







近日,Anthropic公司正式推出了两款全新AI模型:Claude 3.5 Sonnet (new) 和 Claude 3.5 Haiku。这次更新不仅显著提升了模型性能,还突破性的引入了计算机使用功能,标志着AI技术的一次重大飞跃。
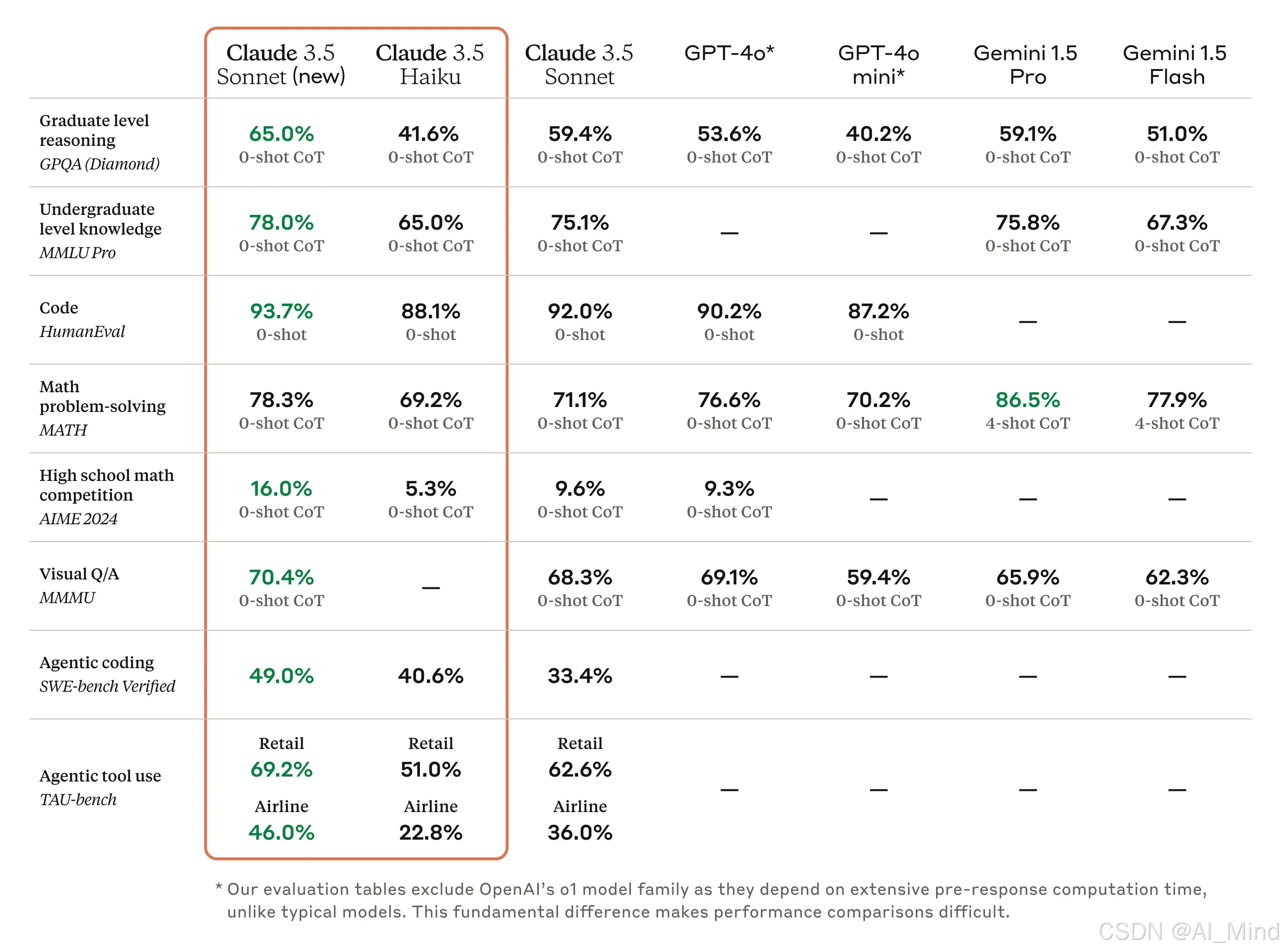
Claude 3.5 Sonnet (new) 在各个领域都超越了前代版本,尤其是在它擅长的编程领域和工具使用任务中取得了显著进展。
- 在编程领域,Claude 3.5 Sonnet (new) 在 SWE-bench Verified 测试中的得分从 33.4% 提升到了 49.0%,超越了所有公开可用的模型,包括 OpenAI o1-preview 等推理模型和专门为智能体编码设计的系统。
- 在 TAU-bench 代理工具使用任务中,Claude 3.5 Sonnet (new) 在零售领域得分从 62.6% 提升到了 69.2% ;在更具挑战性的航空公司领域得分从 36.0% 提升到了 46.0%。
- Claude 3.5 Sonnet (new) 在发布前经过了美国 AI 安全研究所(US AISI)和英国安全研究所(UK AISI)的联合测试,确保了模型的可靠性和安全性。
Claude 3.5 Sonnet (new) 最引人注目的是计算机使用功能。通过 Sonnet API,Claude 3.5 Sonnet (new) 能够像人类一样操作计算机,包括查看屏幕、移动光标、点击按钮和输入文本。该功能的工作原理主要包括以下四个步骤:
- 明确工具和任务
- Claude选择使用工具
- 提取工具信息,运行工具并返回结果
- 继续使用工具直到完成任务
Claude 3.5 Sonnet (new) 作为首个支持计算机使用能力的 AI 模型,该功能仍处于实验阶段,仍然存在一定的局限和错误:
- 速度和准确性问题:Claude 的计算机使用仍然很慢,而且经常容易出错。
- 操作种类有限:人们经常使用计算机执行许多操作(拖动、缩放等), Claude 还无法实现。
- 翻书式的屏幕观察:Claude 截取屏幕视图并将它们拼凑在一起,而不是观察更精细的视频流 ,这意味着它可能会错过短暂的操作或通知。
Claude 3.5 Sonnet (new) 的定价如下:
- 正常使用:输入$3/100万token,输出$15/100万token
- 命中缓存:输入$3.75/100万token,输出$0.30/100万token
Claude 3.5 Sonnet (new) 现已正式上线于网页和 App,并支持通过 Anthropic API、Amazon Bedrock 和 Google Cloud 进行调用。
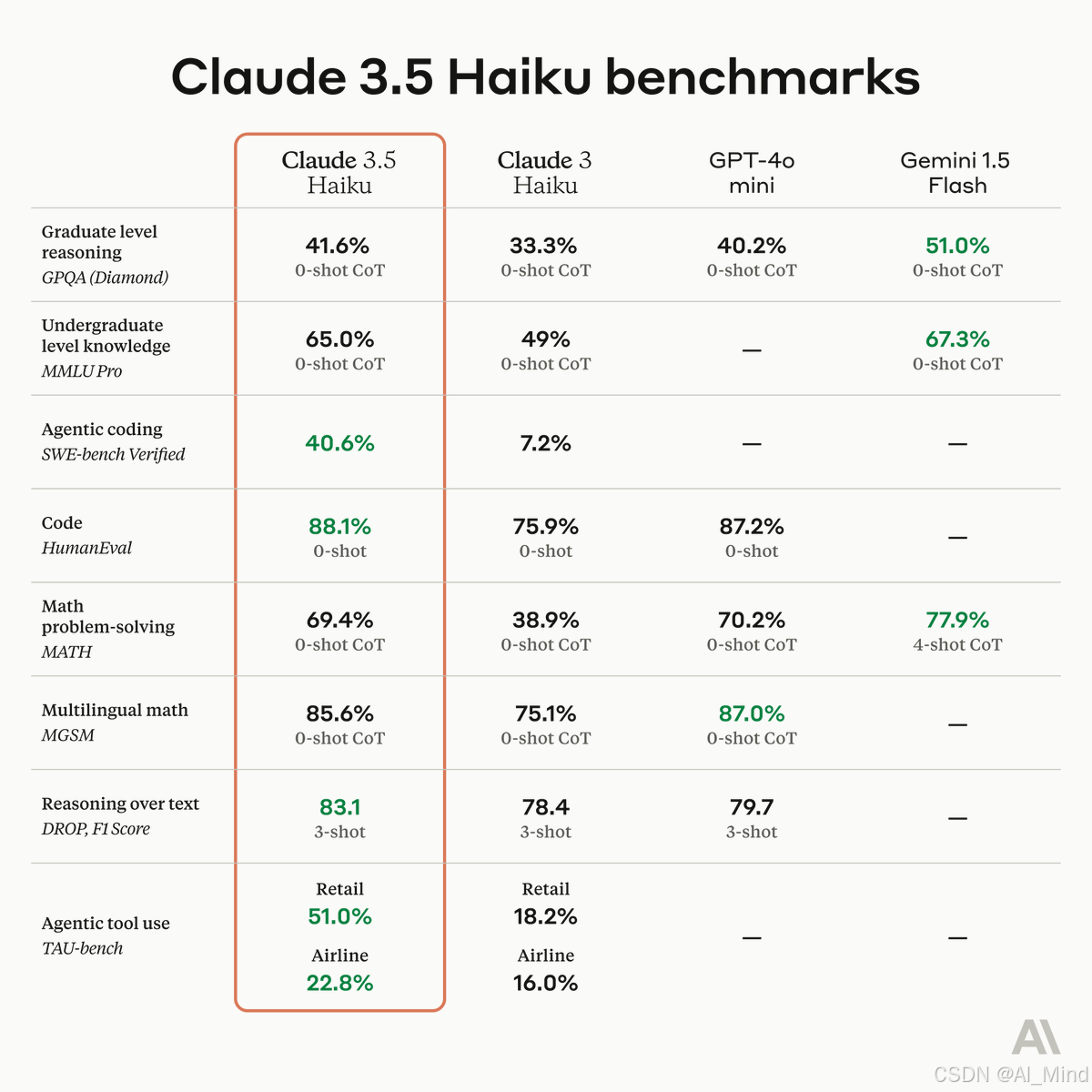
Claude 3.5 Haiku 是 Anthropic 最快模型的下一代版本。它在保持与前代相同成本和速度的同时,性能达到了前代最强模型 Claude 3 Opus 的水平,甚至在多项测试中超越了 GPT-4o-mini。
- 在编程任务中,Claude 3.5 Haiku 在 SWE-bench Verified 测试中的得分达到了 40.6%,超越了多款公开可用的顶尖 AI 模型,包括原版 Claude 3.5 Sonnet 和 GPT-4o。
- Claude 3.5 Haiku 凭借低延迟、出色的指令理解能力和更精准的工具使用能力,非常适合拿来开发用户产品、处理子智能体任务,或从海量数据(如购买记录、价格或库存信息)中生成个性化体验。
Claude 3.5 Haiku 的定价如下:
- 正常使用:输入 $1/100万token,输出 $5/100万token
- 命中缓存:输入 $1.25/100万token,输出 $0.1/100万token
AIdamoxing1Claude 3.5 Haiku 是最快、最具成本效益的模型,初期将以纯文本模型形式提供,后续将支持图像输入。
计算机使用技术的引入为 AI 的发展开辟了新的方向。这项技术使得 AI 能够直接与现有的软件和操作系统进行交互,类似于一个虚拟助手在用户界面上进行操作,而不再局限于模型调用预设的 API 或特定的指令。这种“计算机使用”概念不仅突破了传统的大型语言模型(LLM)的开发模式,也为用户带来了更自然的人机交互体验。随着这项技术的发展,它将迅速成熟并为用户提供更高的效率、灵活性和便利性。

















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









