







简介与效果
用python3+opencv3做的中国车牌识别,包括算法和客户端界面,只有2个文件,一个是界面代码,一个是算法代码,点击即可出结果,方便易用!
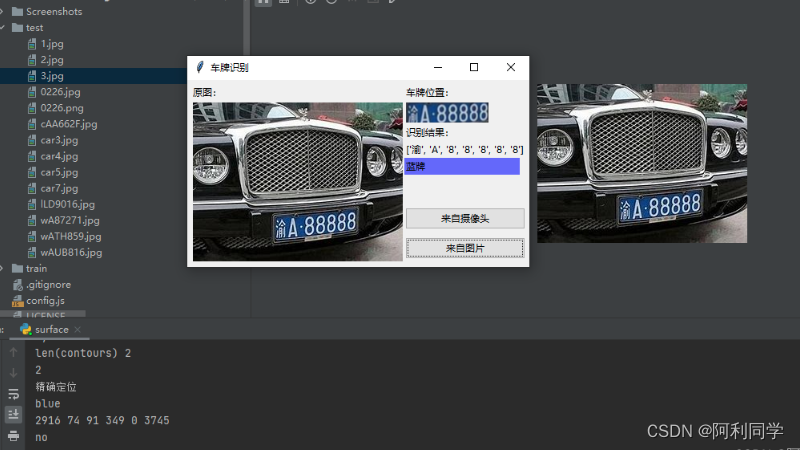
大致的UI界面如下,点击输入图片,右侧即可出现结果!
环境依赖
依赖库:非常容易安装:
版本:python3.4.4,opencv3.4和numpy1.14和PIL5
算法实现
算法思想来自于网上资源,先使用图像边缘和车牌颜色定位车牌,再识别字符。车牌定位在predict方法中,为说明清楚,完成代码和测试后,加了很多注释,请参看源码。
车牌字符识别也在predict方法中,请参看源码中的注释,需要说明的是,车牌字符识别使用的算法是opencv的SVM, opencv的SVM使用代码来自于opencv附带的sample,StatModel类和SVM类都是sample中的代码。
SVM训练使用的训练样本来自于c++版本。由于训练样本有限,你测试时会发现,车牌字符识别,可能存在误差,尤其是第一个中文字符出现的误差概率较大。
源码中,我上传训练样本,在train\目录下,如果要重新训练请解压在当前目录下,并删除原始训练数据文件svm.dat和svmchinese.dat
代码
额外说明:算法代码只有500行,测试中发现,车牌定位算法的参数受图像分辨率、色偏、车距影响(test目录下的车牌的像素都比较小,
--->qq 1309399183----------<代码交流
def from_pic(self):
self.thread_run = False
self.pic_path = askopenfilename(title="选择识别图片", filetypes=[("jpg图片", "*.jpg")])
if self.pic_path:
img_bgr = predict.imreadex(self.pic_path)
self.imgtk = self.get_imgtk(img_bgr)
self.image_ctl.configure(image=self.imgtk)
resize_rates = (1, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4)
for resize_rate in resize_rates:
print("resize_rate:", resize_rate)
r, roi, color = self.predictor.predict(img_bgr, resize_rate)
if r:
break
#r, roi, color = self.predictor.predict(img_bgr, 1)
self.show_roi(r, roi, color)
touch.me --->q1309399183----------<交流
处理具体流程

最终结果
车牌识别(License Plate Recognition,简称LPR)是一种基于计算机视觉和图像处理技术的自动化车辆身份识别技术。其工作原理主要包括以下几个核心步骤:
-
车辆检测:
利用地感线圈、红外线传感器、雷达、视频检测等手段感知车辆的到来,当车辆通过指定区域时触发图像采集系统。 -
图像采集:
通过高清摄像机实时捕捉车辆图像,确保车牌清晰可见。对于动态场景,摄像机会连续捕捉车辆通过时的视频帧。 -
预处理:
对采集到的图像进行初步处理,包括去除噪声、校正图像色彩、增强对比度、调整亮度、伽马校正、边缘增强等操作,以提高车牌区域的图像质量。 -
车牌定位:
应用特定的图像处理算法在预处理后的图像中识别出车牌所在区域,一般通过边缘检测、模板匹配、色彩空间分析等方法寻找车牌的矩形区域。 -
字符分割:
一旦定位到车牌区域,接下来要将车牌上的每一个字符单独分离出来,通常是通过对车牌图像进行行扫描或轮廓检测等方式完成。 -
字符识别:
对分割出的单个字符图像进行识别,常用的技术包括传统的模板匹配、特征提取和分类算法,以及现今主流的深度学习算法(如卷积神经网络)。通过训练模型来识别车牌上的数字、字母以及其他特殊字符。 -
结果输出与验证:
将识别出的字符拼接成完整的车牌号,并根据车牌的颜色信息(如果有的话)进行验证,最后将车牌号码和颜色信息输出到管理系统,用于车辆进出控制、交通违章查处、车辆追踪等各种用途。
随着深度学习技术的快速发展,车牌识别的准确率和速度都有了显著提升,使其在停车场管理系统、公路收费站、交通执法、智能安防和物联网应用中得到了广泛应用。

其他图片很可能因为像素等问题识别不了,识别其他像素的车牌需要修改config文件里面的参数,此项目仅是抛砖引玉,提供一个思路)。
全部代码:可关注我进行私信或者上述方式交流!!!
















 7284
7284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











