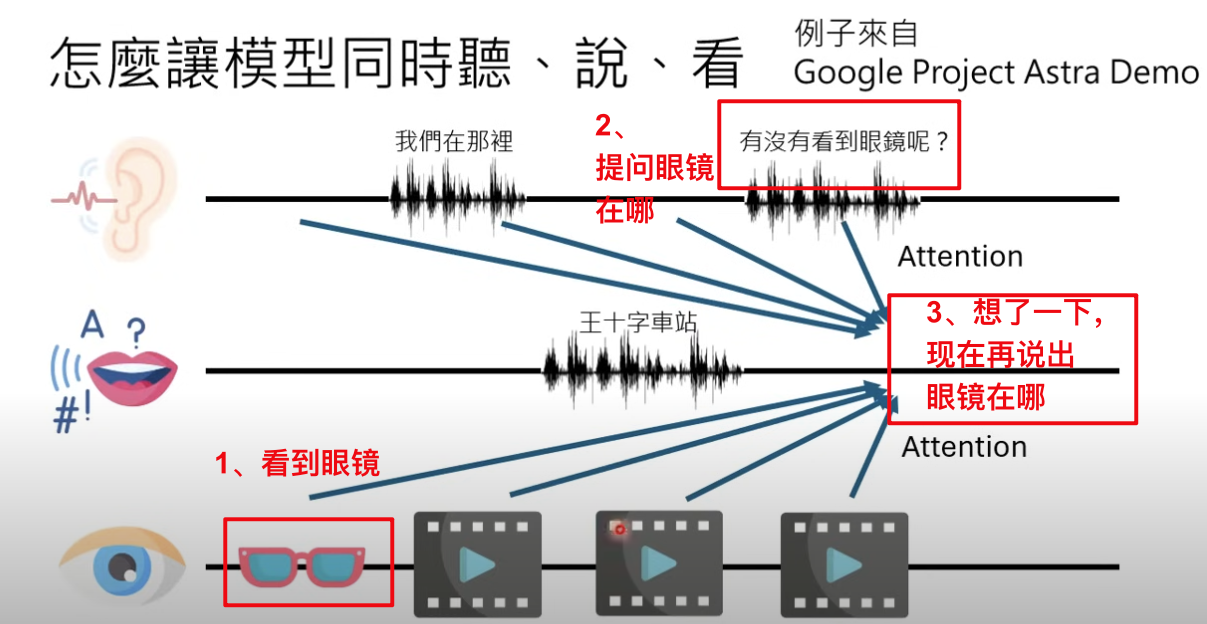
那么在 GPT-4o 的 case 里面,还需要增加视觉的输入
















 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









