







一、NAM-Attention注意力机制简介
NAM全称Normalization-based Attention Module(基于归一化的注意力模块)。该模块采用的集成方式与CBAM注意力机制一样,即通道注意力+空间注意力,只不过NAM对两个注意力模块进行了重新设计。
结果就是,通过调整,NAM注意力模块可以利用稀疏的权重惩罚来降低不太显著的特征的权重,使得整体注意力权重在计算上保持同样性能的情况下变得更加高效,缓解了模型精度与模型轻量化的矛盾。
NAM-Attention注意力机制的模型结构图(通道注意力与空间注意力模块)如下所示:
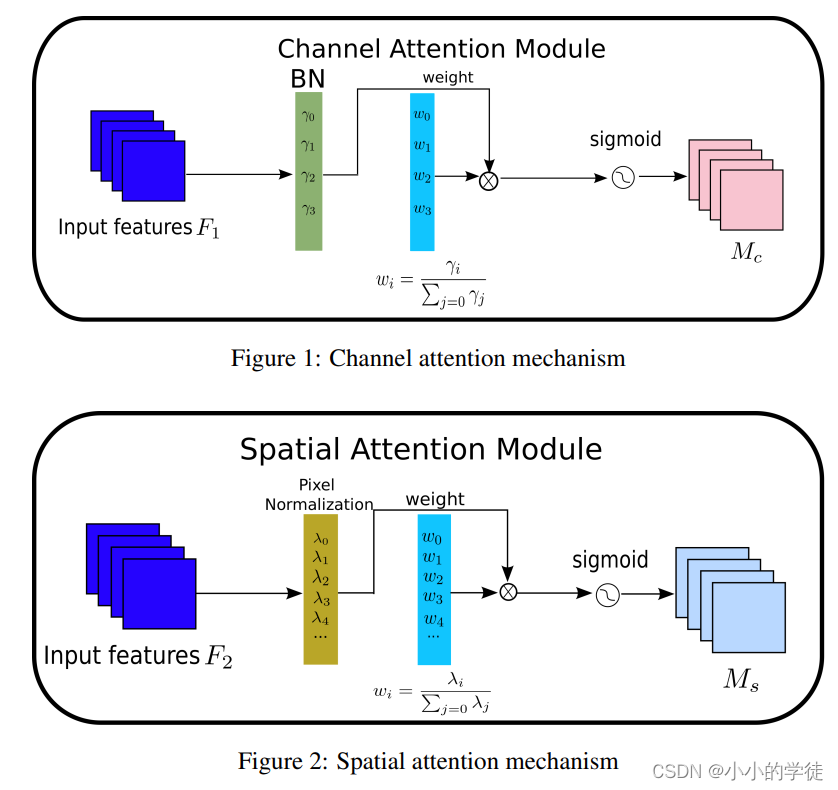
NAM-Attention注意力机制在CIFAR-100数据集上的分类结果如下:

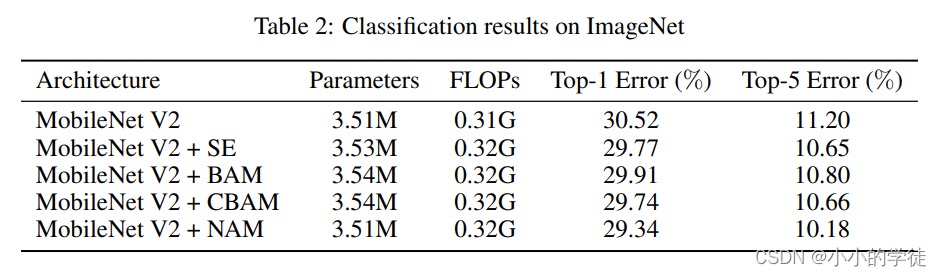
NAM-Attention注意力机制在ImageNet数据集上的分类结果如下:
【注:论文–NAM: Normalization-based Attention Module地址】:https://arxiv.org/pdf/2111.12419.pdf
【注:Github代码地址】:https://github.com/Christian-lyc/NAM
【注:NAM-Attention注意力论文中并没有展示其在目标检测任务上的表现,因此,需要结合具体的任务来进行实验。】
二、增加NAM-Attention注意力机制到YOLOv8模型上
大概路数还是不变,会有细微的差别!
【1: …/ultralytics/nn/modules/conv.py】
在这个文件末尾增加有关NAM-Attention的代码:(同样的,有两段,不要漏了!!)
#NAMAttention注意力机制
class Channel_Att(nn.Module):
def __init__(self, channels, t=16):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
x = torch.sigmoid(x) * residual #
return x
class NAMAttention(nn.Module):
def __init__(self, channels, out_channels=None, no_spatial=True):
super(NAMAttention, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1=self.Channel_Att(x)
return x_out1
【2:…ultralytics-main/ultralytics/nn/modules/__init__.py】
这个是一样的,在这个文件下对NAM-Attention模块进行声明,声明的名字要与前面的NAM代码模块名保持一致,可以参考这篇文章:https://blog.csdn.net/A__MP/article/details/136591826
1:找到这段,在后面加上模块名:GAM_Attention
from .conv import (
CBAM,
ChannelAttention,
Concat,
Conv,
Conv2,
ConvTranspose,
DWConv,
DWConvTranspose2d,
Focus,
GhostConv,
LightConv,
RepConv,
SpatialAttention,
.
.
NAMAttention,
)
2: 往下翻,找到这个,在后面加上模块名:GAM_Attention
__all__ = (
"Conv",
"Conv2",
"LightConv",
"RepConv",
"DWConv",
"DWConvTranspose2d",
"ConvTranspose",
"Focus",
"GhostConv",
"ChannelAttention",
"SpatialAttention",
.,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









