







transformer一天搞懂
1 transformer
为什么这么好:

1.1 从整体来看transformer干的事情


下面这个图和上面的图一样



1.2 位置编码
上面的rnn输入进去的字是有顺序的,而在transformer中一起输入,需要加入位置顺序信息。

1.3 注意力机制(3个向量,3个阶段)
注意力机制的公式:
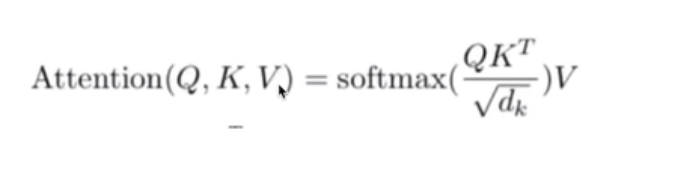
需要QKV三个矩阵
1.3.1 从图像上理解

(1)Q向量是查询向量,我们要找的东西,比如是婴儿,点乘结果越大越相似。
(2)K是键向量,代表各个位置的向量
(3)V是值向量
1.3.2 从nlp上理解


3个计算阶段



整个计算过程,就说矩阵相乘

总结步骤:
(1)词向量和权重矩阵相乘分别得到Q,K,V
Q的含义就是要查询的某个东西
K就相当于位置
V就是一个基本值,通过Q和K的计算经过softmax得到了一个注意力的权重,注意力权重乘上这个基本值就得到注意力的值了
(2)Q、K、V根据公式进行计算,主要是点乘得到注意力的值
1.4 多头注意力机制
就说用多个注意力机制的基本模块,bert中用了8个
通俗理解就和卷积层的通道是一个道理,相当于8个通道,多个特征信息。
上面一个注意力机制得到一个V的结果,但是对一个汉字只得到了一个v向量,那这个向量能得到我们想要的结果吗?不一定吧
这里要对比卷积核了,我们在卷积中要用多个卷积核,就说多个输出通道,目的就是为了提取多个特征,那现在你用一组Q,K,V得到的特征不一定好,所以用多组
多头指的就说多组注意力机制,就是多个人去提取它的特征


1.5 残差边
残差的作用解决梯度消失,从公式中来看,就说有最下面的公式里面有个1,不会是多个相乘等于0

1.6 BN和LN
BN就是批标准化
BN不能用到RNN中
在nlp中用的BN比较少,一般用LN,就说LayerNorm

1.7 整个Encoder流程
就是前面的结合,一共就是3个部分


1.8 Decoder
也是由多个基本模块叠加,文中是6个基本块

1.9 Encoder和Decoder交互

进一步细节


1.10 transformer
transformer就说整个对自然语言处理的流程,核心思想是多头注意力机制。
多头注意力机制是包括多个注意力机制
transformer中用了编码器用了6个多头注意力机制,解码器用了6个多头注意力机制,每个多头注意力机制用了8个注意力机制。
做的一个事情:
拿到了一个序列,对这个序列进行了重新的组合,得到了特征,最后进行分类等任务。
2 BERT
2.1 自然语言处理nlp的基本流程
个人猜想的理解:
(1)把word转换为向量,word2vec
秒懂词向量https://zhuanlan.zhihu.com/p/26306795
(2)Seq2Seq:向量经过解码器和编码器得到另一个序列
(3)最重要的是中间的编码器和解码器
之前都是RNN实现,传统的RNN无法做并行运算

2.2 BERT的整体架构
(1)基本模块


2.3 输入部分由3部分组成

2.4 mask


2.5 模型迁移学习4个步骤

2.6 bert总结
BERT是使用了transformer的核心模块,外部进行了一些调整。核心是transformer.
Transformer是和cnn,rnn并列的一个东西。

3 VIT(vision transformer)
2020年10月提出
3.1 如何转换图像作为transformer的输入
通过把图片和nlp类比,得到图像应该转换成什么样的格式输入到网络中

(1)我们最基本的思路

把每个像素点的数据替换bert中的汉字
缺点:
Bert中的输入是512个大小,你现在如果把像素点输进去
224*224是50176,长度太大了,会导致参数太大了

(2)改进方式

3.2 VIT的整体架构
5步走
(1)第一步是将图片分成小块,论文中是1616,比如图像大小是4848,变成了9个1616的小块。
(2)1616进行flaten拉平,然后将256长度变成768长度,这里博主讲的有些问题,256变成768是因为有3个通道,每个通道是256,3个通道进行拼接就得到了768个长度。
(3)生成位置编码,第一小块就是0,第2小块是1,0变成768维和第二步的相加,1变成768维和第2步的相加
(4)进行多头注意力机制的训练
(5)最后得到9个768长度的向量,然后转换成比如20个长度,进行softmax,得到20类的分类任务。


3.3 位置编码
需要告诉模型位置在哪个地方,两种位置编码方式


3.4 vit和原transformer的一点不同

4 代码部分
整个代码都比较简单
参考资料
【1】最好,唐宇迪的网易云课堂
【1】然后是那个,这是一个系列,讲的超级棒https://www.bilibili.com/video/BV1Di4y1c7Zm?p=2&spm_id_from=333.851.header_right.history_list.click
【2】基础,莫凡的自然语言处理
https://www.bilibili.com/video/BV1LA411n73X?spm_id_from=333.999.0.0
【3】很简单理解
https://www.bilibili.com/video/BV1Di4y1c7Zm?spm_id_from=333.999.0.0
【4】VIT
https://www.bilibili.com/video/BV18Q4y1o7NY?spm_id_from=333.999.0.0
【5】手推公式
https://www.bilibili.com/video/BV1UL411g7aX?spm_id_from=333.999.0.0
















 4697
4697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











