




一、全球算力竞争格局与国产生态困局
1.1 英伟达生态霸权的形成机制
英伟达CUDA 生态体系已构建起三维立体护城河:
-
技术维度,通过50个驱动程序、50个编译器、50 个数学库形成底层技术矩阵。
-
人才维度,全球400万 CUDA 开发者形成的技术惯性,使得算法工程师的知识迁移成本高达60% 以上。
-
商业维度,英伟达GPU占据全球 Al训练市场80% 份额,与谷歌、微软等巨头形成深度技术绑定。
这种“技术-人才-商业”的闭环生态,导致新进入者面临“三重死亡谷”: 研发成本高昂、开发者生态缺失、商业应用不足。
1.2 国产算力的结构性矛盾
当前国产算力芯片呈现“哑铃型”结构:
高端市场被英伟达 H100、A100 等产品垄断,国产芯片在算力密度(华为昇腾 910B 为 4096 TFLOPS vs H100 的 6240 TFLOPS)、内存带宽(昇腾 910B 为 600GB/s vs H100 的 2039GB/s)等核心指标上存在代际差距;
低端市场虽有寒武纪思元 270 等产品,但在能效比(思元 270 为 2.9TOPS/W vs A100 的 3.1TOPS/W)和软件生态适配性方面竞争力不足。中间层的海光 DCU 虽能兼容 ROCm 生态,但在大模型训练的稳定性上仍需验证。
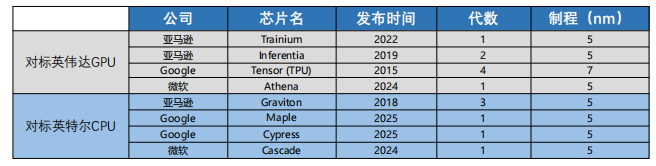
图:头部厂商自研AI芯片
二、技术突围路径: 从兼容模仿到自主创新
2.1 CUDA 兼容的生存策略
2.1.1 海光 DCU 的“类CUDA”技术路线
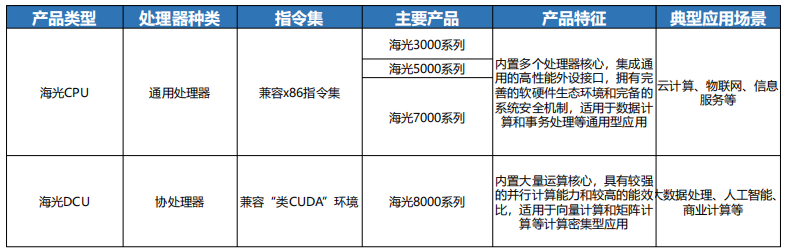
海光 DCU 通过ROCm 生态实现对 CUDA 的“软兼容”,采用 HIP(异构计算接口) 编译器将 CUDA 代码转换为ROCm 可执行代码,实测迁移效率可达 85%。
其深算二号产品在 FP16 精度下算力达 1024 TFLOPS,接近英伟达A100的90%,但在混合精度计算 (如 FP8)上仍存在 20%的性能差距。
这种兼容策略使海光在互联网行业快速突破,已获得百度、阿里等企业的大规模采购意向。
欢迎关注
2.1.2 华为 CANN 的“桥接生态”模式
华为CANN 架构创新性地采用“指令翻译+动态调度”技术,实现对 CUDA API的80% 覆盖。在鹏程·盘古大模型训练中,CANN 通过异构计算资源动态分配技术,将训练效率提升 30%。但这种兼容方式也带来额外开销,实测显示 CANN 运行 CUDA 原生代码时,性能损耗约 15%-20%。
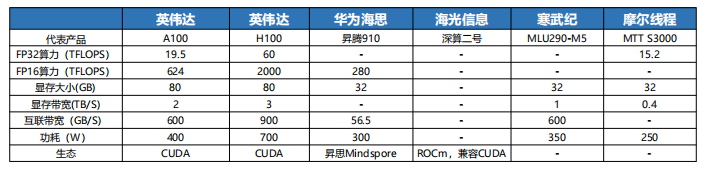
图:国内GPU与英伟达性能对比
2.2 原生生态的构建逻辑
2.2.1 华为昇思 MindSpore 的“全栈协同”创新异思框架通过“端云协同”架构,在手机端实现 Al 模型推理能耗降低 40%。其“自动微分+分布式训练”技术,使盘古 NLP 大模型训练速度提升2倍。在负责任AI领域,MindSpore内置的模型可解释性工具,已在金融风控领域实现模型决策透明度提升60%。
2.2.2 摩尔线程 MUSA 的“场景驱动”开发MUSA SDK创新性地将图形染与 AI计算深度融合,在自动驾驶仿真场景中,实现场景建模效率提升5 倍。其“Al加速光追”技术,使光线追踪性能达到英伟达 RTX 40 系列的 85%,但在生态应用数量上仍不足英伟达的 1/10。
三、产业生态博弈: 从单点突破到系统竞争
3.1 华为的全栈生态构建
3.1.1 硬件生态的垂直整合
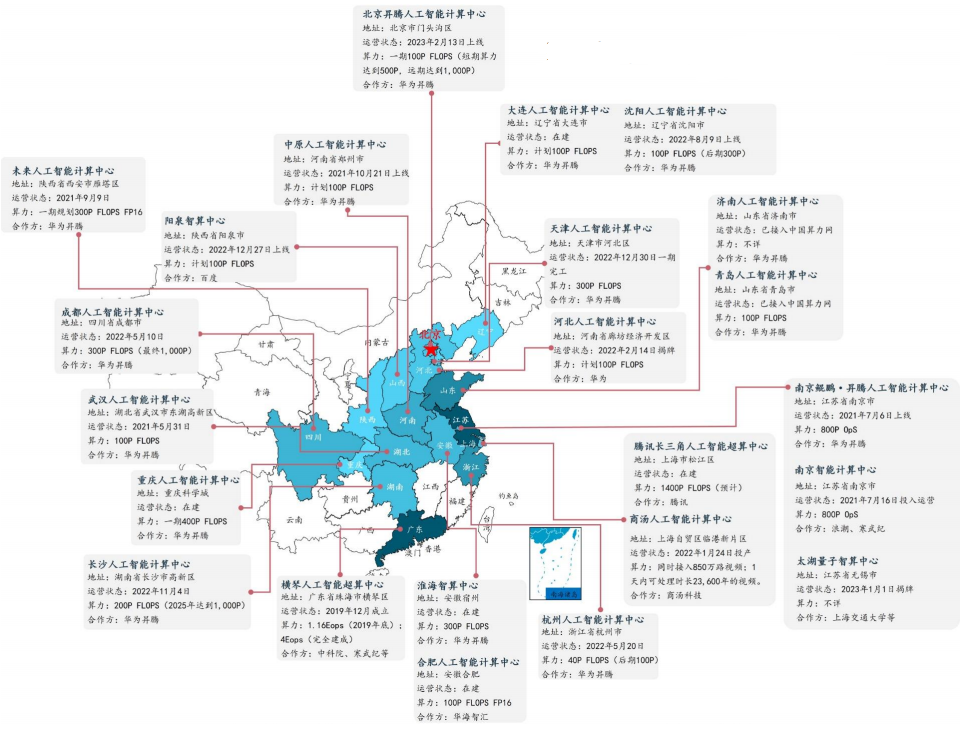
华为通过 “鲲鹏 + 昇腾” 双引擎战略,在智能计算中心建设中形成绝对优势。截至 2024 年底,华为参与建设的 23 个智算中心中,16 个采用昇腾架构,占比 69.6%。在上海人工智能计算中心,昇腾集群通过分布式存储优化技术,将数据读取速度提升 3 倍。
3.1.2 软件生态的开发者运营
昇思社区通过 “星火计划”,已培育 50 万开发者,孵化 1000 余个 AI 应用。其 “ModelArts” 开发平台,将模型开发周期从 3 个月缩短至 2 周。但与 TensorFlow 的 100 万全球开发者相比,仍需扩大生态影响力。
3.2.2 行业应用的深度渗透
在金融行业,海光 DCU 已实现量化交易策略执行速度提升30%。与中信证券合作的智能投研系统,通过DCU加速,研报生成效率提高2倍。但在互联网大厂的核心业务中,海光产品的渗透率仍不足 10%。
图:TensorFlow PyTorch, MindSpore和PaddlePaddle在支持超大规模模型训练方面处于领先
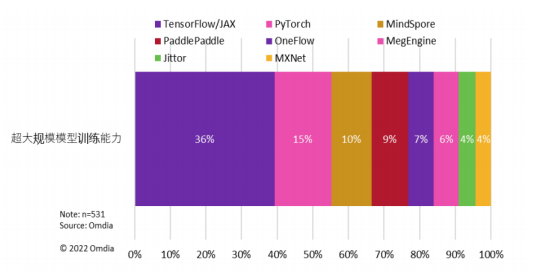
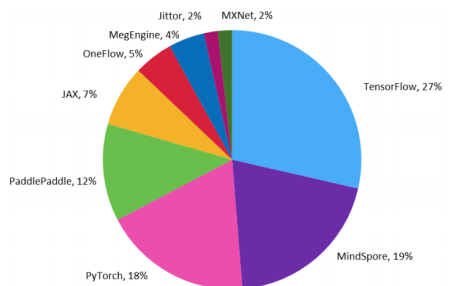
图:TensorFlow和MindSpore对人工智能提供的支持能力
3.3 寒武纪的边缘计算突围
3.3.1 云边端一体化架构
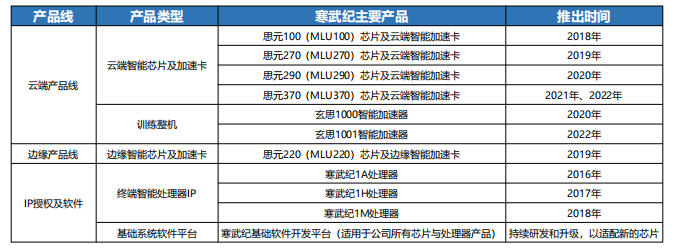
寒武纪“思元”系列芯片在边缘计算场景展现独特优势,思元 370在智能安防应用中,实现每秒 100路视频实时分析,功耗仅为 15W。其“MLU”架构创新性地将Al计算单元与存储单元融合,数据访问速度提升2倍。
3.3.2 政府市场的深度绑定
寒武纪在智慧城市项目中占据30% 市场份额,与北京市合作的“城市大脑”项目,通过寒武纪芯片实现交通拥堵预测准确率提升至 92%。但过度依赖政府订单,导致其营收季节性波动高达 40%。
四、政策驱动与市场需求的双重引警
4.1 政策体系的三维支持
4.1.1 资金支持体系
国家大基金三期已明确 2000 亿元投向国产算力,地方政府配套资金比例达 1:3。深圳设立 500 亿元人工智能产业基金,对国产算力企业提供 30% 研发补贴。
4.1.2 标准建设体系
工信部牵头制定《人工智能算力基础设施建设标准》,明确国产算力占比不低于 40% 的目标。在政务云领域,已强制要求 30% 算力采用国产芯片。
图:华为全栈 AI软硬件平台

4.1.3 生态培育体系
科技部“揭榜挂帅”机制,针对大模型训练、智能驾驶等场景,设立10 亿元专项奖金。华为昇腾的“沃土计划”已投入 20 亿元,用于开发者培训和应用孵化。
4.2 市场需求的结构性变化
4.2.1 政务市场的刚性需求
2024 年政务云算力采购中,国产芯片占比从 2020 年的 15% 提升至 38%。在国家“东数西算”工程中,贵州枢纽国产算力占比已达 55%。
4.2.2 行业应用的场景拓展
在金融行业,国产算力在反洗钱监测中的应用渗透率达 40%,风险识别准确率提升至 95%。在医疗影像领域,华为昇腾与联影医疗合作,实现 CT 影像诊断速度提升3倍。
4.2.3 互联网企业的渐进替代
百度已在部分搜索推荐业务中采用海光 DCU,性能损失控制在 10% 以内。字节跳动在边缘计算节点部署寒武纪芯片,单节点成本降低 25%。但在核心训练业务上,国产芯片渗透率不足 5%。
图:中国人工智能计算中心分布
五、未来趋势与挑战
5.1 技术演进方向
5.1.1 架构创新
类脑计算架构在寒武纪“玄思”项目中取得突破,能效比达到传统架构的3倍。存算一体技术在华为实验室实现突破,数据访问延迟降低 90%。
5.1.2 生态融合
昇思 MindSpore 与 Tensorflow 建立 API 兼容层,实现模型跨框架迁移。海光与 AMD 深化合作,计划在 2025年推出 ROCm 6.0 深度优化版本。
图:海光信息主要产品
5.2 产业发展挑战
5.2.1 性能追赶压力
国产 GPU在大模型训练的吞吐量上仍落后英伟达2代产品,训练一个1750 亿参数模型,国产方案耗时是英伟达的3倍。
5.2.2 生态建设瓶颈
国产开发框架的应用数量不足英伟达的 1/20,开发者生态活跃度仅为国际主流框架的 30%。
5.2.3 供应链风险
中芯国际 7nm 工艺良率仍在 75%-80% 区间波动,制约高端芯片量产。美国对华半导体设备出口限制,导致关键检测设备交付周期延长6-8个月。
图:寒武纪芯片产品面向云、边、端三大场景
5.3 市场竞争格局演变
5.3.1 短期格局(2025-2027)
华为将巩固政务、金融等领域优势,市场份额有望提升至35%。海光凭借互联网客户拓展,营收增速预计保持50% 以上。寒武纪在边缘计算市场占有率将突破 40%。
5.3.2 长期趋势(2028-2030)
若国产芯片在性能上实现“追平一代”在互联网训练市场占有率有望提升至 20%。华为、海光等企业将通过开源生态和国际合作,加速全球化布局。
六、结论
国产算力生态正处于从“生存驱动”向“创新驱动”的关键转折点。通过CUDA 兼容策略实现市场切入,依托全栈技术创新构建核心竞争力,借助政策支持和场景拓展形成规模效应,是当前国产算力企业的突围路径。
未来3-5年,随着技术代差缩小和生态体系完善,国产算力有望在全球竞争中占据重要地位,实现从“跟跑”到“并跑”的历史性跨越。
但需警惕技术封锁升级、.生态建设滞后等风险,持续强化底层技术创新和开发者生态培育,方能在全球算力竞争中立于不败之地。
来源于网络
大模型简史:从Transformer(2017)到DeepSeek-R1(2025) - 神经蛙没头脑的文章 - 知乎

清华大学:DeepSeek从入门到精通(2025) - 神经蛙没头脑的文章 - 知乎
【2025科技参考指南】全年重磅事件一览,你绝对不能错过! - 知乎
2025 年 GPU 风云再起:NVIDIA RTX 50 系列登场,RTX 5070 凭啥叫板 4090? - 知乎
NVIDIA GB200 Superchip及各厂家液冷服务器和液冷机柜介绍 - 知乎
【英伟达GB300即将登场!】从“短命”GB200到“升级版”GB300,这场科技革命你必须知道! - 知乎
一文看懂英伟达A100、A800、H100、H800各个版本有什么区别? - 知乎 (zhihu.com)
如何制造出比英伟达更好的GPU? - 知乎 (zhihu.com)
Nvidia B100/B200/GB200 关键技术解读 - 知乎 (zhihu.com)
大模型训练推理如何选择GPU?一篇文章带你走出困惑(附模型大小GPU推荐图) - 知乎 (zhihu.com)
一文看懂英伟达A100、A800、H100、H800各个版本有什么区别? - 知乎 (zhihu.com)
AI核弹B200发布:超级GPU新架构30倍H100单机可训15个GPT-4模型,AI进入新摩尔时代 - 知乎 (zhihu.com)

















 1655
1655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









