







Focal - Loss
- Focal -loss是交叉熵损失函数的变体,交叉熵损失函数公式如下:
C E ( p , y ) = − y l o g ( p ) − ( 1 − y ) l o g ( 1 − p ) = { − l o g ( p ) y = 1 − l o g ( 1 − p ) o t h e r w i s e CE(p , y) = -y log (p) - (1-y) log(1-p) = \begin{cases}- log (p) &y = 1 \\ - log(1 - p) &otherwise \end{cases} CE(p,y)=−ylog(p)−(1−y)log(1−p)={−log(p)−log(1−p)y=1otherwise - 其中
p
p
p可以理解为模型的预测结果,
y
y
y可以理解为数据的真实标签。
为了便于理解还是以二分类的思想去理解,为什么是二分类呢,因为类别除了1就是-1两个类别。首先从交叉熵函数进行理解。
C E ( p , y ) = { − l o g ( p ) y = 1 − l o g ( 1 − p ) o t h e r w i s e CE(p , y) = \begin{cases}- log (p) &y = 1 \\ - log(1 - p) &otherwise \end{cases} CE(p,y)={−log(p)−log(1−p)y=1otherwise - 当真实标签
y
=
1
y=1
y=1时,假如某个样本预测标签为1这个类的概率为0.6,也就是预测结果
p
=
0.6
p=0.6
p=0.6,那么损失就是
−
l
o
g
(
0.6
)
-log (0.6)
−log(0.6);如果
p
=
0.8
p=0.8
p=0.8,则损失为
−
l
o
g
(
0.8
)
- log (0.8)
−log(0.8),值得注意的是:
−
l
o
g
(
0.6
)
>
−
l
o
g
(
0.8
)
-log (0.6) > - log (0.8)
−log(0.6)>−log(0.8)。
为了方便用 p t p_t pt代替分段损失函数:
p t = { p y = 1 1 − p o t h e r w i s e p_t = \begin{cases} p &y = 1 \\ 1 - p &otherwise \end{cases} pt={p1−py=1otherwise -
p
t
p_t
pt是类别概率,衡量样本的难易程度,如果
p
t
p_t
pt较大,则代表是简单的样本,较小则代表是困难(复杂)样本。
− a t C E ( p t ) = − a t l o g ( p t ) = { − a t l o g ( p ) − ( 1 − a t ) l o g ( 1 − p ) - a_tCE(p_t) = -a_t log(p_t) = \begin{cases} -a_t log(p) \\ -(1 - a_t) log(1-p) \end{cases} −atCE(pt)=−atlog(pt)={−atlog(p)−(1−at)log(1−p) - 系数
a
t
a_t
at与
p
t
p_t
pt的定义类似,当真实标签
y
=
1
y = 1
y=1时,
a
t
=
a
a_t =a
at=a,当真实标签
y
=
−
1
y = -1
y=−1时,其参数为
1
−
a
t
=
1
−
a
1 - a_t = 1 - a
1−at=1−a(
a
a
a的范围是0~1)。可以设定
a
t
a_t
at的值来控制正负样本对总损失的共享权重。这里说到正负样本,一般而言,在检测任务中负样本数要比正样本数多很多,基本是3:1的比例。那么
a
t
a_t
at在retinaNet论文中取0.25,该系数在实现的代码中是以你的类别数来定义的,啥意思呢,就是他会给第一个正类一个0.25的系数因子,那么其余的类别就可以理解为负类,他们都是0.75的系数因子。这也就是说,正类的系数因子要小,而负类的系数因子要大,这也可以理解为,在计算损失的时候,一般的正负样本最后的比例都接近于1:3的系数比例,可想而知负样本(负类)对损失的影响有多大,所以负样本的系数因子更大一些,损失函数则更偏向于把负样本的损失一点点降低。这也正是解决了正负样本不均衡的问题。根据上面所说,
a
t
a_t
at解决了正负样本的问题,但是无法解决容易分类样本和难分类样本的问题,于是就有了接下来的公式:
F L ( p t ) = − ( 1 − p t ) γ l o g ( p t ) FL(p_t) = -(1 - p_t)^\gamma log(p_t) FL(pt)=−(1−pt)γlog(pt)
其中: − ( 1 − p t ) γ − − − − − − > p t = { p y = 1 1 − p o t h e r w i s e -(1 - p_t)^\gamma ------>p_t = \begin{cases} p &y = 1 \\ 1 - p &otherwise \end{cases} −(1−pt)γ−−−−−−>pt={p1−py=1otherwise - 这里称
γ
\gamma
γ为调制参数
(
γ
>
=
0
)
(\gamma >=0)
(γ>=0),
(
1
−
p
t
)
γ
(1 - p_t)^\gamma
(1−pt)γ称为调制系数。从上式可以看出:同样讨论对于一个二分类的问题,也就是两个类别讨论。当一个样本被分错时,也就是当标签类y = 1时,p = 0.3,根据上式可以看到,y=1 , p= 0.3 , 则
p
t
=
0.3
p_t = 0.3
pt=0.3,那么
(
1
−
p
t
)
γ
(1 - p_t)^\gamma
(1−pt)γ就很大(通常
γ
\gamma
γ取2)。这也就说明,分错的这个类表示难分的类。假如标签类y = 1或 -1,其 p = 0.8,那么
p
t
=
0.8
p_t = 0.8
pt=0.8,则
(
1
−
p
t
)
γ
(1 - p_t)^\gamma
(1−pt)γ就非常小,这也就是说,该类别容易分类。通过上面的例子,就是说,面对容易分的样本,
(
1
−
p
t
)
γ
(1 - p_t)^\gamma
(1−pt)γ调制系数比较小,面对复杂的样本,
(
1
−
p
t
)
γ
(1 - p_t)^\gamma
(1−pt)γ调制系数比较大。对于损失函数来说,调制系数小则对损失影响小,调制系数大则对损失影响大,这也就实现了损失函数关于容易分类和复杂分类样本的处理。
综上 a t , ( 1 − p t ) γ a_t ,(1 - p_t)^\gamma at,(1−pt)γ即实现了调节正负样本的问题,也解决了难易分类样本的问题。
最后的Focal Loss函数为:
F L ( p t ) = − a t ( 1 − p t ) γ × C E ( p t ) FL(p_t) = - a_t (1- p_t) ^\gamma \times CE(p_t) FL(pt)=−at(1−pt)γ×CE(pt)
下图是 γ \gamma γ取不同数值时 F o c a l L o s s Focal Loss FocalLoss损失函数的图像,其中 γ = 0 \gamma = 0 γ=0就是交叉熵损失函数。
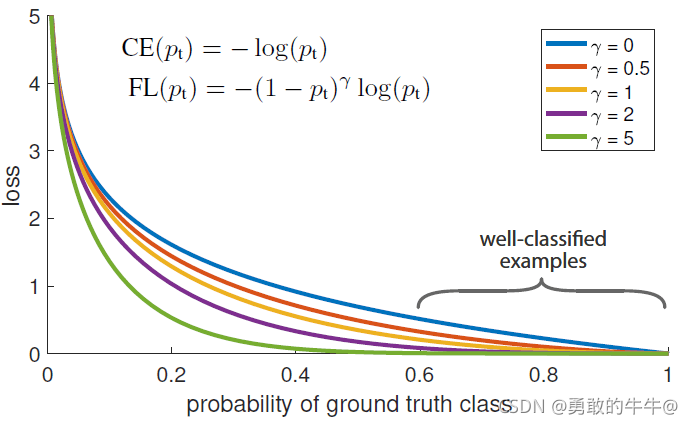
对于Focal Loss的使用,有以下几个版本,但是还是具体看自己使用在哪个模型中,从RetinaNet的文章中以及众多的解释中,对于目标检测任务而言,应用于分类类别损失是做好的。如果小伙伴有了解的话,我用的YOLOv4模型,他的总损失包括边界框回归损失,置信度损失和分类类别损失,共三种损失组成,目前直接可以用的就是替换掉类别的分类损失,而对于v4中,分类的原损失函数用的BCELoss,里面涉及到标签平滑技术,但是也是可以直接根据Focal Loss的函数来改进,希望想把yolo的类别分类损失换成Focal Loss损失的小伙伴一起交流。下面是几个比较好的Focal Loss代码(下了好多版本,最后还是基于原v4的BCELoss损失函数基础上改的):下面的代码在原基础上给出了详细的中文注释,希望帮助到你~~
class FocalLoss(nn.Module):
def __init__(self, apply_nonlin=None, alpha=None, gamma=2, balance_index=0, smooth=1e-5, size_average=True,cuda=False):
super(FocalLoss, self).__init__()
self.apply_nonlin = apply_nonlin
self.alpha = alpha
self.gamma = gamma
self.balance_index = balance_index
self.smooth = smooth
self.size_average = size_average
self.cuda = cuda
if self.smooth is not None:
if self.smooth < 0 or self.smooth > 1.0:
raise ValueError('smooth value should be in [0,1]')
def forward(self, pred, target):
if self.apply_nonlin is not None:
pred = self.apply_nonlin(pred)
num_class = pred.shape[1]
#判断pred的维度是否大于2
if pred.dim() > 2:
# N,C,d1,d2 -> N,C,m (m=d1*d2*...)
#将输入的维度修改为N,C,d1,d2 -> N,C,m
pred = pred.view(pred.size(0), pred.size(1), -1)
#-->在上面的pred函数中我们得到pred的维度是N,C,m,
#-->permute函数是百年换tensor的维度 -- N,C,m --> N,m,C
#--contiguous函数会拷贝一份变换前的输入
pred = pred.permute(0, 2, 1).contiguous()
#-->同样是将输入同一输入维度--N,m,C --> N*m行C列 限定在一个矩阵内
pred = pred.view(-1, pred.size(-1))
# torch.squeeze(input,dim,out)
#--> torch.squeeze 同样是压缩数据的维度
target = torch.squeeze(target, 1)
#--> 将输出的target维度限制1列
target = target.view(-1, 1)
#print(pred.shape, target.shape)
alpha = self.alpha
if alpha is None:
#-->alpha-全1(维度为:输入类别数行,1列)
alpha = torch.ones(num_class, 1)
# isinstance() 函数,是Python中的一个内置函数,用来判断一个函数是否是一个已知的类型。
#isinstance(a,(str,int,list)) a的类型是元组中的一个,结果返回 True
#如果对象的类型与参数二的类型相同则返回 True,否则返回 False。
elif isinstance(alpha, (list, np.ndarray)):
# assert 检查程序,不符合条件即终止程序
assert len(alpha) == num_class
# 将alpha的维度限制在num_class行1列,具体数值为alpha
alpha = torch.FloatTensor(alpha).view(num_class, 1)
#alpha.sum()是一个数,因为alpha为n行一列的数,所以alpha.sum是alpha的和
alpha = alpha / alpha.sum()
elif isinstance(alpha, float):
#alpha是Num_class行1列的全一的矩阵
alpha = torch.ones(num_class, 1)
# 一般alpha取0.25,故alpha等于n行1列全是0.75的数
alpha = alpha * (1 - self.alpha)
alpha[self.balance_index] = self.alpha
else:
raise TypeError('Not support alpha type')
'''
if cuda:
alpha = torch.from_numpy(alpha).type(torch.FloatTensor).cuda()
else:
alpha = torch.from_numpy(alpha).type(torch.FloatTensor)
'''
#if alpha.device != pred.device:
alpha = alpha.to(pred.device)
#转变成long类型
idx = target.cpu().long()
one_hot_key = torch.FloatTensor(target.size(0), num_class).zero_()
one_hot_key = one_hot_key.scatter_(1, idx, 1)
#if one_hot_key.device != pred.device:
one_hot_key = one_hot_key.to(pred.device)
if self.smooth:
one_hot_key = torch.clamp(
one_hot_key, self.smooth / (num_class - 1), 1.0 - self.smooth)
pt = (one_hot_key * pred).sum(1) + self.smooth
logpt = pt.log()
gamma = self.gamma
alpha = alpha[idx]
alpha = torch.squeeze(alpha)
loss = -1 * alpha * torch.pow((1 - pt), gamma) * logpt
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss
版本二
class focal_loss(nn.Module):
def __init__(self, alpha=0.25, gamma=2, num_classes=5, size_average=True):
"""
focal_loss损失函数, -α(1-yi)**γ *ce_loss(xi,yi)
步骤详细的实现了 focal_loss损失函数.
:param alpha: 阿尔法α,类别权重. 当α是列表时,为各类别权重,当α为常数时,类别权重为[α, 1-α, 1-α, ....],常用于 目标检测算法中抑制背景类 , retainnet中设置为0.255
:param gamma: 伽马γ,难易样本调节参数. retainnet中设置为2
:param num_classes: 类别数量
:param size_average: 损失计算方式,默认取均值
"""
super(focal_loss, self).__init__()
self.size_average = size_average
if isinstance(alpha, list):
assert len(alpha) == num_classes # α可以以list方式输入,size:[num_classes] 用于对不同类别精细地赋予权重
print(" --- Focal_loss alpha = {}, 将对每一类权重进行精细化赋值 --- ".format(alpha))
self.alpha = torch.Tensor(alpha)
else:
assert alpha < 1 # 如果α为一个常数,则降低第一类的影响,在目标检测中为第一类
print(" --- Focal_loss alpha = {} ,将对背景类进行衰减,请在目标检测任务中使用 --- ".format(alpha))
self.alpha = torch.zeros(num_classes)
self.alpha[0] += alpha
self.alpha[1:] += (1 - alpha) # α 最终为 [ α, 1-α, 1-α, 1-α, 1-α, ...] size:[num_classes]
self.gamma = gamma
def forward(self, preds, labels):
"""
focal_loss损失计算
:param preds: 预测类别. size:[B,N,C] or [B,C] 分别对应与检测与分类任务, B批次, N检测框数, C类别数
:param labels: 实际类别. size:[B,N] or [B] [B*N个标签(假设框中有目标)],[B个标签]
:return:
"""
# 固定类别维度,其余合并(总检测框数或总批次数),preds.size(-1)是最后一个维度
preds = preds.view(-1, preds.size(-1))
self.alpha = self.alpha.to(preds.device)
# 使用log_softmax解决溢出问题,方便交叉熵计算而不用考虑值域
preds_logsoft = F.log_softmax(preds, dim=1)
# log_softmax是softmax+log运算,那再exp就算回去了变成softmax
preds_softmax = torch.exp(preds_logsoft)
# 这部分实现nll_loss ( crossentropy = log_softmax + nll)
preds_softmax = preds_softmax.gather(1, labels.view(-1, 1))
preds_logsoft = preds_logsoft.gather(1, labels.view(-1, 1))
self.alpha = self.alpha.gather(0, labels.view(-1))
# torch.pow((1-preds_softmax), self.gamma) 为focal loss中 (1-pt)**γ
# torch.mul 矩阵对应位置相乘,大小一致
loss = -torch.mul(torch.pow((1 - preds_softmax), self.gamma), preds_logsoft)
# torch.t()求转置
loss = torch.mul(self.alpha, loss.t())
# print(loss.size()) [1,5]
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss
QFocal - Loss
从上面的公式中我们可以看出,Focal Loss 只支持 0/1 这样的离散类别 label(二分类&多分类问题,0就是一类,1就是一类)。但对于 smooth (比如标签平滑)的 label(分数:0 ~ 1之间)是无能为力的,因此就引申出了 Quality Focal Loss (QFL):
Q
F
L
(
σ
)
=
−
a
t
∗
∣
y
−
σ
∣
β
∗
[
(
1
−
y
)
l
o
g
(
1
−
σ
)
+
y
l
o
g
(
σ
)
]
QFL(\sigma) = -a_t * |y - \sigma|^\beta * [(1 - y)log(1 - \sigma)+ylog(\sigma)]
QFL(σ)=−at∗∣y−σ∣β∗[(1−y)log(1−σ)+ylog(σ)]
F
L
(
p
t
)
=
−
a
t
(
1
−
p
t
)
γ
×
C
E
(
p
t
)
FL(p_t) = - a_t (1- p_t) ^\gamma \times CE(p_t)
FL(pt)=−at(1−pt)γ×CE(pt)
其中,
y
y
y是smooth(标签平滑技术)后的label(0~1),
σ
\sigma
σ是预测结果。拆分一下:
a
t
=
y
∗
a
+
(
1
−
y
)
∗
(
1
−
a
)
a_t = y *a + (1-y) * (1 - a)
at=y∗a+(1−y)∗(1−a) //平衡正负样本
∣
y
−
σ
∣
β
|y - \sigma|^\beta
∣y−σ∣β //平衡难易样本
C
E
(
y
,
σ
)
=
−
[
(
1
−
y
)
l
o
g
(
1
−
σ
)
+
y
l
o
g
(
σ
)
]
CE(y,\sigma) = -[(1-y)log(1-\sigma) + ylog(\sigma)]
CE(y,σ)=−[(1−y)log(1−σ)+ylog(σ)] //CELoss
相比较Focal Loss损失函数,平衡正负样本由最初的
a
t
=
0.25
a_t=0.25
at=0.25变成了
a
t
=
y
∗
a
+
(
1
−
y
)
∗
(
1
−
a
)
a_t = y *a + (1-y) * (1 - a)
at=y∗a+(1−y)∗(1−a) ,平衡难易样本由
(
1
−
p
t
)
γ
(1-p_t)^\gamma
(1−pt)γ变成了
∣
y
−
σ
∣
β
|y - \sigma|^\beta
∣y−σ∣β,最后都是基于CELoss交叉熵损失函数。比如在YOLOv4中,如果对分类损失直接使用Focal Loss存在一定的问题,在实际的训练中,我使用Focal Loss损失函数,训练产生的总损失明显不收敛且不稳定,因为在v4中使用了标签平滑技术,但是QFocal Loss解决了这个问题,总的来说对于发一些应用型的论文期刊,这个改进还是很值得的。
class QFocalLoss(nn.Module):
# Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super().__init__()
self.loss_fcn = loss_fcn # 基于 nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # 需要将 FL 应用于每个元素
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred) # prob from logits
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = torch.abs(true - pred_prob) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss


















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











