



一、背景
1、AI芯片发展背景
AI模型原先只是针对特定应用场景需求进行训练的小模型,小模型通用性差,换到另一个场景可能并不适用,需要重新训练,这其中需要消耗很多成本和时间。而随着数据、算力以及算法的提升,AI技术也有了很大的变化,从过去的小模型发展到现如今大模型的兴起。
大模型就是Foundation Model(基础模型),指通过在大规模宽泛的数据上进行训练后能适应一系列下游任务的模型。现如今很多企业都投身于大模型的研发当中,并且有些企业已经开发出了可以使用的、比较成熟的大模型产品,比如百度的文心一言、智谱华章的智谱清言、百川智能的百川大模型等。而无论是大模型的训练,还是大模型的推理环节,都需要较为庞大的数据量的传输,因此,现如今对AI芯片的需求快速增长,其市场规模也增长显著。
二、简介
AI芯片也被称为AI加速器或计算卡,从广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。但是通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片。
三、AI芯片分类
1、按照芯片的技术架构分
GPU
全名叫Graphics Processing Unit,即图形处理单元,在传统的冯·诺依曼结构中, CPU 每执行一条指令都需要从存储器中读取数据, 根据指令对数据进行相应的操作。 从这个特点可以看出, CPU 的主要职责并不只是数据运算, 还需要执行存储读取、 指令分析、 分支跳转等命令。深度学习算法通常需要进行海量的数据处理,用 CPU 执行算法时, CPU 将花费大量的时间在数据/指令的读取分析上, 而 CPU 的频率、 内存的带宽等条件又不可能无限制提高, 因此限制了处理器的性能。 而 GPU 的控制相对简单,大部分的晶体管可以组成各类专用电路、多条流水线,使得 GPU 的计算速度远高于 CPU; 同时,GPU 拥有了更加强大的浮点运算能力,可以缓解深度学习算法的训练难题,释放人工智能的潜能。但 GPU 无法单独工作,必须由 CPU 进行控制调用才能工作, 而且功耗比较高。
半定制化的 FPGA
全名叫Field Programmable Gate Array,即现场可编程门阵列,其基本原理是在FPGA芯片内集成大量的基本门电路以及存储器,用户可以通过更新 FPGA 配置文件来定义这些门电路以及存储器之间的连线。与 GPU 不同, FPGA 同时拥有硬件流水线并行和数据并行处理能力, 适用于以硬件流水线方式处理一条数据,且整数运算性能更高,因此,常用于深度学习算法中的推理阶段。不过 FPGA 通过硬件的配置实现软件算法,因此,在实现复杂算法方面有一定的难度。将 FPGA 和 CPU 对比可以发现两个特点, 一是 FPGA 没有内存和控制所带来的存储和读取部分,速度更快, 二是 FPGA 没有读取指令操作,所以功耗更低。 劣势是价格比较高、编程复杂、整体运算能力不是很高。 目前,国内的 AI 芯片公司如深鉴科技就提供基于 FPGA 的解决方案。
全定制化 ASIC
全名叫Application-Specific Integrated Circuit,即专用集成电路,是专用定制芯片,即为实现特定要求而定制的芯片。定制的特性有助于提高 ASIC 的性能功耗比,缺点是电路设计需要定制,相对开发周期长, 功能难以扩展。 但在功耗、可靠性、 集成度等方面都有优势,尤其在要求高性能、低功耗的移动应用端体现明显。谷歌的 TPU、寒武纪的 GPU,地平线的 BPU 都属于 ASIC 芯片。谷歌的 TPU 比 CPU 和 GPU 的方案快 30 至 80 倍,与 CPU 和 GPU 相比, TPU 把控制电路进行了简化,因此,减少了芯片的面积,降低了功耗。
神经拟态芯片
神经拟态计算是模拟生物神经网络的计算机制。 神经拟态计算从结构层面去逼近大脑,其研究工作还可进一步分为两个层次,一是神经网络层面,与之相应的是神经拟态架构和处理器,如 IBM 的 TrueNorth 芯片,这种芯片把定制化的数字处理内核当作神经元,把内存作为突触。 其逻辑结构与传统冯·诺依曼结构不同:它的内存、CPU 和通信部件完全集成在一起,因此信息的处理在本地进行,克服了传统计算机内存与 CPU 之间的速度瓶颈问题。同时,神经元之间可以方便快捷地相互沟通,只要接收到其他神经元发过来的脉冲(动作电位), 这些神经元就会同时做动作。 二是神经元与神经突触层面,与之相应的是元器件层面的创新。如 IBM 苏黎世研究中心宣布制造出世界上首个人造纳米尺度的随机相变神经元,可实现高速无监督学习。
2、按功能分
根据AI算法步骤,可分为训练(training)和推理(inference)两个环节。训练卡一般都可以作为推理卡使用,而推理卡努努力不在乎时间成本的情况下大部分也能作为训练卡使用,但通常不这么做。训练芯片通常拥有更高的计算能力和内存带宽,以支持训练过程中的大量计算和数据处理。相比之下,推理芯片通常会在计算资源和内存带宽方面受到一定的限制。同时,二者支持的计算精度也通常不同,训练阶段需要高精度计算,因此常用高精度浮点数如:fp32,而推理阶段一般只需要int8就可以保证推理精度。
除了高带宽高并行度外,就片内片外的存储空间而言训练芯片通常比较“大”,这是训练过程中通常需要大量的内存来存储训练数据、中间计算结果以及模型参数。相较而言推理芯片可能无法提供足够的存储容量来支持训练过程。
训练卡
训练环节通常需要通过大量的数据输入,训练出一个复杂的深度神经网络模型。训练过程由于涉及海量的训练数据和复杂的深度神经网络结构, 运算量巨大,需要庞大的计算规模, 对于处理器的计算能力、精度、可扩展性等性能要求很高。目前市场上通常使用英伟达的 GPU 集群来完成, Google 的 TPU 系列 、华为昇腾 910 等 AI 芯片也支持训练环节的深度网络加速。
推理卡
推理环节是指利用训练好的模型,使用新的数据去“推理”出各种结果。与训练阶段不同,推理阶段通常就不涉及参数的调整优化和反向传播了,它主要关注如何高效地将输入映射到输出。这个环节的计算量相对训练环节少很多,但仍然会涉及到大量的矩阵运算。在推理环节中,除了使用 CPU 或 GPU 进行运算外, FPGA 以及 ASIC 均能发挥重大作用。典型的推理卡包括NVIDIA Tesla T4、NVIDIA Jetson Xavier NX、Intel Nervana NNP-T、AMD Radeon Instinct MI系列、Xilinx AI Engine系列等。
四、国内AI芯片
1、AI芯片各参数含义
在查阅国内AI芯片相关资料时,会发现在各个厂商的官网上其AI芯片产品会有很多参数,如表1所示,不同参数的高低代表该芯片会应用于不同的场景,比如高精度、高内存、高带宽可能意味着该芯片适合应用于大模型的训练,而比较低的带宽和内存以及比较低的精度意味着该芯片可能用于大模型的推理环节。由于目前主流的AI处理器无疑是NVIDIA的GPU,并且,英伟达针对不同的场景推出了不同的系列和型号,因此将针对英伟达GPU各个产品的功能和参数详细解释AI芯片各个参数的含义。
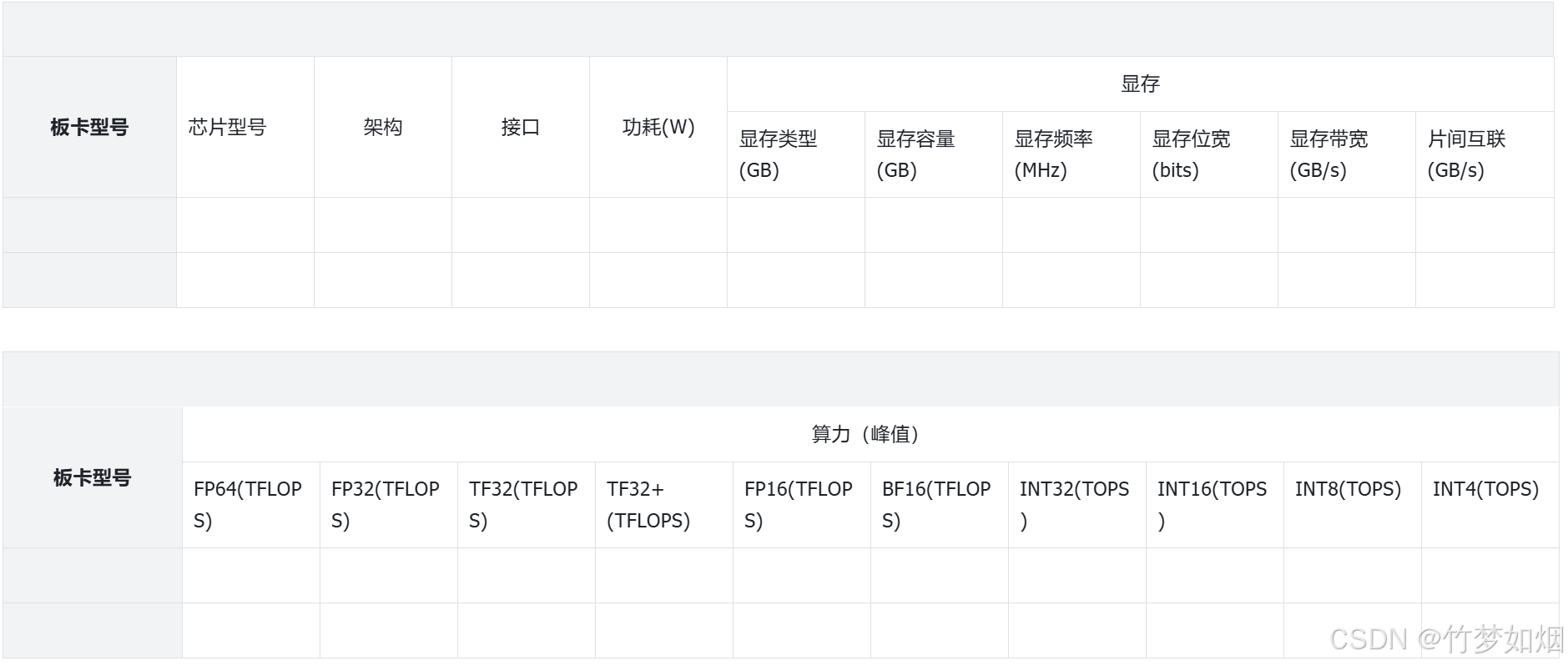
表1
目前NVIDIA的GPU产品主要有 GeForce、Data Center/Tesla 和 RTX/Quadro 三大系列,如下图所示,虽然,从硬件角度来看,它们都采用同样的架构设计,也都支持用作通用计算(GPGPU),但因为它们分别面向的目标市场以及产品定位的不同,这三个系列的GPU在软硬件的设计和支持上都存在许多差异。其中,GeForce为消费级显卡,而Tesla和Quadro归类为专业级显卡。GeForce主要应用于游戏娱乐领域,而Quadro主要用于专业可视化设计和创作,Tesla更偏重于深度学习、人工智能和高性能计算。
三大系列里每一系列又有多种产品,具体如下:
-
GeForce:
-
RTX 40系列(4080,4070Ti,4070,4060Ti,4060),
-
RTX 30系列(3090Ti,3090,3080Ti,3080,3070Ti,3070),
-
RTX 20系列(2080Ti,2080 SUPER,2080,2070 SUPER,2070),
-
GTX 16系列(1660Ti,1660 Super,1660, 1650 Super,1650(G5))
-
-
NVIDIA RTX/Quadro:
-
NVIDIA Ampere 架构:NVIDIA A40,NVIDIA A10,NVIDIA RTX A6000
-
NVIDIA Turing 架构:NVIDIA Quadro RTX 8000,NVIDIA Quadro RTX 6000
-
-
数据中心/Tesla:H100(H800),A100(A800),A40,A30,A16,A10,A2,L40,L40S,L4,V100......常见型号的参数如下:
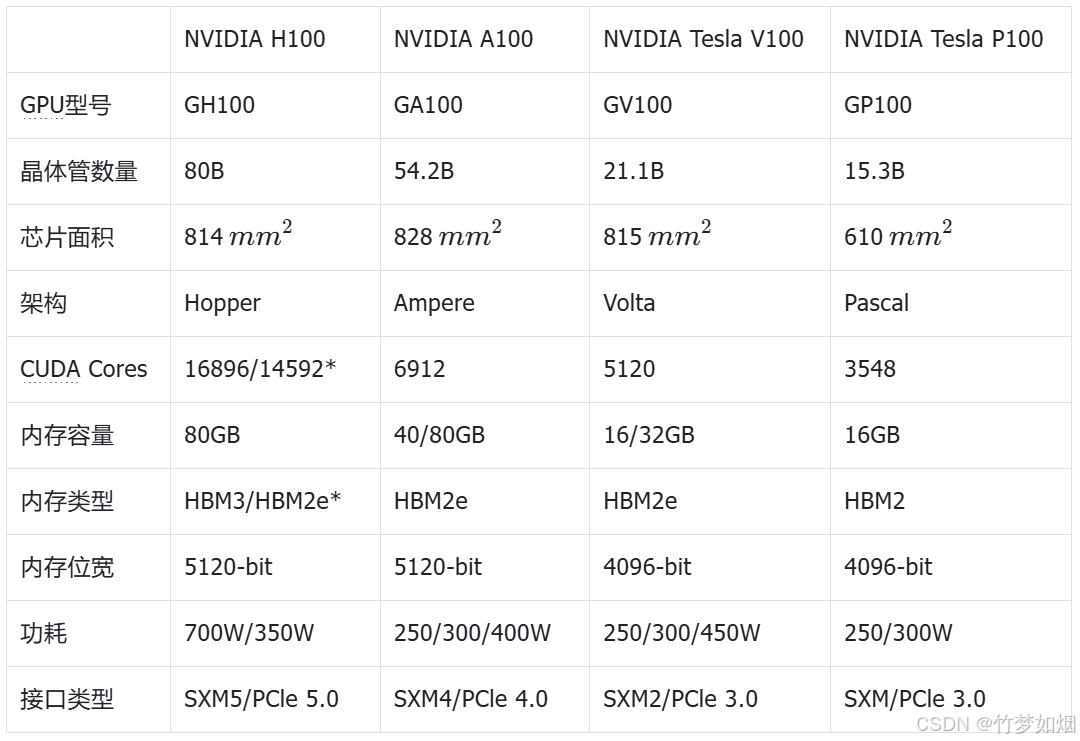
其中,A800/H800是针对中国特供版(低配版),相对于A100/H100,主要区别:
-
A100的Nvlink最大总网络带宽为600GB/s,而A800的Nvlink最大总网络带宽为400GB/s。
-
H100的Nvlink最大总网络带宽为900GB/s,而A800的Nvlink最大总网络带宽为400GB/s。
随着美国新一轮的芯片制裁,最新针对中国特供版H20、L20和L2芯片也将推出。
板卡型号&芯片型号
板卡通常指的是一个整体的硬件设备,它由多个组件组成,包括主要的芯片(例如CPU、GPU、FPGA等)、电路板、连接器、内存、电源管理等。板卡型号通常描述了整个硬件设备的型号或型号系列,以及其在特定领域或用途中的特性。比如,在图形处理领域,NVIDIA的显卡产品通常由一个板卡组成,其型号可能是类似于RTX 3080、GTX 1660 Ti等。
芯片则是板卡中的一个关键组件,它是一块半导体晶片,承担着计算、处理、存储等功能。CPU(中央处理器)、GPU(图形处理器)、ASIC(专用集成电路)等都是不同种类的芯片。芯片型号通常指的是这块半导体晶片的型号或系列,描述了其设计、制造和性能特征。比如,Intel的处理器可能有型号如i7-11700K、i9-12900K等。
联系:板卡通常包含了多个芯片,其中至少会有一个主要的芯片承担着核心的计算或处理任务。这些芯片的型号构成了板卡的关键组成部分。
区别:芯片型号是指半导体晶片的型号,描述了芯片本身的性能、制造工艺、规格等;而板卡型号是指整个硬件设备的型号,包括了多个组件,描述了整体设备的特性、用途等。
总体来说,芯片型号是指单个芯片的型号,而板卡型号则是指整个硬件设备的型号,两者之间具有层次关系,板卡中的芯片型号决定了板卡的核心性能。
如下表所示,NVIDIA公司的一些常用板卡以及其芯片型号。
|
NVIDIA H100 |
NVIDIA A100 |
NVIDIA Tesla V100 |
NVIDIA Tesla P100 | |
|
GPU型号 |
GH100 |
GA100 |
GV100 |
GP100 |
GPU架构
GPU架构是指图形处理器单元的设计和组织方式,包括处理器核心的数量、缓存结构、内部总线、存储器控制器等方面的设计。这些设计决定了GPU如何执行并行计算任务以及其在处理图形和其他计算密集型工作负载时的性能表现。
每一代 GPU 都有其独特的架构,随着技术的进步和新功能的引入,GPU架构也会不断演变和改进。例如,NVIDIA GPU架构历经多次变革,从起初的Tesla,到Turing架构,再到Ampere、Hopper,发展史可分为以下时间节点:
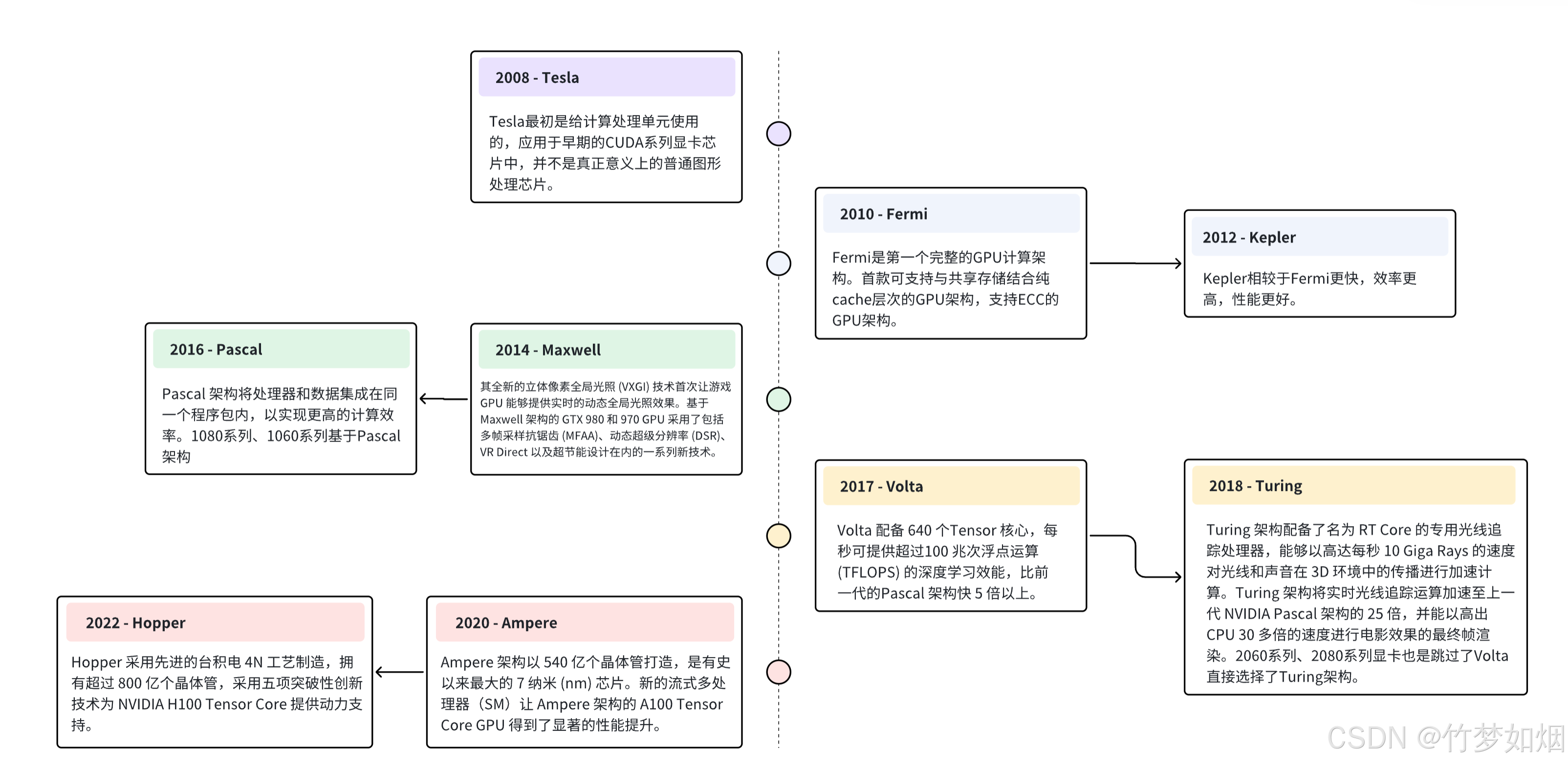
GPU架构的进步通常意味着更高的计算性能、更高的能效比、更好的并行计算能力、新的功能和特性的引入,以及更好的支持各种应用和工作负载。架构的不同特点和优势会影响到GPU在游戏、科学计算、深度学习等领域的表现和适用性。
对开发者和研究人员来说,了解GPU架构是重要的,因为它有助于优化程序以充分利用GPU的性能,并且能够更好地理解和评估不同GPU型号在不同应用场景下的性能差异。
接口
|
NVIDIA H100 |
NVIDIA A100 |
NVIDIA Tesla V100 |
NVIDIA Tesla P100 | |
|
接口类型 |
SXM5/PCIe 5.0 |
SXM4/PCle 4.0 |
SXM2/PCle 3.0 |
SXM/PCle 3.0 |
芯片接口类型指的是连接芯片(比如GPU)与主板或其他设备之间的物理接口标准。这些接口标准规定了芯片与系统之间数据传输的方式、速度和通信协议,不同的接口类型有着不同的特点和用途,常见的有PCle接口、SXM接口、OAM接口等,下面简要介绍各个类型:
-
PCIe(Peripheral Component Interconnect Express):PCIe是一种常见的高速串行接口标准,用于连接各种设备(如显卡、网卡、存储设备等)到主板上。它提供高带宽和低延迟的数据传输,常用于连接图形卡(GPU)到主板上,通过PCIe插槽进行数据传输。
-
SXM(Server-Grade System Mezzanine):SXM是一种特定于服务器级别的芯片连接标准。SXM模块通常是一种插槽式模块,比如NVIDIA的Tesla系列的GPU常常使用SXM连接方式,这种方式通过插槽或者连接器直接与服务器主板相连。
-
OAM(Omnipath Adapter Module):OAM是Intel推出的用于高性能计算和数据中心的高速互连标准。它不仅包括了物理连接接口,还涵盖了数据传输的协议和管理等方面。OAM用于连接高性能计算资源(如CPU、GPU等)以及网络设备,提供高速、低延迟的数据传输。
用途和应用场景:PCIe是通用的外部设备连接标准,SXM更多用于连接服务器级别的GPU加速器,而OAM主要用于高性能计算和数据中心的高速互连。
连接方式:PCIe通常通过插槽连接到主板,SXM直接插入服务器主板上的插槽,而OAM涉及到高速互连和通信协议。
功耗
芯片的最大热设计功率(TDP)是指在特定工作负载下,处理器或其他芯片能够稳定运行时所产生的最大热量。这个指标通常以瓦特(W)为单位表示,下表是一些比较常用的NVIDIA芯片的TDP数据。
|
NVIDIA H100 |
NVIDIA A100 |
NVIDIA Tesla V100 |
NVIDIA Tesla P100 | |
|
功耗 |
700W/350W |
250/300/400W |
250/300/450W |
250/300W |
可以看到,每一个板卡下对应的TDP有多个,这其实是表示该板卡内芯片以不同的连接方式连接时所导致的实际功耗不一样,比如NVIDIA H100板卡有两种封装形式,分别是SXM、PCle,两种连接方式对应的各种参数对比:
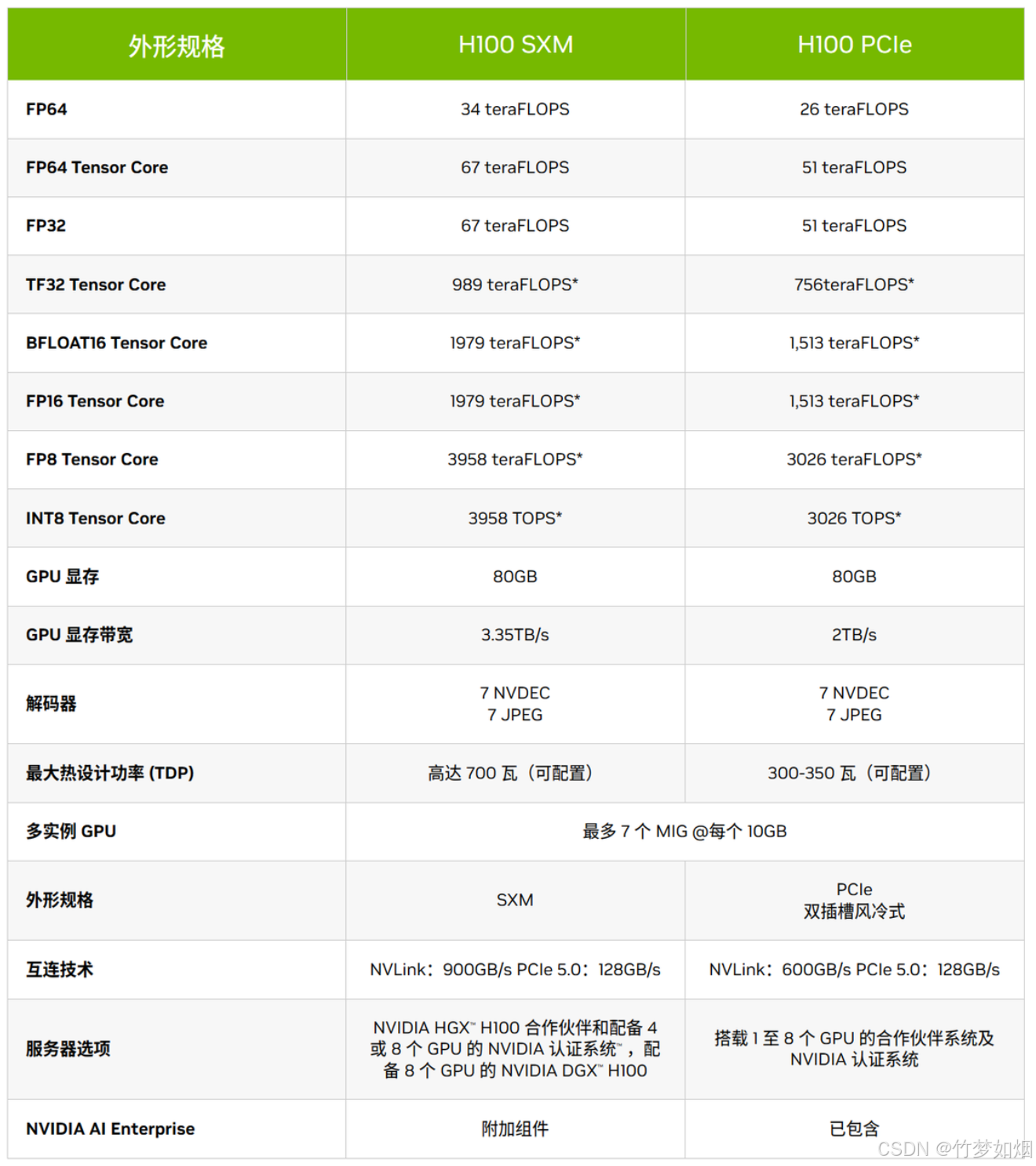
从上图可以看出,接口类型是SXM的板卡功耗要比接口类型是PCIe的板卡功耗要高得多,那么出现这个现象的原因如下:
虽然NVIDA GPU-SXM和NVIDA GPU-PCIe这两种卡都能实现服务器的通信,但是实现的方式是不一样的。SXM规格的一般用在英伟达的DGX服务器中,通过主板上集成的NVSwitch实现NVLink的连接,不需要通过主板上的PCIe进行通信,它能支持8块GPU卡的互联互通,实现了GPU之间的高带宽。
这里说的NVLink技术不仅能够实现CPU和GPU直连,能够提供高速带宽,还能够实现交互通信,大幅度提高交互效率,从而满足最大视觉计算工作负载的需求,因此这种类型接口的板卡功耗就比较高。
而NVIDA GPU-PCIe就是把PCIe GPU卡插到PCIe插槽上,然后和CPU、同一个服务器上其他的GPU卡进行通信,也可以通过网卡与其他的服务器节点上的设备进行通信,这种就是PCIe的通信方式,但是这种传输速度不快。如果想要和SXM一样,有很快的传输速度,可以使用NVlink桥接器实现GPU和CPU之间的通信,但是和SXM不一样的地方就是它只能实现2块GPU卡之间的通信。也就是说,如果有 2 个 PCIe GPU,那么可以使用 NVLink 桥接器(Bridge)实现互联;如果超过 2 个 PCIe GPU,就无法实现 NVLink 的分组互联,此时只能考虑使用 SXM GPU。基于此GPU连接数量的限制,其工作负载的需求必然比SXM要低,所以其功耗就比SXM板卡低。
GPU显存
不难看出,在各个厂商的芯片产品官网上,对应产品的信息中往往都会存在显存信息,接下来会具体介绍显存的各项参数都有什么作用。
GPU的内存硬件存储介质与CPU的类似,主要的区别是设计的结构有所差异。先说一下GPU内存硬件的分类,按照是否在芯片上面可以分为片上(on chip)内存和片下(off chip)内存,片上内存主要用于缓存(cache)以及少量特殊存储单元(如texture)特点是速度快,存储空间小;片下内存主要用于全局存储(global memory) 即常说的显存,特点是速度相对慢,存储空间大,不同于CPU系统内存可扩展的设计,GPU的内存硬件的大小整体都是固定,所以在选择好显卡型号后就会确定好,包括缓存和全局存储。
显存各类信息:
-
显存容量指的是显存能够存储的数据量,单位是GB,显存容量越大,能够存储的画面就越多,在玩游戏的时候不容易出现卡顿,目前主流显卡已经淘汰了512MB的显存,能够存储的数据也大幅提升了。
-
显存频率指的是显存工作的频率,单位是MHz,显存频率决定了数据在显存上存取的速度,显存频率越高,就可以更快地存取数据。这里要注意,显存频率和核心频率是两个概念,显存频率指的是显存的工作频率,而核显频率是GPU核心的频率,两者虽然单位一样,但是不能混淆。
-
显存位宽是指显存在一个时钟周期内能够传输数据的位数,单位是bit。显存位宽越大,瞬间传输的数据量就越大。
-
显存带宽指的是显示芯片与显存之间的数据传输速率,单位是GB/s。显存带宽是由显存频率,显存位宽决定的,显存带宽=工作频率×显存位宽/8bit。也就是说,显存带宽和显存频率及显存位宽成正比,频率越高,位宽越大,显卡的显存带宽就越高,存取性能就越强。
-
片间互联是指在多处理器系统中,各个处理器之间进行数据和控制信号传输的技术
对于不同的GPU,其显存往往有不同类型,而之所以会分为不同类型,通常都是因为其带宽和显存容量的不同导致其应用场景不同,比如NVIDIA GPU显存就有两种类型,GDDR和HBM,每一种也有不同型号,比如GDDR5、GDDR6、HBM2、HBM2e等。这两种型号的显卡采用不同的工艺制作,其带宽也不同,HBM 显存通常可以提供更高的显存带宽,但是价格也更贵,通常在训练卡上会使用,比如:H100、A100 等,而 GDDR 显存通常性价比更高,在推理 GPU 或游戏 GPU 更常见,比如:T4、RTX 4090 等。
常见的NVIDIA GPU的显存信息如下:
-
训练GPU显存信息:
|
训练卡 |
H100 SXM |
H100 PCle |
H200 |
A100 PCle |
A100 SXM |
V100 PCle |
V100S PCle |
|
显存类型 |
HBM3 |
HBM2e |
HBM3e |
HBM2 |
HBM2e |
HBM2 |
HBM2 |
|
显存大小 |
80GB |
80GB |
141GB |
80GB |
80GB |
32/16GB |
32GB |
|
显存带宽 |
3.35TB/s |
2TB/s |
4.8TB/s |
1935GB/s |
2039GB/s |
900GB/s |
1134GB/s |
-
推理GPU显存信息:
|
推理卡 |
L40s |
L40 |
L4 |
A40 |
A10 |
A30 |
|
显存类型 |
GDDR6 |
GDDR6 |
GDDR6 |
GDDR6 |
GDDR6 |
HBM2 |
|
显存大小 |
48GB |
48GB |
24GB |
48GB |
24GB |
24GB |
|
显存带宽 |
864GB/s |
864GB/s |
300GB/s |
696GB/s |
600GB/s |
933GB/s |
可以看到,NVIDIA的训练卡一般都是HBM类型的显存,这是因为训练卡通常注重计算性能和大规模并行计算能力。训练卡训练时需要大量的计算核心和显存容量来高效地处理大型数据集上的复杂计算任务,而HBM能够为人工智能训练提供高带宽与高显存。而相对应的NVIDIA的推理卡一般是GDDR类型,这是因为推理卡通常侧重于低延迟、能效和推理性能。它们可能在设计上更加注重功耗效率,并且优化了推理阶段的计算效率,这种时候并不需要和训练卡一样的高带宽和高显存需求,因此如上表所示,推理卡的带宽普遍都比较低。
算力
算力其实就是表格中对应的FP32、FP64、FP16、INT8等参数值,芯片算力越大,每秒能够进行的运算次数就越多,执行计算任务就越快。当涉及到深度学习和计算任务时,FP32、FP16 和 INT8是常用的数据类型,用于表示不同的数值精度和存储需求。
-
单精度(Fp32):浮点数使用32位表示,具有较高的精度和动态范围,适用于大多数科学计算和通用计算任务。通常我们训练神经网络模型的时候默认使用的数据类型为单精度FP32。
-
半精度(Fp16):浮点数使用16位表示,相对于FP32提供了较低的精度,但可以减少存储空间和计算开销。按照理论来说可以跑机器学习这些任务,但是FP16会出现精度溢出和舍入误差,所以很多应用都是使用混合精度计算的也就是FP16+FP32模式,简单来说FP16其实在图像处理有更大优势点。
-
双精度(Fp64):浮点数使用64位表示,提供更高的精度和动态范围。通常在需要更高精度计算的科学和工程应用中使用,相对于单精度,需要更多的存储空间和计算资源。
-
BFloat16(Bf16):是一种用于表示浮点数的16位数值格式,特别适用于深度学习中的计算任务。它主要用于表示神经网络中的权重和激活值,针对深度学习模型的训练和推理。bf16 具有和 fp32 相同的 range,但精度(也就是两个最小单位之间的间隔)降低,因此可以节省存储空间并提高计算效率。
-
固定点数(INT8):固定点数使用固定的小数点位置来表示数值,可以使用定点数算法进行计算。INT8与FP16、FP32的优势在于计算的数据量相对小,计算速度可以更快,并且能通过减少计算和内存带宽需求来提高能耗。
更高的精度通常意味着更准确的结果,但同时也需要更多的计算资源。所以,在设计芯片时,需要考虑算力和精度之间的平衡,以满足特定应用的需求。
特别的,NVIDIA Ampere架构引入了一种新的格式TF32格式,TF32是一种混合精度格式,用于表示32位浮点运算的一种优化形式,针对深度学习模型的训练和推理。TF32采用了低精度(16位)存储的方式来提高性能,但是在计算过程中会以32位精度进行累积。
大多数AI浮点运算采用16位“半”精度(FP16)、32位“单”精度(FP32),以及面向专业运算的64位“双”精度(FP64),人工智能训练的默认是FP32 ,没有张量核心(Tensor Core)加速度。 NVIDIA Ampere架构引入了TF32的新支持,使AI训练能够在默认情况下使用张量核心,非张量运算继续使用FP32数据路径,而TF32张量核心读取FP32数据并使用与FP32相同的范围,内部精度降低,然后生成标准 FP32输出。 TF32 使用与半精度 (FP16) 数学相同的10位尾数,表明其具有足够的余量来满足AI工作负载的精度要求。TF32采用与FP32相同的8位指数,因此可以支持相同的数值范围。这种组合使TF32成为FP32的绝佳替代品,用于处理单精度数学,特别是深度学习和许多HPC应用程序核心的大量乘法累加函数。
除此之外,Ampere架构还引入了Bfloat16 ( BF16 )的数据类型,BF16 / FP32混合精度张量核心运算的运行速度与FP16 / FP32混合精度相同。相对来说,在深度学习计算里,范围比精度要重要得多,于是有了BF16,牺牲了精度,保持和 FP32 差不多的范围,而TF32的设计,在于即汲取了BF16的好处,又保持了一定程度对主流 FP32 的兼容,FP32只要截断就是TF32 了。先截断成TF32计算,再转成FP32,对历史的工作几乎无影响。
2、国产AI卡资料汇总


















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









