






一 贝叶斯决策论(Bayesian Decision Theory)
概率框架下实施决策的基本理论:
给定
N
N
N 个类别,令
λ
i
j
\lambda_{ij}
λij 代表将第
j
j
j 类样本误分为第
i
i
i 类所产生的损失,则基于后验概率将样本
x
x
x 分到第
i
i
i 类的条件风险为:
R
(
c
i
∣
x
)
=
∑
j
=
1
N
λ
i
j
P
(
c
j
∣
x
)
R ( c _ { i } | x ) = \sum _ { j = 1 } ^ { N } \lambda _ { i j } P ( c _ { j } | x )
R(ci∣x)=j=1∑NλijP(cj∣x)贝叶斯判定准则(Bayes decision rule):
h
∗
(
x
)
=
arg
min
c
∈
y
R
(
c
∣
x
)
h ^ { * } ( x ) = \operatorname { \mathop{\arg\min}\limits_{c∈y} } R ( c | x )
h∗(x)=c∈yargminR(c∣x)
-
h
∗
h^*
h∗ 称为
贝叶斯最优分类器(Bayes optimal classifier),其总体风险称为贝叶斯风险(Bayes risk) - 反映了
学习性能的理论上限
二 生成式和判别式模型
P
(
c
∣
x
)
P(c|x)
P(c∣x)在现实中通常难以直接获得
从这个角度来看,机器学习所要实现的是基于有限的训练样本
尽可能准确地估计出后验概率
两种基本策略:

贝叶斯分类器≠贝叶斯学习
三 极大似然估计
先假设某种概率分布形式,再基于训练样例对参数进行估计
假定
P
(
x
∣
c
)
P(x|c)
P(x∣c) 具有确定的概率分布形式,且被参数
θ
\theta
θ 唯一确定,则任务就是利用训练集
D
D
D 来估计参数
θ
c
\theta_c
θc
θ
c
\theta_c
θc 对于训练集
D
D
D 中第
c
c
c 类样本组成的集合
D
c
D_c
Dc 的似然(Likelihood)为
P
(
D
c
∣
θ
c
)
=
∏
x
∈
D
c
P
(
x
∣
θ
c
)
P ( D _ { c } | \theta _ { c }) = \prod _ { x ∈ D_c } P ( x | \theta _ { c } )
P(Dc∣θc)=x∈Dc∏P(x∣θc)连乘易造成下溢,因此通常使用对数似然(Log-Likelihood)
L
L
(
θ
c
)
=
log
P
(
D
c
∣
θ
c
)
=
∑
x
=
D
c
log
P
(
x
∣
θ
c
)
L L( \theta _ { c } ) = \log P ( D _ { c } | \theta _ { c } ) = \sum _ { x = D _ { c } } \log P ( x | \theta _ { c } )
LL(θc)=logP(Dc∣θc)=x=Dc∑logP(x∣θc)于是,
θ
c
\theta _ { c }
θc 的极大似然估计为
θ
^
c
=
arg
min
θ
c
L
L
(
θ
c
)
\hat\theta_{c}=\mathop{\arg\min}\limits_{\theta_c}LL(\theta_c)
θ^c=θcargminLL(θc)
四 朴素贝叶斯分类器(Naive Bayes Classifier)


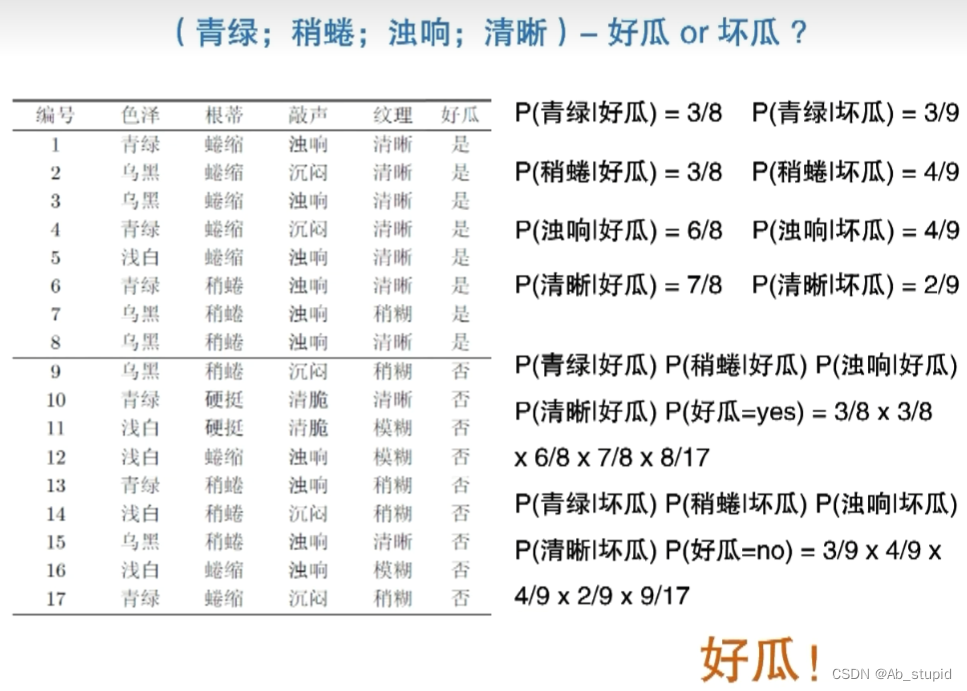
一个例子















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









