







文章原名:StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
作者:Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaolei Huang, Xiaogang Wang, Dimitris Metaxas
单位:Department of Computer Science, Rutgers University
译者:杨成
链接:
https://arxiv.org/pdf/1612.03242v1.pdf(可戳下方阅读原文)
1
导读
从文本描述生成高质量的图片是计算机视觉领域一个非常具有挑战性的工作。已有的文本-图像生成方法可以生成比较粗糙的模型,但是却不能生成必要的细节和生动的物体。在本文中,作者提出了堆积生成对抗网络(StackGAN)来生成高质量的图片。第一阶段的对抗生成网络利用文本描述粗略勾画物体主要的形状和颜色,生成低分辨率的图片。第二阶段的对抗生成网络将第一阶段的结果和文本描述作为输入,生成细节丰富的高分辨率图片。堆积对抗生成网络第一次在只给定文本的条件下生成真实的256*256的图片。作者在两个数据集上进行实验证明StackGAN的有效性。
2
模型
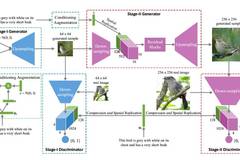
StackGAN模型主要分为两个阶段。如图所示,第一阶段的StackGAN就是一个标准的条件对抗生成网络(Conditional GAN),输入就是随机的标准正态分布采样的z和文本描述刻画的向量c。第一步的对抗生成网络生成一个低分辨率的64*64的图片和真实数据进行对抗训练得到粗粒度的生成模型。第二阶段的StackGAN将第一阶段的生成结果和文本描述作为输入,用第二个对抗生成网络生成高分辨率的256*256的图片。两个阶段中的对抗生成网络参数可以参考下式:

3
实验
作者在CUB鸟类数据集和Oxford鲜花数据上进行了训练和测试。以鸟类图片生成为例,和baseline对比的生成结果如下图所示:

第一阶段和第二阶段的对比如下图所示:

量化统计:Inception score越高越好;Human rank越低越好。

4
总结
在本文中,作者提出了堆积对抗生成网络StackGAN来从文本描述中生成高分辨率图片。该模型将生成过程分解为更为可控的两步:第一阶段画出物体的基本形状和颜色;第二阶段修正第一阶段结果中的缺点并加入更多细节。扩展实验证明了该方法的有效性。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









