






1 泛化能力
百度百科解释: 机器学习算法对新鲜样本的适应能力。
更加具体的解释: 学习到的模型对未知数据的预测能力,这个未见过的测试数据必须是和训练数据处于同一分布,不在同一分布的数据是不符合独立同分布假设的(对同一规律不同的数据集的预测能力)。通常通过测试误差来评价学习方法的泛化能力。
通俗+形象解释:
就是通过数据训练学习的模型,拿到真实场景去试,这个模型到底行不行,如果达到了一定的要求和标准,它就是行,说明泛化能力好,如果表现很差,说明泛化能力就差。
2 泛化误差与经验误差
泛化误差: 在“未来”样本上的误差。
经验误差: 在训练集上的误差,亦称“训练误差”。
泛化误差与经验误差是否越小越好?
答案是NO!
因为会出现“过拟合”
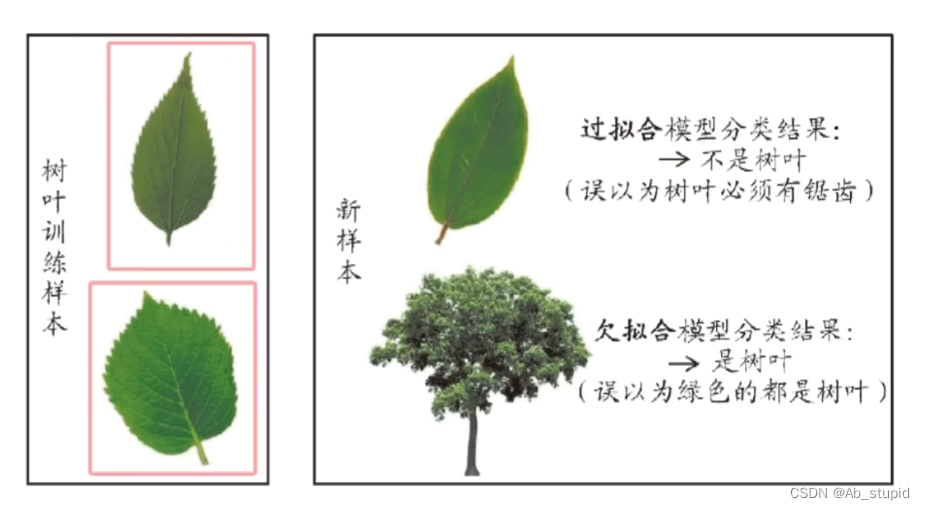
这里引入三种现象,欠拟合、过拟合以及不收敛。泛化能力的本质就是反映模型有没有对客观世界做真实的刻画,还是发生了过拟合。
考试成绩差的同学,有这三种可能:
一、泛化能力弱,做了很多题,始终掌握不了规律,不管遇到老题新题都不会做,称作欠拟合;
二、泛化能力弱,做了很多题,只会死记硬背,一到考试看到新题就蒙了,称作过拟合;
三、完全不做题,考试全靠瞎蒙,称作不收敛。
3 三大关键问题
- 如何获得测试结果? ——> 评估方法
- 如何评估性能优劣? ——> 性能度量
- 如何判断实质差别? ——> 比较检验
3.1 评估方法
关键: 怎么获得“测试集”?
测试机应该与训练集“互斥”
常见方法:
- 留出法(hold-out)
- 交叉验证法(cross validation)
- 自助法(bootstrap)
(1)留出法
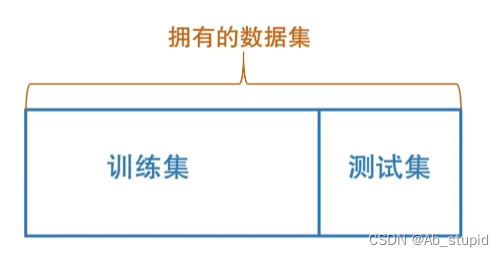
将拥有的数据集分为训练集和测试集
注意:
- 保持数据分布一致性(例如:分层采样)
- 多次重复划分(例如:100次随机划分)
- 测试集不能太大、不能太小(例如:1/5 ~ 1/3)
(2)k-折交叉验证法
10折交叉验证示意图:
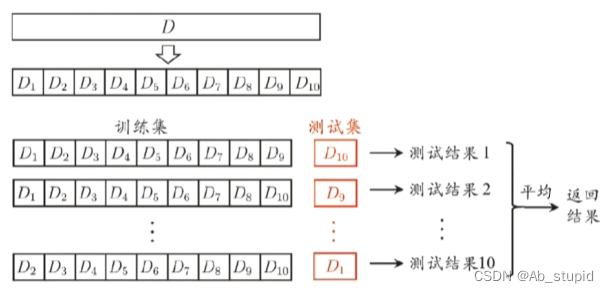
若k=m,则得到“留一法”(leave-one-out,LOO)
(3)自助法
基于“自助采样”(bootstrap sampling)
亦称“有放回采样”、“可重复采样”
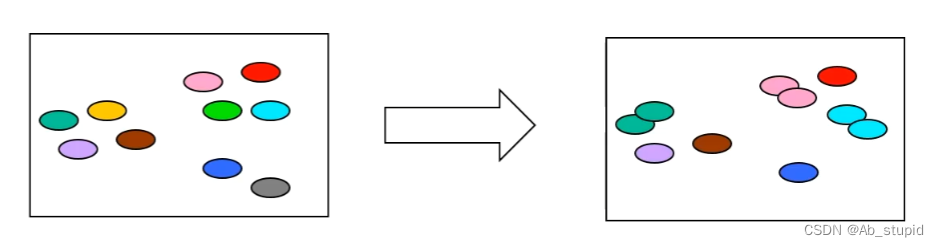
约有36.8的样本不出现,“包外估计”(out-of-bag estimation)
lim
m
→
∞
(
1
−
1
m
)
m
=
1
e
≈
0.368
\lim _ { m \rightarrow \infty } ( 1 - \frac { 1 } { m } ) ^ { m } = \frac { 1 } { e } \approx 0.368
m→∞lim(1−m1)m=e1≈0.368
- 训练集与原样本集同规模
- 数据分布有所改变
3.2 调参与验证集
算法的参数:一般由人工设定,亦称“超参数”。
模型的参数:一般由学习决定。
调参过程相似:先产生若干模型,然后基于某种评估方法进行选择。
参数调的好不好对性能往往对最终性能有关键影响。
算法参数选定后,要用“训练集+验证集”重新训练模型。
3.3 性能度量
性能度量(performance measure)是衡量模型泛化能力的评价标准,反映了任务需求
使用不同的性能度量往往会导致不同的评判结果
什么样的模型是“好”的,不仅取决于算法和数据,还取决于任务需求。
- 回归(regression)任务常用均方误差:
E ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 E ( f ; D ) = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } ( f ( x _ { i } ) - y _ { i } ) ^ { 2 } E(f;D)=m1i=1∑m(f(xi)−yi)2 - 错误率:
E ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x i ) ≠ y i ) E ( f ; D ) = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } \mathbb{I} ( f ( x _ { i } ) \neq y _ { i } ) E(f;D)=m1i=1∑mI(f(xi)=yi) - 精度:
acc ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x i ) = y i ) = 1 − E ( f ; D ) \begin{align*} \operatorname{acc}(f; D) &= \frac{1}{m} \sum_{i=1}^{m} \mathbb{I}(f(x_i) = y_i) \\&= 1 - E(f; D) \end{align*} acc(f;D)=m1i=1∑mI(f(xi)=yi)=1−E(f;D) - 分类结果混淆矩阵:
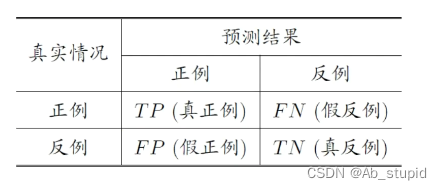
- 查准率:
P = T P T P + F P P = \frac { T P } { T P + F P } P=TP+FPTP - 查全率:
R = T P T P + F N R = \frac { T P } { T P + F N } R=TP+FNTP - F1度量:
F 1 = 2 × P × R P + R = 2 × T P T P + T N \begin{align*} F1 &= \frac{2 \times P \times R}{P + R} \\ &= \frac{2 \times TP}{TP + TN} \end{align*} F1=P+R2×P×R=TP+TN2×TP或者:
1 F 1 = 1 2 ⋅ ( 1 P + 1 R ) \frac { 1 } { F 1 } = \frac { 1 } { 2 } \cdot ( \frac { 1 } { P } + \frac { 1 } { R } ) F11=21⋅(P1+R1) - 若对查准率/查全率有不同偏好:
F β = ( 1 + β 2 ) × P × R ( β 2 × P ) + R F _ { \beta } = \frac { ( 1 + \beta ^ { 2 } ) \times P \times R } { ( \beta ^ { 2 } \times P ) + R } Fβ=(β2×P)+R(1+β2)×P×R 1 F β = 1 1 + β 2 ⋅ ( 1 P + β 2 R ) \frac { 1 } { F _ { \beta } } = \frac { 1 } { 1 + \beta ^ { 2 } } \cdot ( \frac { 1 } { P } + \frac { \beta ^ { 2 } } { R } ) Fβ1=1+β21⋅(P1+Rβ2) β > 1 β>1 β>1时查全率有更大影响; β < 1 β<1 β<1时查准率有更大影响
3.4 比较检验
在某种度量下取得评估结果后,是否可以直接比较以评判优劣?NO! 因为:
- 测试性能不等于泛化性能
- 测试性能随着测试集的变化而变化
- 很多机器学习算法本身有一定的随机性
常用方法:
统计假设检验(hypothesis test)为学习器性能比较提供了重要依据。
两学习器比较:
- 交叉验证 t 检验(基于成对 t 检验)
k折交叉检验;5x2交叉检验 - McNemar检验(基于列联表,卡方检验)















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









