







1. 分布式文件系统详解
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.
1.1 适合的应用场景
- 存储非常大的文件:这里非常大指的是几百M、G、或者TB级别,需要高吞吐量,对延时没有要求。
- 采用流式的数据访问方式: 即一次写入、多次读取,数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作 。
- 运行于商业硬件上: Hadoop不需要特别贵的机器,可运行于普通廉价机器,可以处节约成本
- 需要高容错性
- 为数据存储提供所需的扩展能力
1.2 不适合的应用场景
- 低延时的数据访问
- 对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输设计的,因此可能牺牲延时
- 大量小文件
- 文件的元数据保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。
经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。如果有100万个文件,每个文件占用1个文件块,则需要大约300M的内存。因此十亿级别的文件数量在现有商用机器上难以支持。
- 文件的元数据保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。
- 多方读写,需要任意的文件修改
- HDFS采用追加(append-only)的方式写入数据。不支持文件任意offset的修改。不支持多个写入器(writer)
2. HDFS架构
HDFS主要由三个组件构成,分别是NameNode、SecondaryNameNode和DataNode。HDFS是以Master/Slave(主/从)模式运行的,其中NameNode,SecondaryNameNode运行在Master节点上,DataNode运行在Slave节点上。NameNode和DataNode的架构如下图:
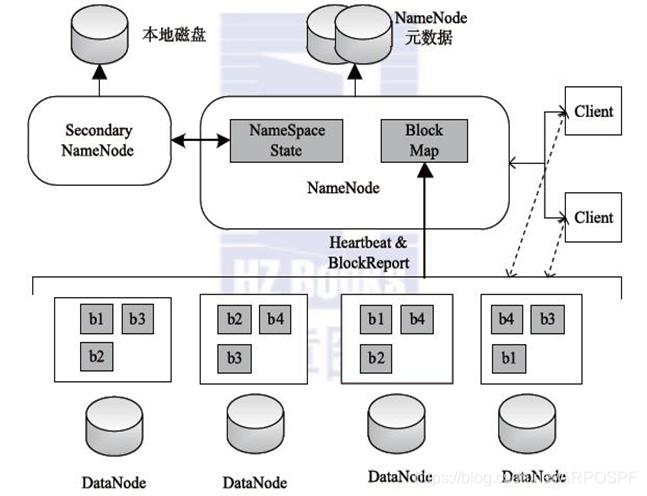
2.1 NameNode的作用
1、NameNode元数据信息
- 文件名,文件目录结构,文件属性(生成时间,副本数,权限)每个文件的块列表。
- 以及列表中的块与块所在的DataNode之间的地址映射关系
- 在内存中加载文件系统中每个文件和每个数据块的引用关系(文件、block、datanode之间的映射信息)
- 数据会定期保存到本地磁盘(fsImage文件和edits文件)
问题1:元信息的持久化
答:元数据的持久化操作过程示意如下:
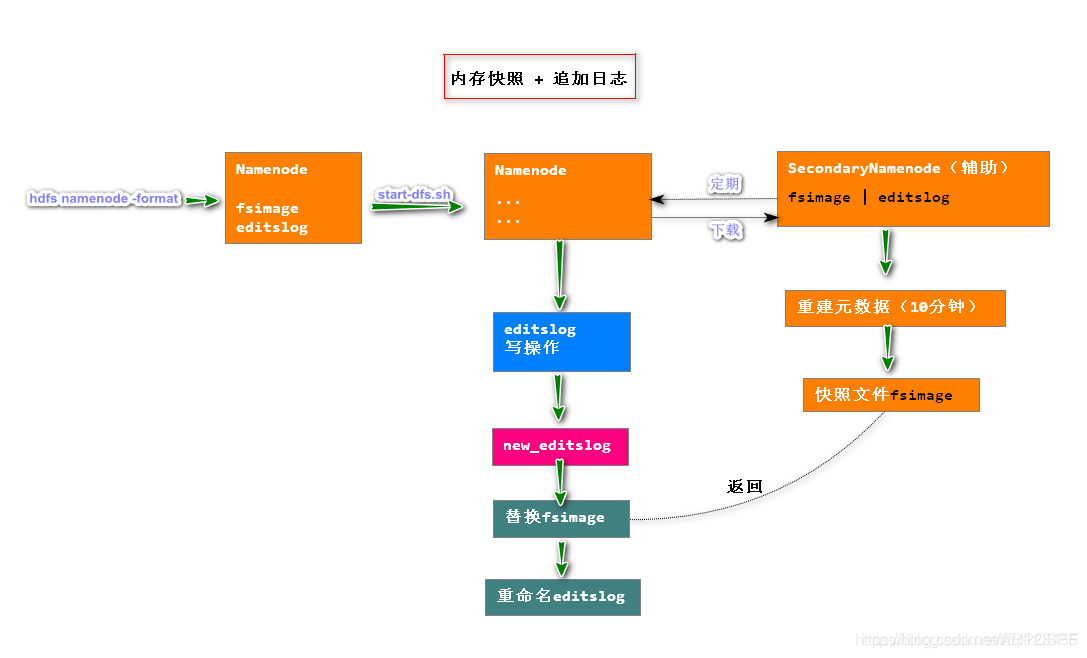
- 在HDFS 第一次格式化后,NameNode就会生成fsimage和editslog两个文件。
- SecondaryNamenode 节点定期从NameNode下载fsimage和editslog两个文件。
- 把fsimage和editslog结合成新的fsimage快照文件。
- 替换NameNode的fsimage文件,并将new_editslog重命名为editslog,组成新的fsimage和editslog。
- 为了避免editlog不断增加,secondary namenode会周期性合并fsimage和edits成新的fsimage
- 这样周期性操作,使得NameNode的fsimage和editslog相差一段时间。
问题2: NameNode和SecondaryNameNode的区别?
- NameNode主要维护两个组件,一个是fsimage,一个是editslog.
- fsimage保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等
- editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
2、NameNode文件操作
- NameNode负责文件元数据的操作
- DataNode负责处理文件内容的读写请求,数据流不经过NameNode,会询问它跟哪个DataNode联系
3、NameNode副本
- 文件数据块到底存放到哪些DataNode上,是由NameNode决定的,NN根据全局情况做出放置副本的决定
4、NameNode心跳机制
- 全权管理数据块的复制,周期性的接收心跳和块的状态报告信息(包含该DataNode上所有数据块的列表)
- 若接受到心跳信息,NameNode认为DataNode工作正常,如果在10分钟后还接受到不到DN的心跳,那么NameNode认为DataNode已经宕机 ,这时候NameNode准备要把DataNode上的数据块进行重新的复制。 块的状态报告包含了一个DataNode上所有数据块的列表,blocks report 每个1小时发送一次.
2.2 DataNode的作用
提供真实文件数据的存储服务。
- Data Node以数据块的形式存储HDFS文件
- Data Node 响应HDFS 客户端读写请求
- Data Node 周期性向NameNode汇报心跳信息
- Data Node 周期性向NameNode汇报数据块信息
- Data Node 周期性向NameNode汇报缓存数据块信息
3. 文件分块
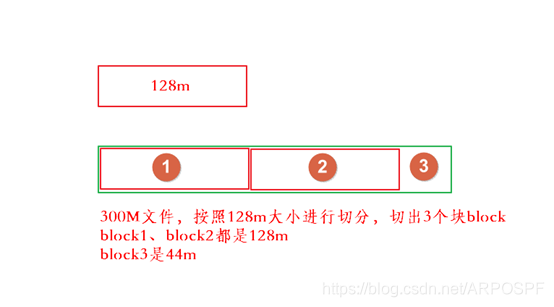
- 保存文件到HDFS时,会先默认按
128M的大小对文件进行切分;效果如上图 - 每个block块的
元数据大小大概为150byte - 所有的文件都是以block块的方式存放在HDFS文件系统当中,在hadoop1当中,文件的block块默认大小是64M,
hadoop2当中,文件的block块大小默认是128M,block块的大小可以通过hdfs-site.xml当中的配置文件进行指定
<property>
<name>dfs.blocksize</name>
<value>块大小 以字节为单位</value><!-- 只写数值就可以 -->
</property>
- 为了保证block块的安全性,也就是数据的安全性,在
hadoop2当中,文件默认保存三个副本,我们可以更改副本数以提高数据的安全性 - 在hdfs-site.xml当中修改以下配置属性,即可更改文件的副本数
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
HDFS按块存储的好处:
- 文件可以任意大
- 简化了文件子系统的设计,仔细提供只存储文件块数据,文件元数据由其他系统管理
- 有利于备份和提高系统的可用性
- 有利于负载均衡
问题:为什么一个block的大小就是128M呢?
默认为128M的原因,基于最佳传输损耗理论!
不论对磁盘的文件进行读还是写,都需要先进行寻址!
最佳传输损耗理论:在一次传输中,寻址时间占用总传输时间的1%时,本次传输的损耗最小,为最佳性价比传输!
目前硬件的发展条件,普通磁盘写的速率大概为100M/S, 寻址时间一般为10ms!
10ms / 1% = 1s
1s * 100M/S=100M
块在传输时,每64K还需要校验一次,因此块大小,必须为2的n次方,最接近100M的就是128M!
如果公司使用的是固态硬盘,写的速度是300M/S,将块大小调整到 256M
如果公司使用的是固态硬盘,写的速度是500M/S,将块大小调整到 512M
问题:为什么块的大小不能设置太小,也不能设置太大?
1.不能太大:
当前有文件a, 1G
128M一块 1G存8块 , 取第一块
1G一块 1G存1块 , 取第一块
只需要读取a文件0-128M部分的内容
①在一些分块读取的场景,不够灵活,会带来额外的网络消耗
②在上传文件时,一旦发生故障,会造成资源的浪费
2.不能太小:
文件a,128M
1M一块: 128个块,生成128个块的映射信息
128M一块, 1个块,一个块的映射信息
①块太小,同样大小的文件,会占用过多的NN的元数据空间
②块太小,在进行读写操作时,会消耗额外的寻址时间
4. 机架感知
HDFS分布式文件系统的内部有一个副本存放策略:以默认的副本数=3为例:
1、第一个副本块存本机
2、第二个副本块存跟本机同机架内的其他服务器节点
3、第三个副本块存不同机架的一个服务器节点上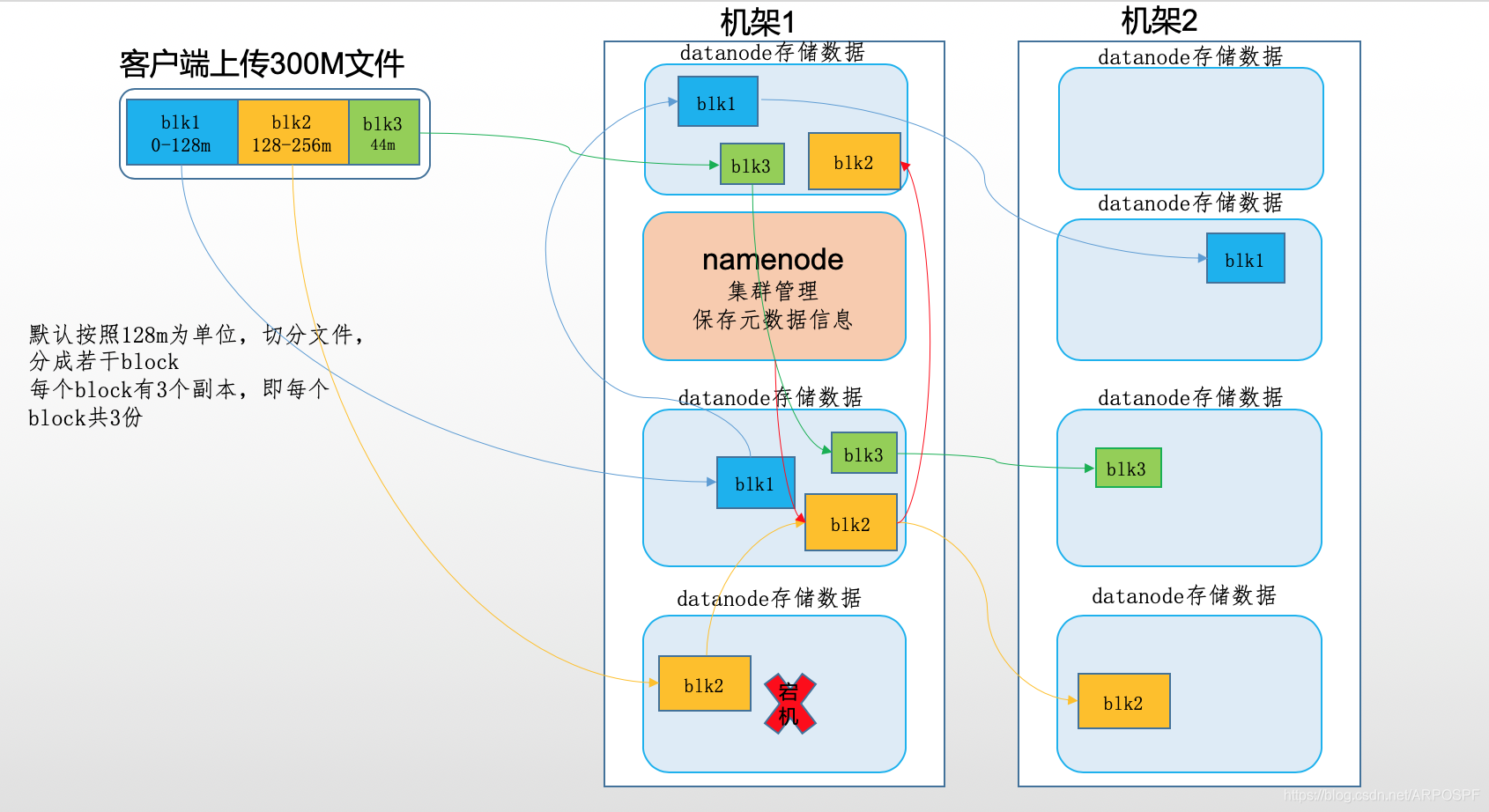


















 1575
1575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











