







NVIDIA H100 和 H200 GPU对于加速 AI 和高性能计算 (HPC) 工作负载而言,性能至关重要。H100 于 2022 年发布,凭借其 Hopper 架构树立了标杆,而 H200(于 2024 年发布)则在此基础上进一步增强了内存、计算能力和能效。本文将对 H100 和 H200 进行对比,探讨它们的技术差异、性能指标和理想用例,以帮助您选择合适您需求的GPU产品。

H100 与 H200 的主要功能和规格
GPU 内存(容量、类型、带宽)
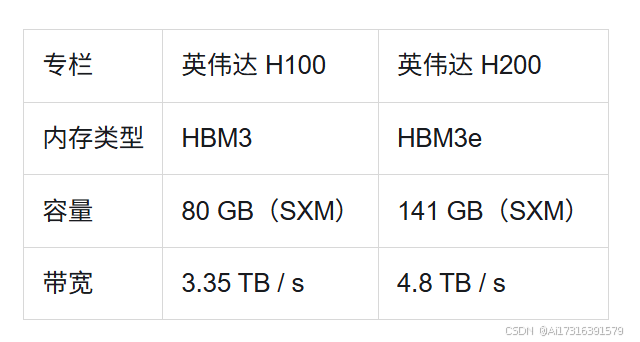
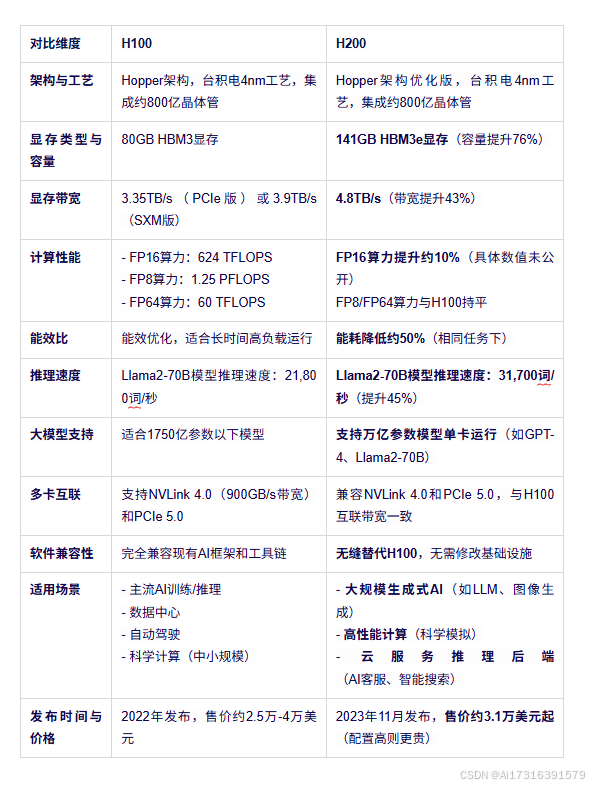
H200 的内存容量几乎比 H100 增加了一倍,带宽提高了 43%,显著减少了大型 AI 模型和数据密集型 HPC 任务中的瓶颈。
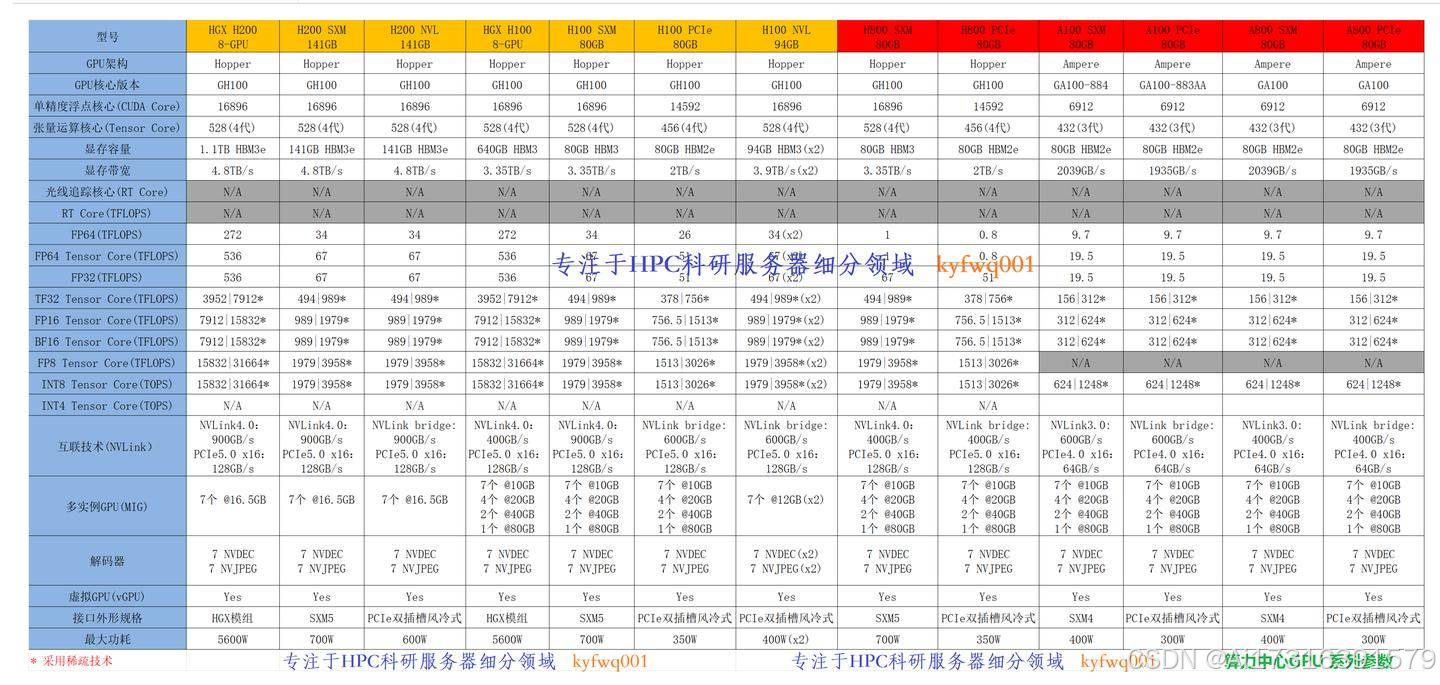
计算能力
NVIDIA H100 计算能力:
- 张量核心: H100 采用第四代 Tensor Cores,可增强深度学习和大规模神经网络的 AI 处理能力。
- 计算性能: 搭载第四代 Tensor Core 和 Transformer Engine,为大型语言模型提供高达 9 倍的训练速度和 30 倍的推理速度。支持 FP64、TF32、FP32、FP16、INT8 和 FP8 等多种精度。
- 用例: 非常适合大规模人工智能训练、实时推理、数据分析和基于模拟的任务。
NVIDIA H200 计算能力:
- 张量核心: H200 采用第四代 Tensor Cores,提供增强的 AI 加速,特别适用于大规模模型和复杂的机器学习任务。
- 计算性能: NVIDIA H200 的速度最高可提高 1.7 倍 LLM 推理性能和比 H1.3 NVL 好 100 倍的 HPC 性能,具有更高的可扩展性、内存和能源效率,使其成为企业数据中心中各种 AI 和 HPC 工作负载的理想选择。
- 用例: H200 专为下一代人工智能研究、自主系统、海量数据集的实时处理和大规模人工智能模型开发而设计。
热设计功率
- H100:可配置高达 700W,平衡功率和性能。
- H200:共享 700W 基本 TDP,但支持高达 1,000W 的极端工作负载,将每瓦性能效率提高 50% LLM 任务。
H100 和 H200 的应用和用例
H100 和 H200 均适用于繁重的计算工作量,但根据您的行业和需求,其中一款可能更适合您的要求。
H100 应用
- 人工智能和机器学习: 非常适合训练深度学习模型。
- 数据科学与分析: 适用于大规模数据处理。
- 科学研究: 非常适合模拟和研究密集型任务。
- 云计算: 由云服务提供商使用,以大规模运行 AI 和 ML 应用程序。
H200 应用
- 自动驾驶汽车: 需要实时处理传感器和摄像机产生的海量数据集。
- 下一代人工智能研究: 适合使用更多数据训练更大的AI模型。
- 医疗保健和生命科学: 用于基因组学和医学成像,需要大量计算能力进行实时分析。
- 机器人和边缘人工智能: 非常适合具有更高计算需求的机器人的边缘计算。
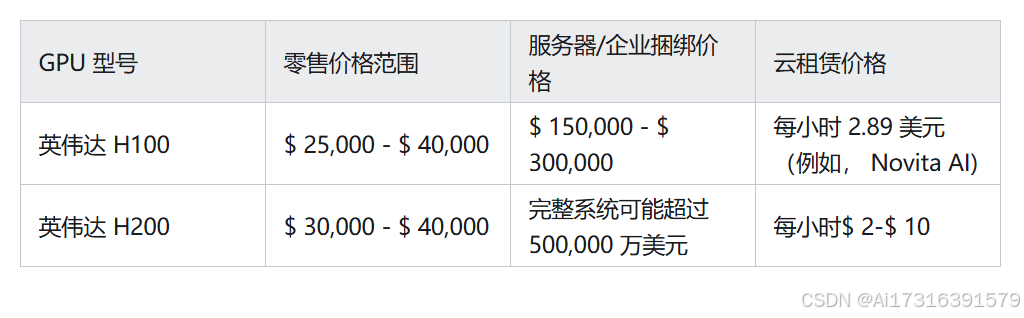
H100 和 H200 价格比较
以下是 NVIDIA H100 和 H200 价格比较表 GPUs:
如何在 H100 和 H200 之间进行选择
在 H100 和 H200 之间做出选择时,请考虑以下因素:
- 节能: 虽然两者 GPU与前代产品相比,H200 不仅提高了效率,其先进的设计还优先考虑了能源消耗,这可能是长期运营成本的一个重要因素,尤其是在大规模部署中。
- 性能需求:如果您需要为大型 AI 模型或 HPC 任务提供卓越的性能,H200 是您的不二之选。它拥有更佳的可扩展性和更强大的计算能力,是处理最苛刻工作负载的理想之选。
- 预算限制:H100 以较低的成本提供了出色的性能,对于不需要 H200 提供的最高性能的用户来说,它是一个更加经济实惠的选择。
- 未来的可扩展性:H200 增强的内存和带宽使其能够更好地应对日益增长的 AI 工作负载,尤其是在处理更大的数据集或更复杂的模型时。如果您计划在不久的将来扩展 AI 基础架构,H200 或许是一个更具可持续性的选择。


















 7796
7796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









