






一、概述
1.思路
k-近邻算法(KNN)采用测量不同特征值之间的距离方法进行分类。如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
2.原理
- 数据集:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签。
- 分类:输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似(最邻近)的数据的分类标签。
- K:一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。
- 分类结果:最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
3.算法流程
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
二、代码实现
核心代码如下所示:
from numpy import *
import operator
# #创建数据集和标签函数
def createDataSet():
group = array([[1.0, 2.0], [1.2, 1.1], [0.1, 1.4], [0.3, 3.5]])
labels = ['A', 'B', 'C', 'D']
return group, labels
#计算欧式距离
def classify(inX, dataSet, labels, K):
dataSetSize = dataSet.shape[0]
difMat = tile(inX, (dataSetSize, 1)) - dataSet
sqdifMat = difMat**2
sqDistances = sqdifMat.sum(axis = 1)
distances = sqDistances**0.5
#距离排序
sortedDistIndicies = distances.argsort()
#排序取前K个
classCount = {}
for i in range (K):
voteIlable = labels[sortedDistIndicies[i]]
classCount[voteIlable] = classCount.get(voteIlable, 0) + 1
#字典排序
soredClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return soredClassCount[0][0]
group, labels = createDataSet()
prdict = classify([1.0, 1.5] , group, labels, 3)
print(prdict)输出结果如下所示:
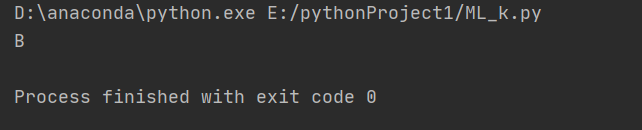
输入(1.0, 1.5)分类为B,符合预测要求,下面逐一解释各个函数的含义。
1、createDataSet()
用来创建一个新的数据集,其中group是特征集,上面代码中的例子,一共举了四个样本,每个样本都有两个特征(如果以电影为例的话,一个特征是接吻片段个数,一个特征是打斗场景个数),当然这个样本个数和样本的特征个数都是可以更改的,要根据你的具体问题来进行更改,列举的只是最简单的例子
labels则是样本对于的标签,group中一共有4个样本,所以这里labels就有4个元素,每个样本对应一个标签,这些都是用来输入到KNN模型中的,其中array函数问题。
2、classify0()
(1)输入参数
- inX是指要分类的样本(注意这是一个向量)
- dataSet是已知的数据集(这是一个矩阵,每个样本数据是一行,多个样本就是一个矩阵)
- labels是上面数据集对应的标签,这也是一个向量,向量的长度与dataSet的行数一样(样本数)
- k参数是KNN里面的k,也就是要选择的前k个样本。
(2)第一步求距离
这里用的距离度量是欧氏距离,当然也可以用其他的距离度量方,当然我看到的算法中,KNN一般都是用欧氏距离,因为样本提取特征以后,这些特征总是可以表现为一个向量(每个特征占一个维度,几个特征就是几维向量),而这个向量可以在空间中表示为一个点,欧式距离就表示空间中点的距离,举个例子,计算两个向量点xA和xB的距离:

这里说一下,这一步中第二行代码,也就是坐标相减,它的原理是求出未分类样本与分类样本的距离,比如未分类样本是[1,2,1],而分类样本分别是[1,2,4]、[2,8,6]和[4,5,3];首先将未分类样本扩展成一个矩阵,然后和已分类样本相减。如下图所示:
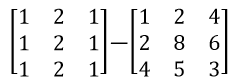
(3)第二步距离排序
这个很简单,上面求出未分类样本与已分类样本的距离,现在按这些距离的大小进行排序,然后选出距离最短的前K个点就可以了,这K个点就是对未分类样本做出分类的依据
(4)取前K个样本
这个也很简单,这里上面已经介绍过了,不再多说
(5)排序与返回
返回的值就是对未分类样本做出的预测值。















 2232
2232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









