







Unified Cross-Modal Attention: Robust Audio-Visual Speech Recognition and Beyond
作者列表:李嘉鸿,李晨达,吴逸飞,钱彦旻
论文原文:https://ieeexplore.ieee.org/document/10472123

扫码直接看论文
背景动机
方案
基于统一跨模态注意力机制的音视频联合语音识别系统
我们所提出的基于统一跨模态注意力机制(Unified Cross-Modal Attention)的音视频联合语音识别系统如图1所示。图中上半部分为用于音视频多模态语音识别的主干网络,音频信号与视觉信号(本文中特指唇部区域的帧序列)共同构成模型输入,声学的前端处理包括FBank特征提取和频谱上的2维卷积映射,视觉的前端处理则包含视频级别的3维卷积操作以及帧级别的ResNet网络和Bi-LSTM网络。前端输出的深层特征表征经过模态向量(Modality Embedding)和位置编码(Positional Encoding)后,将在时间序列上进行拼接。由12层Conformer网络构成的编码器会在统一特征空间内对音视频特征同时进行卷积和注意力机制的加工,输出的隐层表征中对应音频模态的部分则会经过CTC和Transformer解码器进行语音识别,进而利用交叉熵损失函数对模型参数进行优化。
在统一跨模态注意力机制下,相比于纯音频的语音识别系统,我们的多模态系统仅增加了视觉前端中的少量模型参数,并且编码器可以在同一特征空间中对两种模态的表征进行融合,其中模态向量能够帮助区分两种模态,而独立的位置编码可以额外提供模糊的模态间时序对齐信息。在训练过程中,我们在视觉模态上引入了Modality Dropout,将训练任务依概率退化为纯音频识别任务,从而降低训练难度,加速模型收敛。
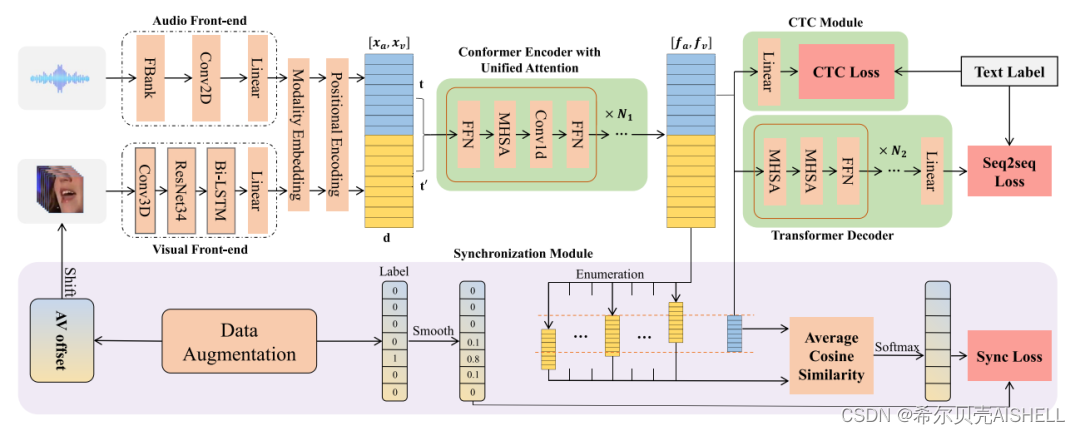 图1 音视频联合语音识别系统框架示意图
图1 音视频联合语音识别系统框架示意图
音视频同步性感知训练
音视频不同步的情况是音视频联合语音识别系统在实际应用中面临的巨大挑战。尽管我们的模型中没有进行显式的音视频帧同步操作,但编码器仍会自动学习到模态间的时间对应信息,因此明显的音画不同步现象会严重影响模型性能。针对这个问题,我们引入了图1中下半部分所示的音视频同步性感知训练框架。对于潜在的音画不同步数据,模型将枚举特定范围[-r,r]内的所有偏移量,并根据每个偏移量对编码器输出的两种模态特征进行偏移矫正和强制对齐,从而计算出每个偏移量下音视频帧的平均余弦距离。具体实现如图2所示。

图2 音视频同步性感知训练伪代码
在训练阶段中,我们随机采样并模拟了不同偏移程度的音视频数据,将偏移量表示为one-hot编码并进行相邻一帧范围内的平滑,从而构成训练标签。模型输出的余弦距离则会经过softmax转换为各个偏移量的概率预测,并与训练标签计算交叉熵损失函数。这个损失函数可以将音视频不同步的误差反向传播到编码器中,从而引导注意力网络感知模态间的对齐线索,进而缓解输入层面的不同步所带来的性能损失。
除此之外,上述过程在推理阶段中还可以直接预测出输入数据的偏移量。根据此预测值,我们可以人工矫正输入的音视频数据,这样就可以再次输入任意的识别网络进行二次推理,从而最大程度地抑制音视频不同步的负面影响。
启发式跨模态注意力对齐策略
在初步实验过程中,我们观察到编码器中的统一跨模态注意力机制倾向于表现出如图2所示的某种特定模式,不同的注意力头在训练稳定之后会学习到稳定的模态间信息交互逻辑。例如图3中Head1表现为音视频特征都与音频特征进行融合,Head2为模态间交叉注意力机制的融合,Head4为模态内自注意力机制的融合。这种现象首先直观地展示了统一跨模态注意力机制的工作原理,即不同的注意力头会根据梯度传播适应性地学习到不同的模态信息对齐范式;但同时也反映出模型中存在一定的计算冗余性,在多模态序列的对齐矩阵中只有一半的范围会生效。
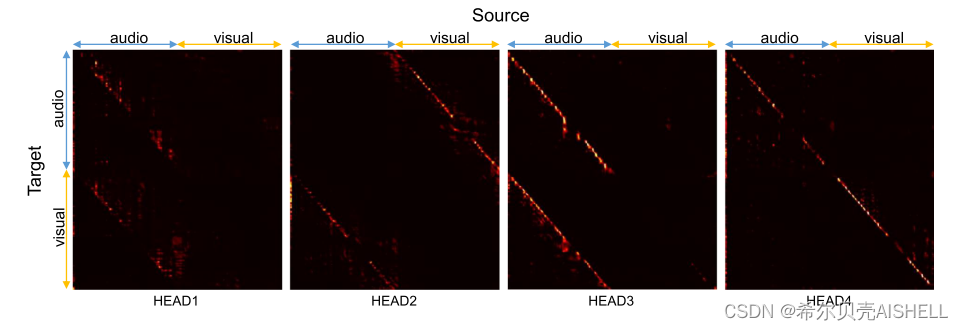
图3 编码器中最后一层注意力网络的注意力权重可视化图
针对上述现象,我们设计了一套启发式的注意力对齐策略。根据初步训练的模型中各种对齐范式的总体分布情况,我们对模型中不同层的各个注意力头分配了固定的对齐范式。如图4所示,模型中低层(1-4层)包含更多的模态内自注意力头,用于加工模态专属的特征表达;高层(5-10层)包含更多的模态间交叉注意力头,用于强化模态间的信息交互;头尾两层和其他层中的某个注意力头则保持无限制的状态。
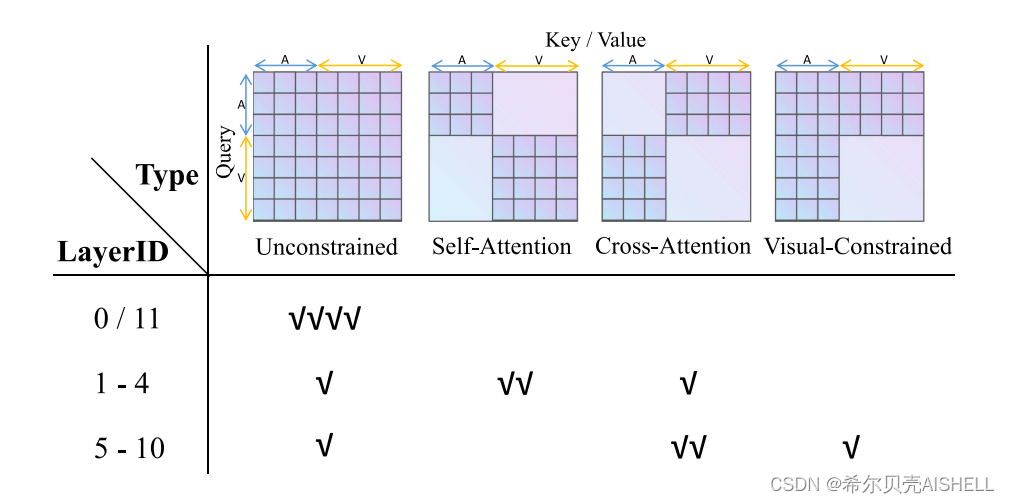
图4 启发式的多模态注意力对齐策略示意图
实验
实验数据以及配置
实验中采用了该研究领域内常用的大规模音视频数据集Lip Reading Sentence 3 (LRS3),其中包含约400小时的来源于TED演讲的视频数据和对应的文本标注。为了模拟真实环境,我们使用WHAM-noise数据集对训练数据和测试数据添加了不同信噪比的加性噪声。
实验中选取的基线模型包括:纯音频的语音识别系统、基于Middle Fusion的音视频联合识别系统、基于Early Fusion的音视频联合系统,以及基于大规模无监督预训练的AVHuBERT模型。其中,Middle / Early Fusion机制和统一跨模态注意力机制的区别如图5所示。
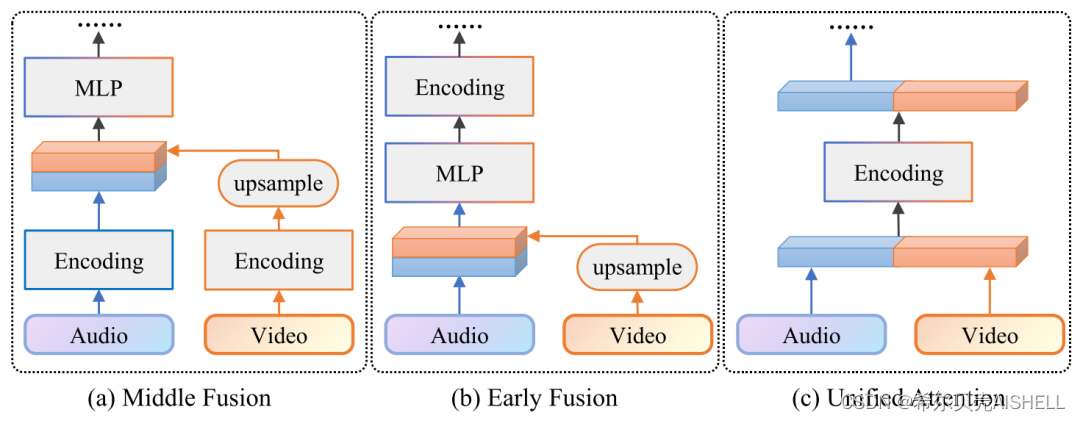
图5 不同的模态融合方式示意图
实验结果与结论
噪声环境下的不同的语音识别系统对比
在模拟构建的噪声数据上,我们测试了多个基线模型和本文系统的性能。如表1中Audio-Visual Test部分显示,我们提出的Unified-Attention系统在音视频联合模型中凭借最少的模型参数量取得了最好的识别效果,与经过预训练并微调的AVHuBERT模型仅存在10%的性能差距。
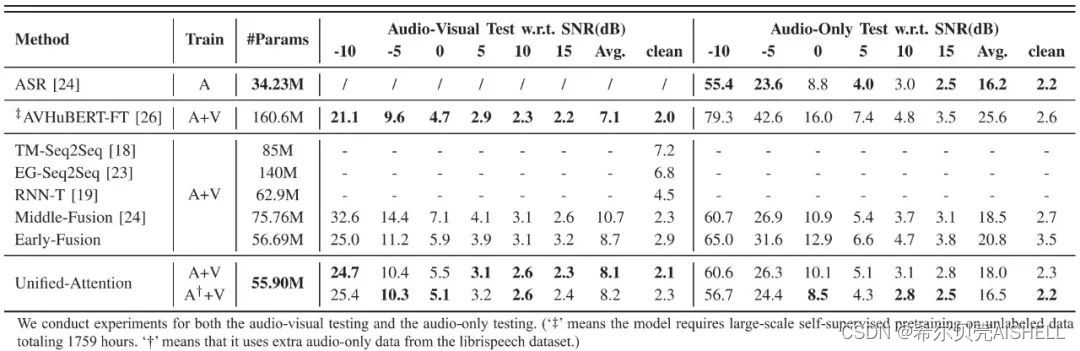
表1 不同系统在音视频、纯音频数据上的识别性能(WER)
视觉模态丢失情况下性能损失
在实际应用中还需要考虑到模态丢失的情况,在表1中Audio-Only Test部分,我们展示了各个多模态系统在纯音频输入条件下的性能,可以看到包括AVHuBERT在内的音视频基线模型都表现出了严重的性能损耗,甚至比纯音频的识别系统效果更差,而我们的系统能够保持较为稳定可用的识别效果。此外,我们尝试在训练数据中加入了更多的纯音频样本(来源于LibriSpeech),使模型在轻微损失音视频推理效果的代价下,仍能保持理想的纯音频推理性能。
音视频不同步对识别性能的影响
为了测试音画不同步对多模态语音识别系统的性能影响,我们测试了基线模型在0~8帧偏移数据上的WER,并观察4帧范围内同步性损失函数对我们提出系统的增益。如图6所示,在没有针对性数据增强的情况下,基线模型在3帧偏移量时已经基本不可用,而我们的模型只表现除了一定的性能损失,这得益于模型中统一跨模态注意力的隐式对齐。对于较大的音视频偏移量,我们提出的同步性感知训练损失函数(图中记作SyncLoss)显著减小了错误率上涨的幅度,并且经过模型偏移量预测矫正和二次推理(图中记作SyncLoss-TP)之后,词错误率在6帧范围内几乎不会受到影响,这也是因为此系统对音视频偏移量的预测误差在95%的情况下都在1帧以内。
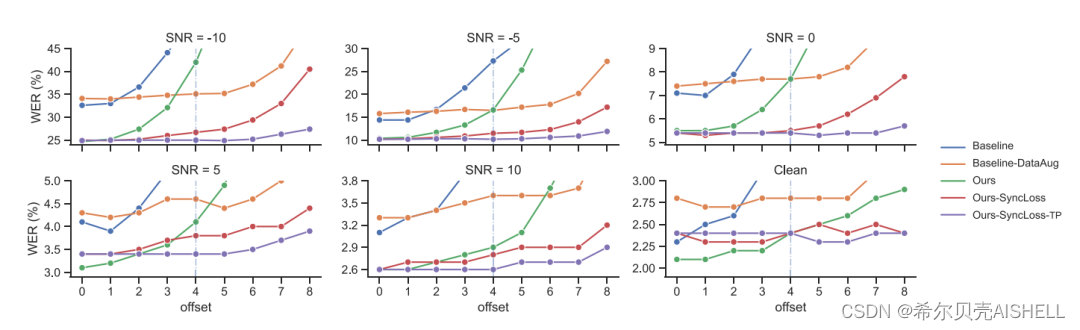
图6 在0~8帧的音视频帧偏移场景下,不同模型的WER变化趋势图
在表2中,我们也在6帧偏移量的音视频数据上进行了消融实验,可以看到同步性损失函数在数据增强的基础上有进一步的性能提升,而二次推理则可以将模型性能稳定在理想水平。
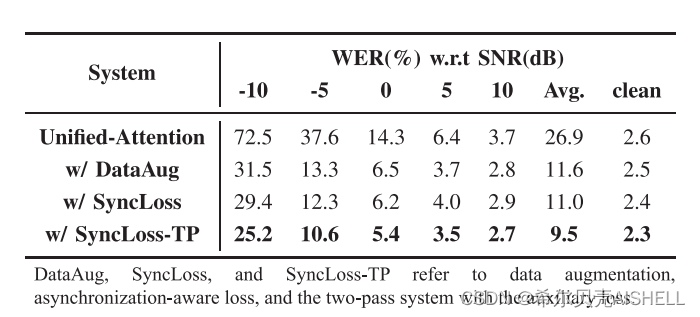
表2 本文提出的系统在6帧偏移音视频数据上的消融实验
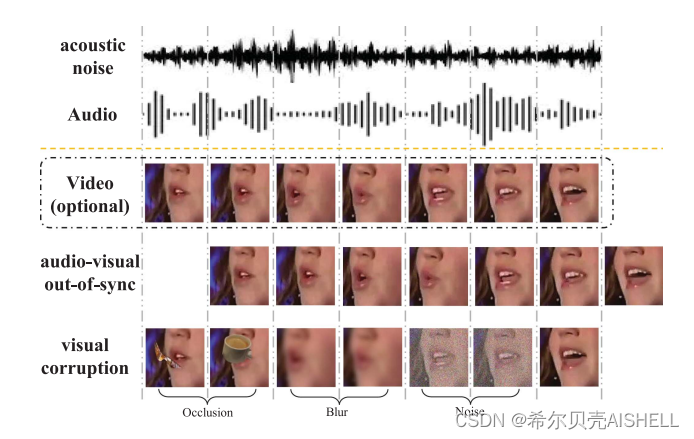
零样本低质量视觉数据的影响
视觉信号也存在着多种类型的干扰场景,这里我们考虑了遮挡、模糊、噪点三种信号干扰形式,在不进行相应数据增强的前提下,测试了系统对这些干扰的鲁棒性。如表3所示,在25%和50%两种干扰比例下,我们的模型都能保持相对最优的识别性能。
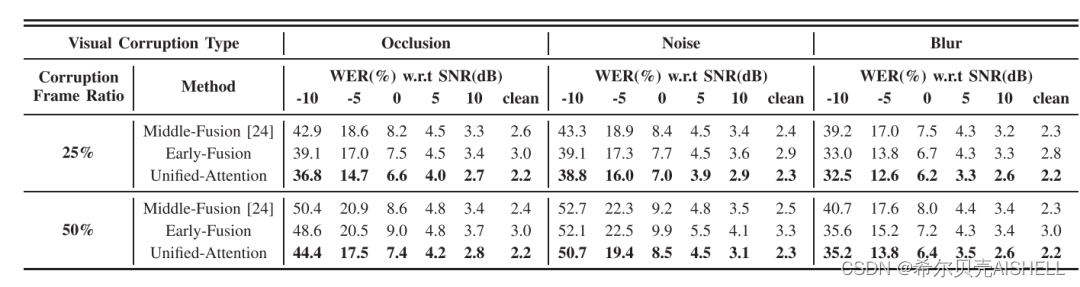
表3 三种系统在不同视觉干扰场景下的识别性能对比
启发式注意力对齐方案的效果
为了验证上文中启发式注意力对齐方案的性能,我们对其进行了消融实验。结果如表4所示,在音视频和纯音频两种场景下,启发式注意力对齐方案都有小幅度的稳定性能提升。尽管性能提升效果并不显著,但此方案可以同时显著降低模型的计算复杂度,将编码器中注意力层的浮点乘运算数量降低近一半。
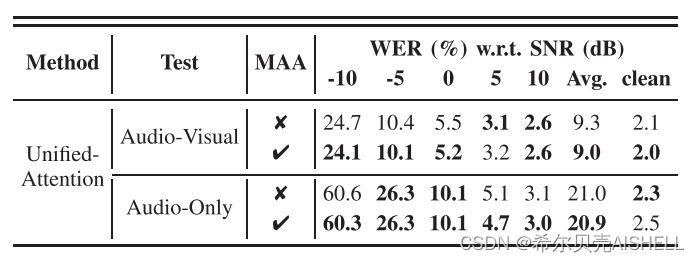
表4 启发式注意力对齐(简记为MAA)的消融实验
多说话人场景中的识别性能
在环境噪声以外,干扰人声对语音识别系统造成的损害更加明显,因此视觉信息也会更具价值。这里我们将训练与测试数据中的环境噪声替换为干扰人声进行实验,结果如表5所示,在此场景下同意跨模态注意力机制表现出了更加明显的性能提升,这证实了本文提出的系统中视觉模态经过了更加有效的特征融合。此外,为了论证统一跨模态注意力机制的可扩展性,我们在融合序列的末位上额外拼接了一帧说话人身份表征作为第三模态。表5中最后一行的结果显示,这额外的一帧说话人身份表征可以进一步大幅降低识别错误率。
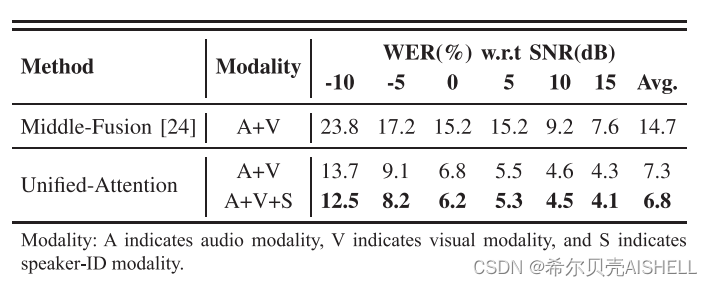
表5 干扰人声场景下的识别性能对比
首先我们比较了不同的解码策略。在比较的过程中,我们使用了不同的注册长度(EL),和不同的停止解码长度(SDL)。我们发现不同的解码算法在0.5s/1s的注册长度下都能取得不错的效果。同时,将1s作为停止解码长度对于所有算法是一个比较鲁棒的选择。另外,因为SC-Decode-Local在真实数据上兼具解码速度和性能的优势,在后续实验中,将被用作默认的解码策略。
总结
本论文中,我们提出了基于统一跨模态注意力机制的音视频多模态语音识别系统,借助视觉模态中的唇部动作信息提升嘈杂环境下的语音识别性能。在文中,我们还提出了音视频同步性感知训练的策略,既显著缓解了音画不同步对系统性能的负面影响,也能直接用作音视频偏移量的预测任务。此外,我们设计的启发式的模态间注意力对齐方案能够显著降低多模态交互的计算复杂度,并带来进一步的性能增幅。基于以上策略,在LRS3数据集上,我们提出的系统凭借最低的模型参数量和计算复杂度取得了不同噪声环境下的最优性能,并且对于模态缺失、音画不同步、视觉干扰等特殊场景都具备较好的鲁棒性。
参考文献
[1] Petridis, Stavros, Themos Stafylakis, Pingchuan Ma, Georgios Tzimiropoulos, and Maja Pantic. "Audio-visual speech recognition with a hybrid ctc/attention architecture." In 2018 IEEE Spoken Language Technology Workshop (SLT), pp. 513-520. IEEE, 2018.
[2] Zhou, Pan, Wenwen Yang, Wei Chen, Yanfeng Wang, and Jia Jia. "Modality attention for end-to-end audio-visual speech recognition." In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6565-6569. IEEE, 2019.
[3] Ma, Pingchuan, Stavros Petridis, and Maja Pantic. "End-to-end audio-visual speech recognition with conformers." In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7613-7617. IEEE, 2021.
[4] Shi, Bowen, Wei-Ning Hsu, and Abdelrahman Mohamed. "Robust self-supervised audio-visual speech recognition." arXiv preprint arXiv:2201.01763 (2022).
[5] Li, Jiahong, Chenda Li, Yifei Wu, and Yanmin Qian. "Robust audio-visual ASR with unified cross-modal attention." In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1-5. IEEE, 2023.
[6] Afouras, Triantafyllos, Joon Son Chung, and Andrew Zisserman. "LRS3-TED: a large-scale dataset for visual speech recognition." arXiv preprint arXiv:1809.00496 (2018).

















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









