










哈喽,大家好~
咱们今天结合ARIMA,好好聊聊Transformer与ARIMA结合的混合时间序列建模问题~
在时间序列预测领域,传统方法与新兴技术一直在不断碰撞、融合,催生出更强大的预测模型。今天,咱们就深入探讨 Transformer 与 ARIMA 携手打造的混合时间序列建模,看看这对 “组合拳” 如何在预测战场上大显身手。
一、传统与前沿的相遇
ARIMA,这位时间序列预测界的 “老将”,凭借自回归(AR)、差分(I)和移动平均(MA)三大法宝,在处理平稳或差分后平稳的数据时游刃有余。它就像一位经验丰富的老工匠,能精准把握数据中稳定的线性趋势和周期性变化,比如电力消耗的日周期、季度性经济指标波动等。但面对数据里那些复杂多变、毫无规律可循的非线性部分,ARIMA 就稍显力不从心了。
核心公式:
一般记为 ARIMA(p, d, q),其数学表达式为
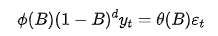
而 Transformer,作为深度学习领域的 “新星”,自注意力机制是它的 “秘密武器”。这一机制让它能像拥有 “透视眼” 一样,在海量数据中捕捉到任意位置之间隐藏的复杂关系,特别是那些非线性、长距离的依赖特征。不过,Transformer 也并非十全十美,直接用它处理时间序列,不仅需要大量数据 “喂养”,计算成本也高得惊人,在应对短期局部变化时还不够稳健。
核心公式:
最基础的自注意力机制公式为
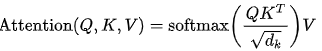
二、混合模型的神奇魔力
当 ARIMA 和 Transformer 相遇,一场时间序列预测的 “革命” 就此展开。混合模型的核心思路,是让两者各司其职,发挥各自的长处。
ARIMA 率先登场,负责捕捉数据中明显的线性趋势和周期性成分。想象一下,它像是在为后续的预测搭建一个坚实的框架,把数据中那些容易被识别的规律先梳理出来。完成这一步后,会得到一组残差,这些残差就像是数据中的 “神秘宝藏”,隐藏着 ARIMA 未能发现的非线性信息。
这时,Transformer 闪亮登场,对这些残差进行深度挖掘。它凭借强大的自注意力机制和多头注意力机制,从多个角度解析残差中的复杂模式,把那些 ARIMA 遗漏的细节一一找出来。最后,将 ARIMA 预测的线性部分和 Transformer 预测的残差部分相加,一个融合了传统统计规律和深层复杂模式的预测结果就诞生了,其精度远超单一模型。
三、实战演练:代码实现全解析
理论再精彩,也得靠实践来检验。下面咱们就通过代码,一步步搭建这个混合模型。
(一)数据生成与预处理
首先得有数据,这里用 Python 生成一段包含线性趋势、周期性波动、非线性平滑变化和随机噪声的虚拟时间序列数据。设置随机种子是为了保证每次运行代码生成的数据都一样,方便后续调试和对比结果。
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from statsmodels.tsa.arima.model import ARIMA
import warnings
warnings.filterwarnings("ignore")
np.random.seed(42)
torch.manual_seed(42)
def generate_synthetic_data(n=1000):
t = np.arange(n)
trend = 0.05 * t
seasonal = 10 * np.sin(0.2 * t)
nonlinear = 5 * np.tanh(0.01 * (t - 500))
noise = np.random.normal(0, 2, n)
y = trend + seasonal + nonlinear + noise
return t, y
t, y = generate_synthetic_data(n=1000)(二)ARIMA 模型建模与残差提取
接着,用 ARIMA 模型对数据进行拟合。这里选用ARIMA(2,1,2)模型,对数据进行一阶差分处理。拟合完成后,提取拟合值并计算残差,同时处理好因差分导致的数据索引问题,保证数据的准确性。
print("开始ARIMA模型拟合……")
model = ARIMA(y, order=(2,1,2))
arima_result = model.fit()
arima_pred = arima_result.fittedvalues
arima_pred_full = np.concatenate(([np.nan], arima_pred))
residuals_full = y - arima_pred_full
valid_index = ~np.isnan(arima_pred_full)
t_valid = t[valid_index]
y_valid = y[valid_index]
arima_pred_valid = arima_pred_full[valid_index]
residuals_valid = residuals_full[valid_index](三)构造 Transformer 训练数据
为了让 Transformer 能 “读懂” 残差数据,把残差序列整理成适合训练的格式。定义一个ResidualDataset类,将连续的一段残差作为输入,下一个时间步的残差作为标签,同时添加特征维度。
class ResidualDataset(Dataset):
def __init__(self, residuals, seq_len):
self.residuals = residuals
self.seq_len = seq_len
def __len__(self):
return len(self.residuals) - self.seq_len
def __getitem__(self, idx):
x = self.residuals[idx: idx + self.seq_len]
y_label = self.residuals[idx + self.seq_len]
return torch.tensor(x, dtype=torch.float32).unsqueeze(-1), torch.tensor(y_label, dtype=torch.float32)
seq_len = 20
dataset = ResidualDataset(residuals_valid, seq_len)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)(四)构造 Transformer 残差预测模型
搭建 Transformer 模型,包括线性升维层、位置编码层、Transformer 编码器层和解码层。位置编码层很关键,它给模型注入了数据的位置信息,让模型能区分不同时间步的数据。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=500):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2, dtype=torch.float) * (-np.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
if d_model % 2 == 1:
pe[:, 1::2] = torch.cos(position * div_term)[:, :pe[:, 1::2].shape[1]]
else:
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
class TransformerResidual(nn.Module):
def __init__(self, input_dim=1, d_model=64, nhead=4, num_layers=2, dim_feedforward=128, dropout=0.1, seq_len=20):
super(TransformerResidual, self).__init__()
self.input_linear = nn.Linear(input_dim, d_model)
self.pos_encoder = PositionalEncoding(d_model, dropout, max_len=seq_len)
encoder_layer = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers)
self.decoder = nn.Linear(d_model, 1)
def forward(self, src):
src = self.input_linear(src)
src = self.pos_encoder(src)
src = src.transpose(0, 1)
output = self.transformer_encoder(src)
output = output[-1]
output = self.decoder(output)
return output.squeeze(-1)(五)Transformer 模型训练
准备好模型、损失函数和优化器后,就可以开始训练 Transformer 模型了。在训练过程中,不断调整模型参数,让模型尽可能准确地预测残差。
model_transformer = TransformerResidual(seq_len=seq_len)
criterion = nn.MSELoss()
optimizer = optim.Adam(model_transformer.parameters(), lr=0.001)
print("开始Transformer模型训练……")
num_epochs = 50
losses = []
for epoch in range(num_epochs):
epoch_loss = 0.0
for batch_x, batch_y in dataloader:
optimizer.zero_grad()
pred = model_transformer(batch_x)
loss = criterion(pred, batch_y)
loss.backward()
optimizer.step()
epoch_loss += loss.item() * batch_x.size(0)
epoch_loss /= len(dataset)
losses.append(epoch_loss)
if (epoch + 1) % 10 == 0:
print(f'Epoch {epoch+1} / {num_epochs}, Loss: {epoch_loss:.4f}')(六)利用训练好的 Transformer 模型预测残差
训练结束后,用训练好的模型预测残差。这里通过滑动窗口的方式,对整个数据集进行预测。
model_transformer.eval()
transformer_preds = []
with torch.no_grad():
for i in range(len(dataset)):
x, y_val = dataset[i]
x = x.unsqueeze(0)
pred = model_transformer(x)
transformer_preds.append(pred.item())
transformer_preds = np.array(transformer_preds)(七)混合模型预测结果合成
最后,把 ARIMA 的预测结果和 Transformer 预测的残差相加,得到混合模型的最终预测结果,别忘了对齐数据。
combined_pred = arima_pred_valid[seq_len:] + transformer_preds
t_final = t_valid[seq_len:]
y_final = y_valid[seq_len:](八)综合数据分析图形
用可视化的方式展示整个过程和结果,包括原始数据与 ARIMA 拟合、残差序列与 Transformer 预测残差、Transformer 训练损失曲线以及混合模型预测与真实数据对比,这样能更直观地评估模型效果。
fig, axs = plt.subplots(2, 2, figsize=(18, 14))
axs[0, 0].plot(t, y, label='Original Data', color='tab:blue', linewidth=2)
axs[0, 0].plot(t_valid, arima_pred_valid, label='ARIMA Fitting', color='tab:orange', linewidth=2)
axs[0, 0].set_title('Original Data and ARIMA Fitting', fontsize=14)
axs[0, 0].set_xlabel('Time')
axs[0, 0].set_ylabel('Value')
axs[0, 0].legend()
axs[0, 0].grid(True, linestyle='--', alpha=0.7)
axs[0, 1].plot(t_valid, residuals_valid, label='Residual Series', color='tab:green', linewidth=2)
axs[0, 1].plot(t_valid[seq_len:], transformer_preds, label='Transformer Predicted Residual', color='tab:red', linewidth=2)
axs[0, 1].set_title('Residual Series and Transformer Prediction', fontsize=14)
axs[0, 1].set_xlabel('Time')
axs[0, 1].set_ylabel('Residual Value')
axs[0, 1].legend()
axs[0, 1].grid(True, linestyle='--', alpha=0.7)
axs[1, 0].plot(range(1, num_epochs + 1), losses, marker='o', label='Training Loss', color='tab:purple', linewidth=2)
axs[1, 0].set_title('Transformer Training Loss Curve', fontsize=14)
axs[1, 0].set_xlabel('Epoch')
axs[1, 0].set_ylabel('MSE Loss')
axs[1, 0].legend()
axs[1, 0].grid(True, linestyle='--', alpha=0.7)
axs[1, 1].plot(t_final, y_final, label='True Data', color='tab:blue', linewidth=2)
axs[1, 1].plot(t_final, arima_pred_valid[seq_len:], label='ARIMA Prediction', color='tab:orange', linestyle='--', linewidth=2)
axs[1, 1].plot(t_final, combined_pred, label='Hybrid Model Prediction', color='tab:red', linestyle='-.', linewidth=2)
axs[1, 1].set_title('Hybrid Prediction vs True Data', fontsize=14)
axs[1, 1].set_xlabel('Time')
axs[1, 1].set_ylabel('Value')
axs[1, 1].legend()
axs[1, 1].grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()从这些图表中可以清晰看到,ARIMA 很好地拟合了数据的整体趋势和周期性部分,Transformer 则在残差中挖掘出了复杂的非线性信息,混合模型在预测时更贴合真实数据,尤其是在非线性波动较大的区域,优势十分明显。
Transformer 与 ARIMA 的混合模型为时间序列预测开辟了新路径,但这只是个开始。未来,随着技术的不断进步,我们可以进一步优化模型结构,比如探索更合适的 Transformer 层数、注意力机制变体,或者尝试新的 ARIMA 参数选择方法。还能将更多的数据特征融入模型,像外部变量(如天气数据对能源消耗预测的影响)、数据的多模态信息等,让模型的预测能力更上一层楼。在实际应用中,金融市场预测、供应链管理、电力负荷预测等领域都有望从这一混合模型中获得更精准的预测结果,创造巨大的价值。
希望今天的分享能让大家对 Transformer 与 ARIMA 混合时间序列建模有更深入的理解,也期待大家能在自己的项目中尝试运用,挖掘出更多数据背后的秘密!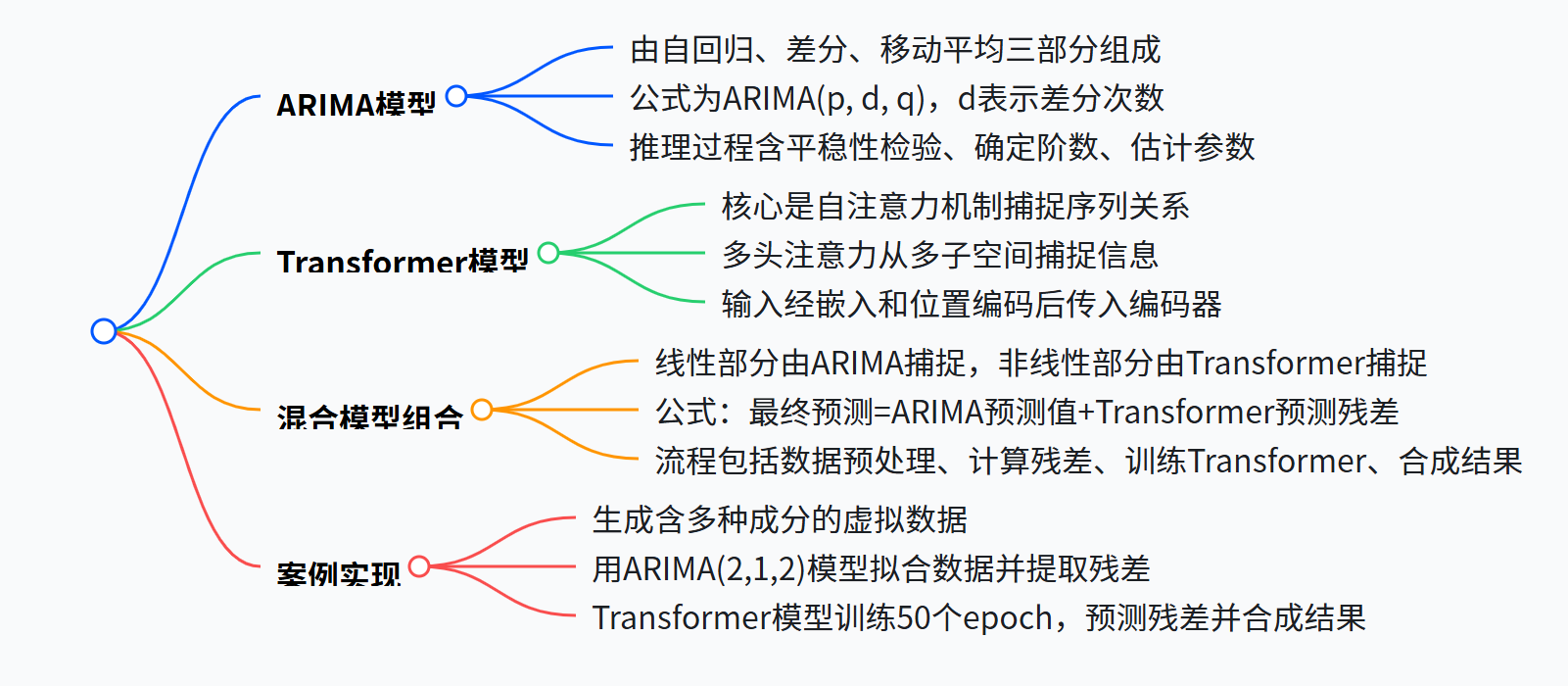
我这里有一份200G的人工智能资料合集:内含:990+可复现论文、写作发刊攻略,1v1论文辅导、AI学习路线图、视频教程等,看![]() 即可获取到!
即可获取到!


















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









