









最近(2025-01) 关于Agent 探讨颇多, 不管是 Scaling Law 可能出现的瓶颈,还是专小垂直领域小模型"繁荣",亦或是2B场景急于落地,总之讨论的非常多, 更甚有扭曲、牵强附会的解释。
下面是年前(2025春节)最后的一次个人总结归纳,预计这个概念2025 会有更多的解释或者变体,有必要仔细梳理形成有效理解。
## 定义
此篇文章比较原汁原味解释了 Agent 概念,这里抽几个核心概念,具体阅读原文,作者blog 有不少干货(作者也很厉害角色 :-) )。
Chip Huyen《Agents》:
https://huyenchip.com//2025/01/07/agents.html
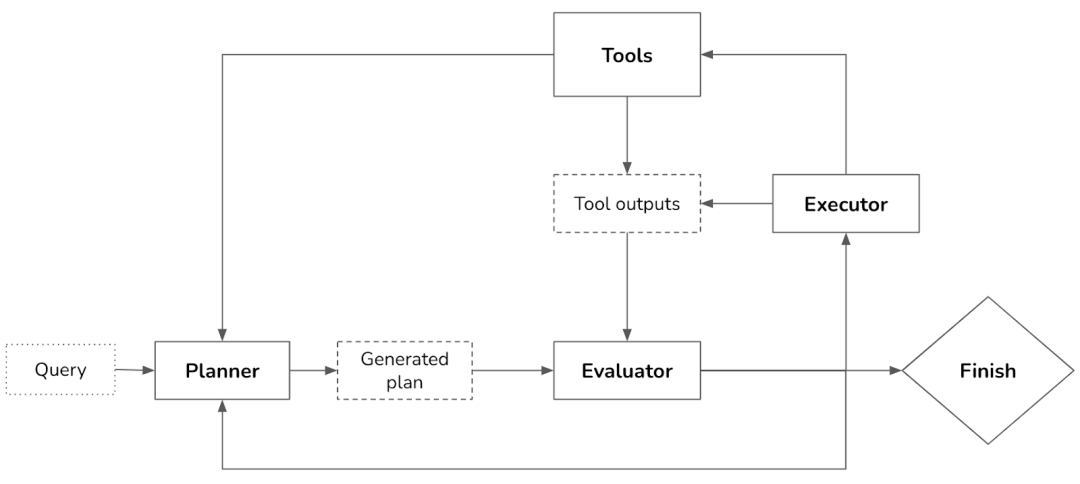
Foundation model (FM) versus reinforcement learning (RL) planners
关于Planner有意义的探讨 ; 自回归大语言模型(Auto-Regressive LLMs) 也就是现在各种LLM, 难以进行规划(planning), 这些可能的论点:
-
局部性:每次只预测下一个词,缺乏全局视角。
-
缺乏长期记忆:无法记住复杂的上下文。
-
无法回溯:生成错误后无法修正。
-
缺乏推理能力:无法进行逻辑推理或模拟未来。
-
无法模拟未来:无法评估不同选择的结果。
智能体是强化学习中的一个核心概念,维基百科将其定义:“关注智能体应如何在动态环境中采取行动以最大化累积奖励。” (concerned with how an intelligent agent ought to take actions in a dynamic environment in order to maximize the cumulative reward.)
RL偏重,基础模型通过prompt 更简单, 这个未来会模糊。
复杂Plan 的编排就非常简单了,类Flow: 这个在很多产品工具中都已实现,如Dify,Flowise, LangFlow etc:
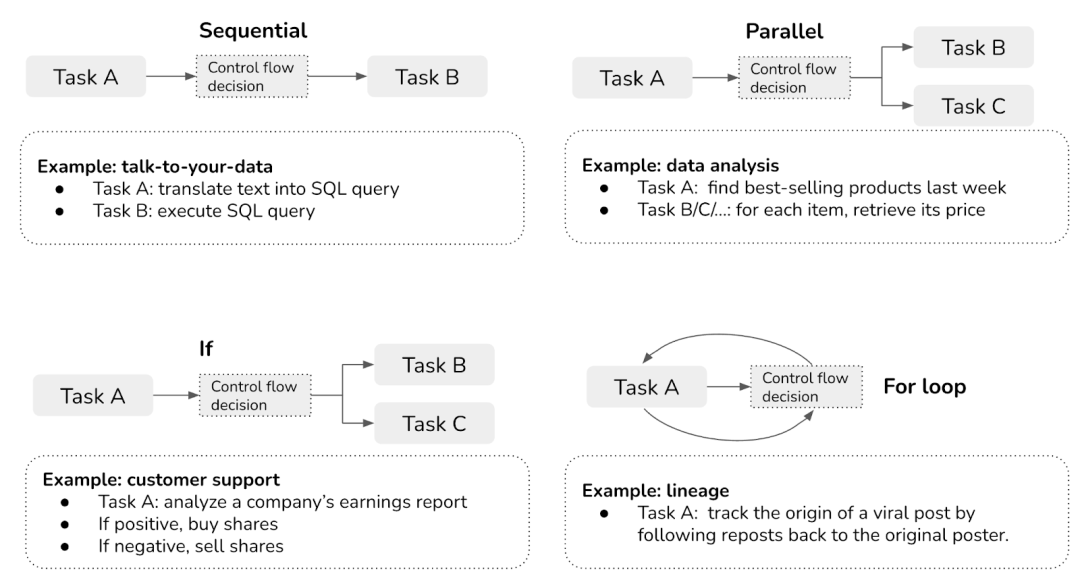
工具选择:
-
Toolformer (Schick et al., 2023) finetuned GPT-J to learn 5 tools.
-
Chameleon (Lu et al., 2023) uses 13 tools.
-
Gorilla (Patil et al., 2023) attempted to prompt agents to select the right API call among 1,645 APIs.
Gorilla 以前提到过, 这里可以看到不管是何种方式和外界tool链接,最后调整都在工具集的大小,MCP(Model Context Protocol) 是个什么东东? 也讨论过局限, 最终不在模型本身,如果有上万个工具,或者RAG 召回数据集爆增,挑战又来了!
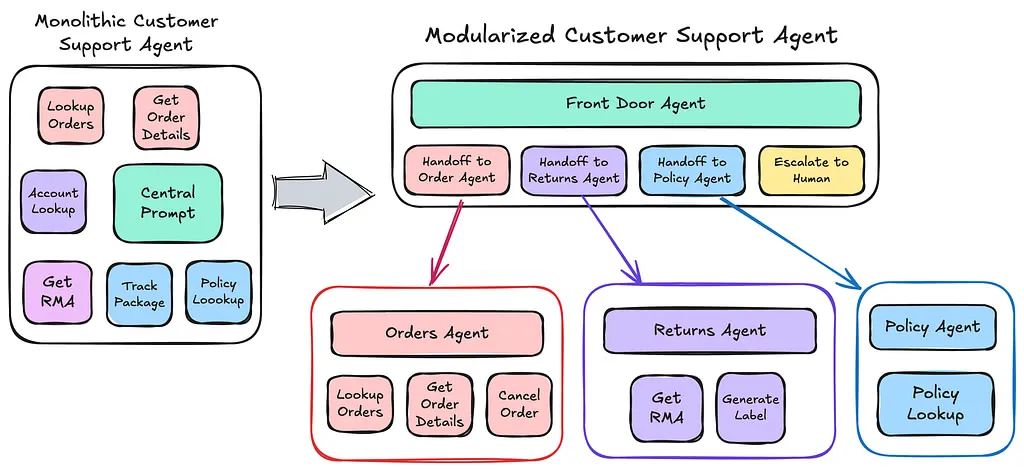
## 设计实现
vectorize: 《AI Agents》分四篇章讲解了agent 实现步骤。
https://vectorize.io/category/ai-agents/
-
Agent Architectures
-
Modularity
-
Agent to Agent Interactions
-
Data Retrieval and Agentic RAG
-
Cross-cutting concern CI/CD, TBD
-
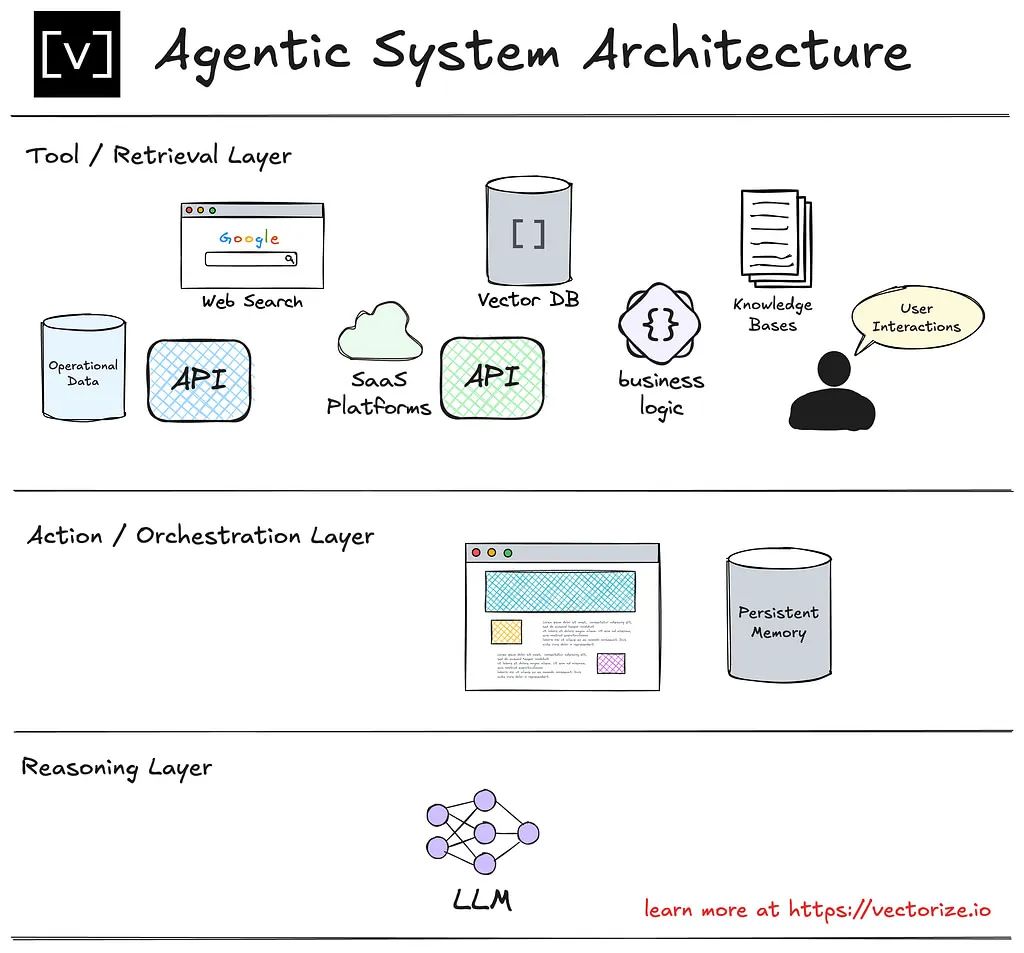
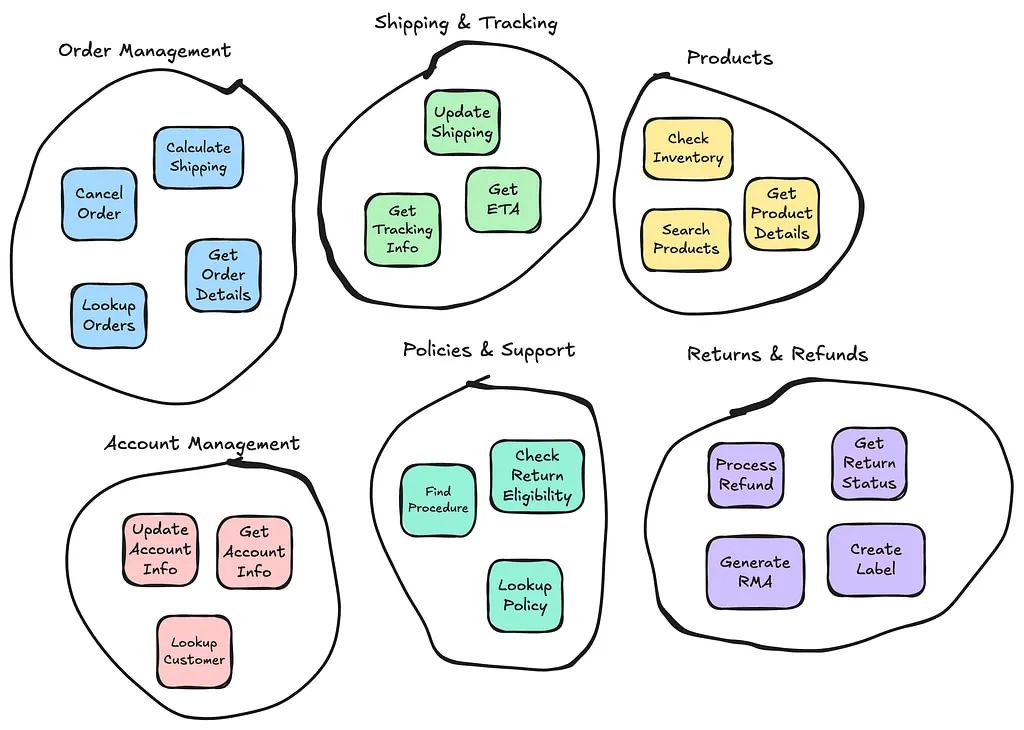
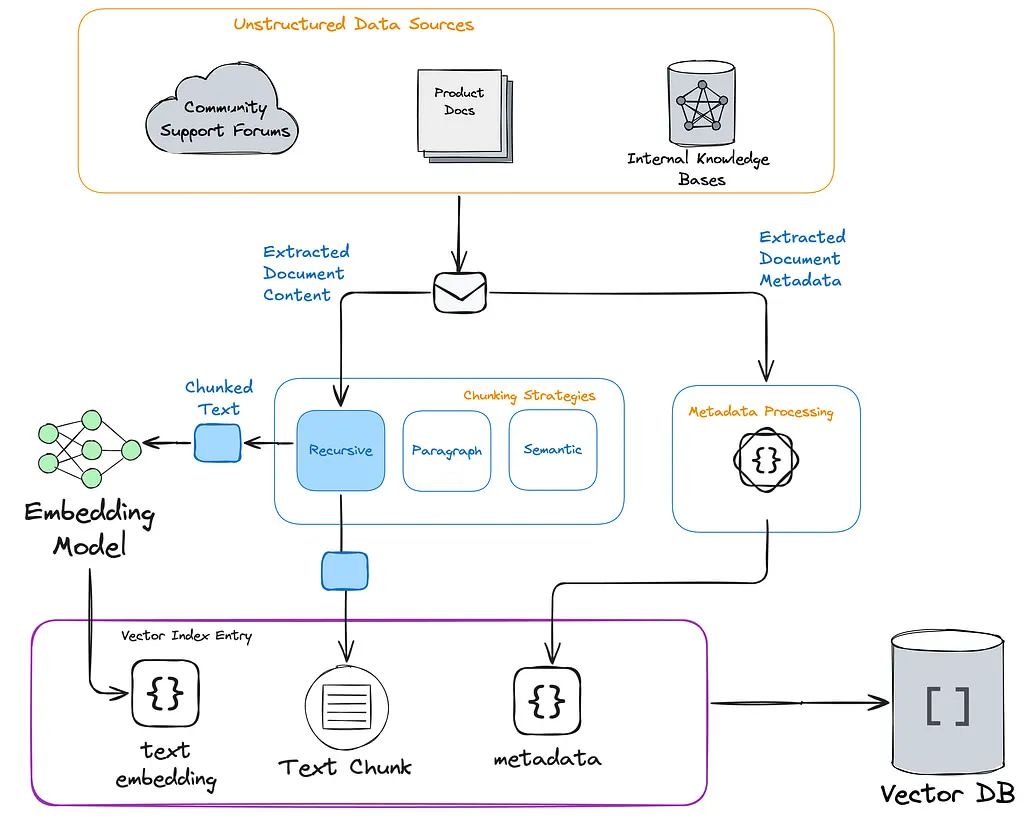
工具层:系统的基础。此层与外部数据源和服务交互,包括 API、矢量数据库、操作数据、知识库和用户交互。它负责获取系统所依赖的原始信息。精心设计的工具可确保代理高效地检索相关的高质量数据。
-
行动层:有时也称为编排层。此层负责协调 LLM 与外界(工具)之间的交互。它在适用时处理与用户的交互。它从 LLM 接收有关下一步要采取什么行动的指令,执行该行动,然后将结果提供给推理层中的 LLM。
-
推理层:系统智能的核心。该层使用大型语言模型 (LLM)* 处理检索到的信息。它利用上下文、逻辑和预定义目标来确定代理下一步需要做什么。推理能力差会导致冗余查询或操作不一致等错误。
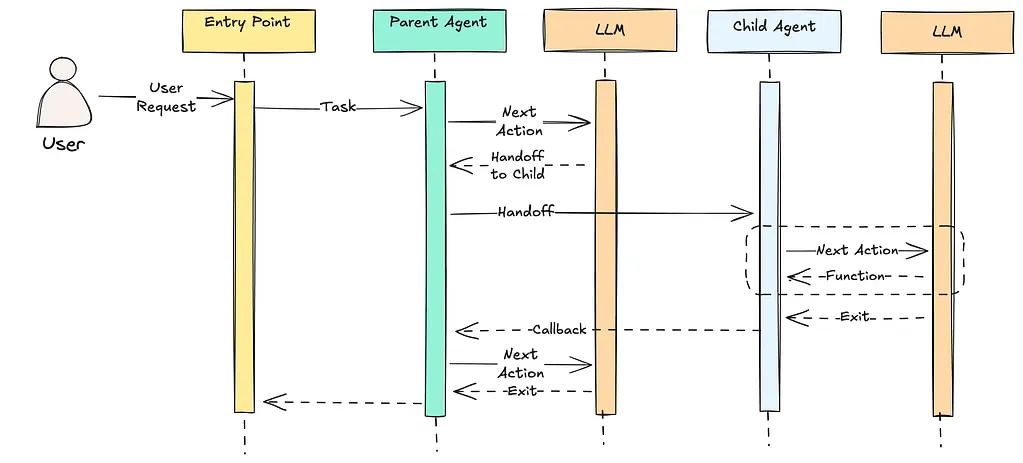
Architecture
Flow
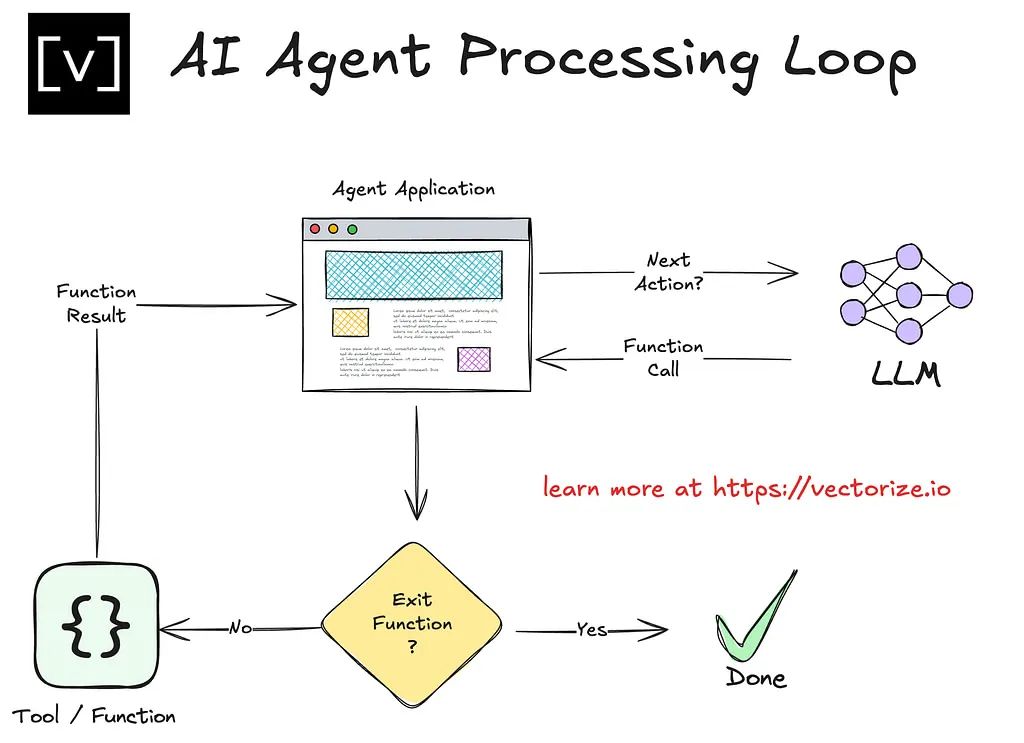
Design Principle
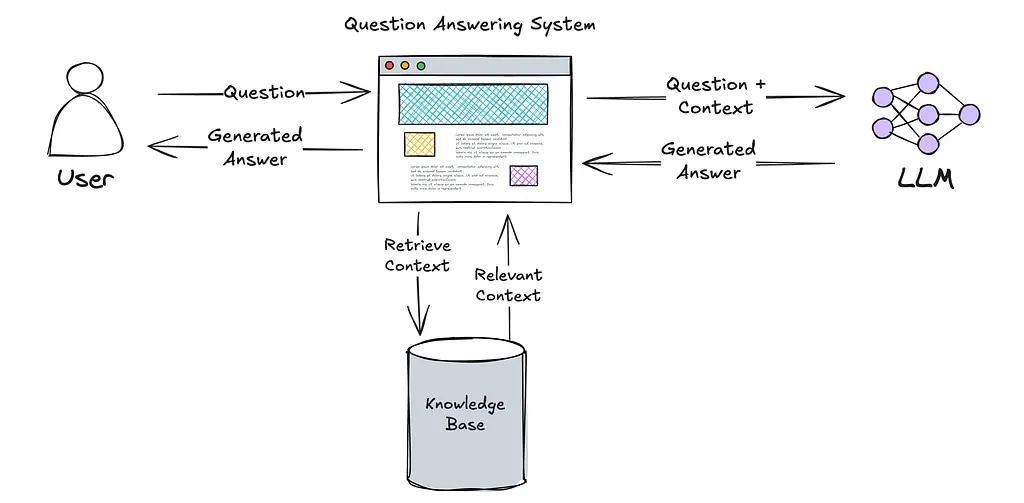
RAG
## 其他(笔记)
Atom Capital:中美AI最前沿——创投新趋势、中美竞争与初创企业出海战略
结构性挑战:某些场景只有等关键技术突破之后,才可能产生落地的应用。
工程性挑战:场景已经没有关键技术障碍了,但产品和技术实现需要一段时间的成熟期,是个时间问题。
AI Agent的大量落地实践是在2B/Prosumer市场,2B领域的主要工程性障碍:
-
编程模式转换
传统企业软件依赖硬编码规则,如workflow和SOP,存在定制化边际效益递减问题。LLM为企业软件带来动态决策可能,但核心挑战是将人类模糊决策逻辑形式化为AI可理解机制。目前,部分AI应用仍沿用旧思路,开发者需认识到Agent是递归状态机,而非简单自动化。 -
业务场景理解不足
当前AI开发处于早期,开发者更关注技术实现,缺乏对业务逻辑和垂直场景数据的洞察,导致Agent落地时需用户介入。未来,开发者需转向业务场景适配,深度融入用户工作流程,实现从通用智能到场景智能的跃迁。 -
知识搜索是基础
AI落地需引入企业经验性知识,知识搜索是关键。例如,Cursor和Glean AI通过知识搜索实现精准落地和能力演进。高质量知识搜索将推动AI从Copilot到Agent再到AI Worker的演进。 -
自学习能力
智能的核心在于学习能力。AI系统需实现从知识检索到决策、执行再到新知识积累的闭环。缺乏学习能力,AI Agent和AI Worker难以落地。预计1-2年内,具备自学习能力的系统将普及。
Copilot->Agent->AI Worker持续演进;知识搜索会成为AI企业应用的基础, 无论代码 Cursor, 还是 Glean AI,或是Perplexity。
随着AI可以编程,现有软件行业的壁垒和定制化魔咒正在被打破。
-
软件行业的壁垒。传统软件开发是高智商蛮力的积累,同时建立了用户粘性,让迁移成本很高。
-
定制化魔咒。中国企业软件都面临着这个问题。客户要求功能定制化,而定制意味着系统更加复杂,人工投入更大,边际效益递减。
软件开发需求尚未被满足, 难度降低两个量级后,爆发更多需求,但是需要更优秀的产品,新商业模式,分销渠道。
实际落地AI Agent的主要挑战集中在以下三方面:
-
行业认知与流程重塑:需深入理解行业逻辑、流程及数据,才能有效利用AI Agent重塑流程,发挥其价值。
-
效果稳定性与响应时间:
-
效果稳定性:通过工作流提升AI Agent的稳定性和可控性。
-
响应时间:确保首次响应时间(TTFT-Time to First Token)在合理范围内,避免影响用户体验。
-
-
充分发挥大模型能力:理解大模型的优势与不足,优化Prompt等策略,挖掘其潜力,规避潜在问题。
智能体是agent的意译,根本特征是基于意图采取行为的能动性(agency),更精准的翻译可能是agentic system。根据能动性来源可区分两类智能体:
-
一类是人类把实现某意图的路径设计成了固定的工作流(workflow),由LLM调用各种工具自动实现;
-
一类是人类只需要给出意图,系统来负责根据环境动态设计、调整工作流并实现。
智能体的本质是工具生态的编排; 无论工作流还是全自动,都是半封闭环境下的解法,所有智能体的本质,都是工具生态以任务为导向的编排。
这里面三个关键点:任务、工具、编排。
任务,是人设置的。剩下的两个关键点是工具生态和编排。
本质的障碍来自生态。一些工具可信,另一些不可信,一些工具愿意被调用,另一些不愿意。全自动智能体的执行能力是这些可信且愿意被调用的(半封闭)工具生态决定的。生态的障碍在于:我们不能假设存在一个无边界的、全开放的可信、且可调用的工具生态。
其实这个和人类的意图同样捉摸不定,有3个开放工具调用, 和3万个企业内部API,完全不是同一个结构,自然不可能是一样的解法!不是万的差别,是万*万=亿的差别! 现在呢通过固定领域的知识,自动半自动连接起来,可以说行业知识,SOP, What ever 你认为的方式, 但是就不是AI!
如果你真的拥有一个突破性的 AI 产品,你销售的应该是性能提升 100 倍,而不是 10 倍的产品。很难找到不愿意考虑这种选项的客户。
人们低估了从一个依靠现有系统取得成功的成熟企业中剥离传统系统的难度。
三万字实录对话硅谷顶尖研究员:General Agent是伪命题;Agent的交互设计是关键
需求定义越明确,完成的成功率就越高;需求越abstract,就越需要interactive的步骤和人工介入!
Agent 像把多个 LLM 当成 API 调用并组合成一个端到端的应用,但体验前所未有:不稳定、需要持续迭代、需要用户长时间等待。因此如何让用户能够与Agent良好交互并获得价值,需要复杂设计
像团队协作,如果大家都很菜,人越多越乱;但如果都够强,两个人可能比一个人效率快两倍,三个人可能再快1.5倍。
## 模型
大模型进化速度比移动互联网快了十倍。什么时候每个手机上都有大模型,to C 应用可能会爆发。
端侧大模型是指运行在终端设备(手机、平板等)上的大模型(因为参数量相对较小,也被称为小模型,黄金尺寸是 3B 左右),隐私性和安全性好,延迟低、支持离线使用。
当前,比较知名的端侧模型包括面壁智能 MiniCPM 系列、智谱 ChatGLM 系列、阿里巴巴 Qwen 系列、上海 AI lab InternLM 系列、微软 Phi 系列、Nexa AI 的 Octopus 系列等等。
20亿或80亿参数规模的模型,其所需算力足以在设备端运行,并且已经能够生成和创造出非常稳健的体验,无论是文本、图像还是音频方面。
设备端运行的小型人工智能生成式模型明年将会变得更受欢迎。
大模型量化和蒸馏。量化是一种技术,通过将模型的参数从高精度转换为低精度,以降低存储空间和加速推理。蒸馏则是通过模仿一个已经训练好的大模型,训练一个较小的模型,使其行为与原模型相似,从而实现模型的压缩。这两种技术都是模型压缩的常用手段,能够有效降低成本并提高推理速度。
450美元训练一个「o1-preview」?UC伯克利开源32B推理模型Sky-T1,AI社区沸腾了
MiniRAG:1.5B小模型也能用的RAG框架来了,与GPT4效果相差不大
Jina AI 发布 ReaderLM-v2:1.5B小模型大突破,HTML 转 Markdown 和 JSON 性能显著提升
## Other
社会生物学家爱德华·威尔森(Edward O. Wilson)曾说,“我们拥有旧石器时代的情感、中世纪的制度以及神一样的科技,这实在是危险至极。”
PS 更多素材笔记参考原文 notion 笔记!
# 参考
-
https://vectorize.io/category/ai-agents/
-
Jina AI 发布 ReaderLM-v2:1.5B小模型大突破,HTML 转 Markdown 和 JSON 性能显著提升
-
https://www.bilibili.com/video/BV1zM4m1y7fD
-
https://lxblog.com/efficiency/U/sTzUHoU7CfVx9M41xK8X8zaxKEYVMjGQ
-
https://tinyllm.org/
## So
这个貌似可以整合统一的区域, 先内部整合下....
## AI 入门
快速开启 - ApiHug如何在15分钟内,使用 ApiHug 启动一个API开发项目.![]() https://apihug.com/zhCN-docs/startApiHug - API design Copilot - IntelliJ IDEs Plugin | Marketplace
https://apihug.com/zhCN-docs/startApiHug - API design Copilot - IntelliJ IDEs Plugin | Marketplace![]() https://plugins.jetbrains.com/plugin/23534-apihug--api-design-copilot
https://plugins.jetbrains.com/plugin/23534-apihug--api-design-copilot



















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











