







线性分类器损失函数与最优化
假设有3类 cat car frog
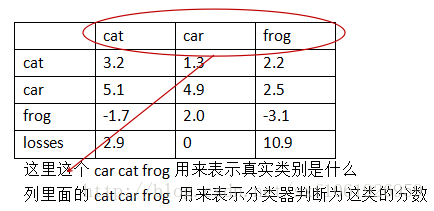
第一列第二行的5.1表示真实类别为cat,然后分类器判断为car的的分数为5.1。
那这里的这个loss怎么去计算呢?
这里就要介绍下SVM的损失函数,叫hinge loss。
如上图所示,我们去计算第一列的损失,计算方法如下:
- 1
- 2
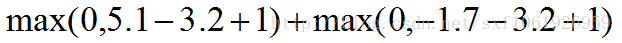
这里3.2为真实类的分数,所以为被减数。
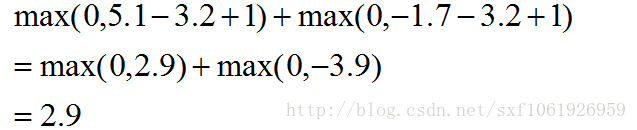
这个计算方法就是用的多类SVM损失。
SVM损失(hinge loss)
给定一个样本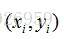
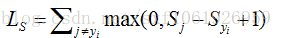
这是一个二分类支持向量机的泛化,它计算了所有不正确的例子,将所有不正确的类别的评分,与正确类别的评分之差加1,将得到的数值与0作比较,取两者中的最大值,然后将所有的数值进行求和。
我们不仅要使得正确类别的评分高于错误类别的评分,还使用了一个安全系数,系数的值为1,为啥安全系数为1?
根据W的不同,得出的分数也不同,W按比例缩放,分数也在缩放,所以安全系数为1是随意给的。
全部训练集的Loss是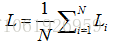
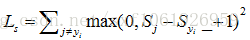
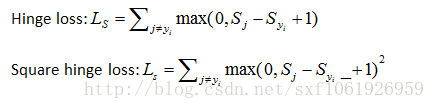
问:那么利用hinge loss的最大损失和最小损失分别为多少?
答:最小值:0,最大值:无穷大
问:最开始的时候,W都很小,接近于零,那么在优化的时候分数很接近零,就是说左边计算出的Sj都接近零,那么损失值会怎么样?
答:像左边只有三类的,平均损失会接近2。
正确性检查程序
一般为了正确性检查程序,当从很小的数W开始优化时,你的第一个损失函数,如果你的函数形式基本正确,只需要去看得到的数是否有意义,例如当在这个例子中损失为2,说明程序正确运行。
矢量化实现:
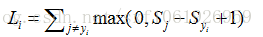
- 1
- 2
- 3
- 4
- 5
- 6
问:如果我们找到了一个W,使得损失函数为零,那么这个W是否是独一无二的?
答:当找到一个W后,用2W去计算Loss,发现损失还是为零,而且越大,分数越大,差本来就是小于-1的数,那更加小于-1
所以引入了正则化 R(W)
正则化
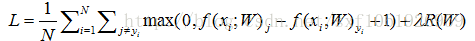
R(W)衡量了W的好坏,我们不仅仅想要数据拟合得更好,也希望能优化W,训练损失和你用于测试集的泛化损失,所以正则化是一系列通过损失来使目标相加的技术,和前面的项形成竞争,前面的想适应你的训练数据,而这个想要让W呈现一种特殊的方式,所以有时在目标中他们会相互竞争。
事实证明,正则项有时会让训练错误变得更多,甚至造成错误的分类,但是我们注意到,他会使测试结果表现得更好。
常见正则化或者权值衰减:
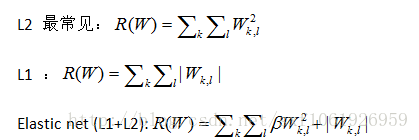
还有max norm /drop out等
例:
X=[1,1,1,]
W1 = [1,0,0,0]
W2 = [0.25,0.25,0.25,0.25]
他们乘积都为1:
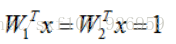
不加正则化,分数一样,loss一样,但L2正则化考虑了x中的大部分东西,L2会认为W2好些。
Softmax
Softmax分类:一般化的逻辑斯蒂回归
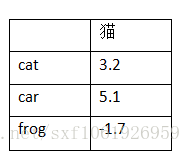
假设这些分数都是未标准化的对数概率
这一列表示真实图片为猫,然后判断为这三类的分数分别为3.2、5.1、-1.7。
求图片为某一类的概率: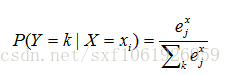
使正确分类的概率的对数最大,根据损失函数,我们要使负的正确分类概率的对数最小,所以概率对数是分数的扩展。
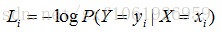
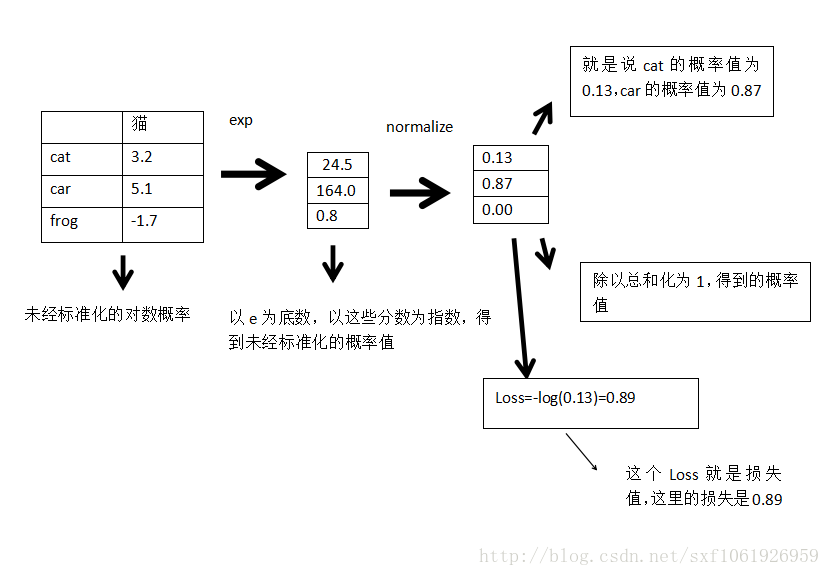
问:上面这个Loss的最大值、最小值?
答:看log函数就能看出来,为1的时候最小为0,为0的时候最大为无穷大。
问:刚开始训练的时候,W很小,那么损失值是多少呢?
答:是类别数分之一的对数负值,可用于检查代码
Hinge loss和cross-entropy loss比较
下图分别展示了hinge loss和cross-entropy loss的计算过程。
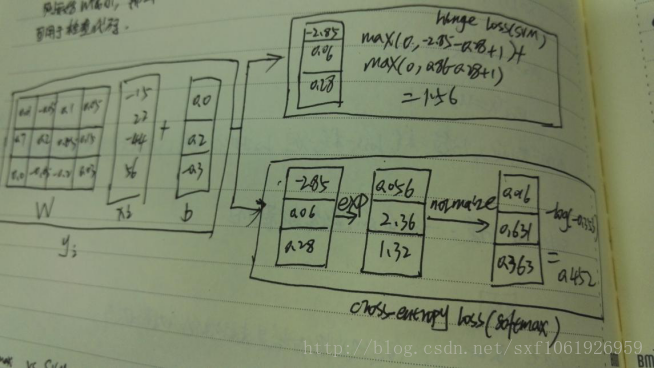
Hinge loss的话只有当分类正确,即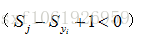
但是cross entropy loss对每个样例的每个分数都有用到。当分数发生微小变化的时候,cross entropy loss会变,hinge loss不会变。
下一章 反向传播与神经网络初步
原文地址:http://blog.csdn.net/sxf1061926959/article/details/60470415















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









