






MAE原文解读
提示:这里可以添加技术概要
MAE采用了一种自编码的方法,给定部分观测量,重建原始信号。下面是MAE的架构图:
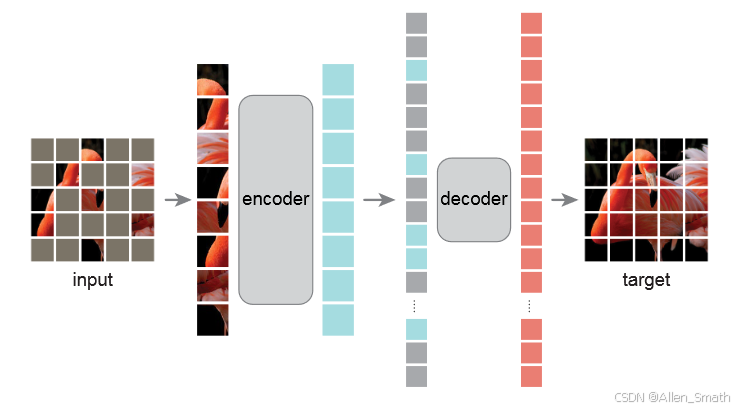
与大多数自编码器一样,采用了一个编码器将观测的信号映射到隐层表示空间,然后使用一个解码器从隐层空间中重建原始信号。与传统自编码器不同,这里采用了一种非对称设计,编码器只能对可观测的部分进行操作(不包含mask tokens),一个轻量化的解码器可以从隐层空间和掩码部分重建完整的信号。
掩码策略
和ViT一样,我们把图像分割成常规的,没有重叠的patches。然后采样一个子集并对其他部分进行掩码(例如,移除这些部分)。采样策略是非常直接的:根据均匀分布,随机采样一些无重叠的patches。
使用较高掩码率的随机采样能够更大程度地去冗余,因此可以构建一个预训练任务,这个任务不能简单根据可见的邻居patch推断完成(也就是说,如果掩码率很低,那么就有可能通过相邻可见的patch通过插值法实现推断)。均匀分布还可以消除潜在的中心偏差(例如,图像中间的掩码patches更多)。通过这种高度稀疏的输入,为设计一个高效的编码器提供基础。
编码器设计
编码器是ViT,但是仅针对可见的、非掩码的patches。和标准的ViT一样,我们的编码器给使用一个线性投影层对patches进行转换,并加上了位置编码。然后加上一系列Transformer层。编码器没有对完整的图像进行训练,因此,这样训练出来的编码器不需要大量的计算和存储,就能够做得很大。
解码器设计
解码器的输入包含完整的token输入,包括编码器输入的可见的patches和掩码tokens。每个掩码token都是一个共享的、可学习的向量,表示了对一个确实patch的预测,另外对所有tokens增加了位置编码,如果没有位置编码掩码token就不知道自己在图像中的位置。另外,解码器由一系列Transformer层组成。
解码器只是在预训练执行图像重建任务中使用(只有编码器用于后续下游特征提取任务)。因此,解码器的结构可以以独立于编码器结构的方式灵活设计。例如,我们默认的解码器比编码器每个token计算量少10%。这样大大减少了预训练时间。
重建目标
MAE重建输入图像,通过预测每个掩码patch的像素值。decoder输出的每个元素代表着一个patch的像素值。解码器的最后一层是线性层,输出通道数量等于一个patch的像素值数量。将解码器的输出reshape就可以得到重建的图像。损失函数是计算重建图像和原始图像在像素空间的MSE损失。在计算损失的时候只计算掩码patches的损失,和BERT类似。
我们还尝试了一种变体,计算一个patch中所有像素的均值和方差,然后使用它们来归一化这个patch。用归一化的像素作为重建目标提升了表征能力。
部署
首先为每一个输入patch生成一个token(通过线性投影+位置编码);然后随机打乱这些token,移除这些token的最后一部分(基于掩码率);这个过程产生了一个小的子集,作为编码器的输入。之后,我们将掩码子集和编码器训练子集合并,再进行unshuffle,将所有token和他们的目标对齐。对这个完整的token列表使用解码器。这个简单操作引入的开销可以忽略不记,因为shuffling和unshuffling是非常快的。
关键部分代码解读
提示:这里可以添加技术整体架构
MAE最复杂的部分在于掩码和掩码的反操作,下面这个函数描述了这个过程:
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D],N表示batch_size,L表示patches的个数,D表示每个patch的特征维度
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))#mask_ratio表示掩码率,这里计算的是保留的patch数
if self.focus_range is not None:
len_mask = L - len_keep
weights = [1-self.focus_rate] * L
weights[self.focus_range[0] // self.patch_size : self.focus_range[1] // self.patch_size
] = [self.focus_rate] * (self.focus_range[1] // self.patch_size - self.focus_range[0] // self.patch_size)
weights = torch.tensor(weights).repeat(N, 1).to(x.device)
ids_mask = torch.multinomial(weights, len_mask, replacement=False)
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
if self.focus_range is not None:
for i in range(N):
noise[i, ids_mask[i,:]] = 1.1 # set mask portion to 1.1
# sort noise for each sample
#torch.argsort 使输入张量元素在指定维度,按从小到大排的索引
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
#再用一次,得到一个反向映射,即从打乱后回到原始索引的映射
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
#torch.gather可以根据提供的索引,从输入张量中收集元素,dim表示收集的维度
#unsqueeze(-1)表示在最后加一个维度,就变成了(N,len_keep,1);repeat(1,1,D)表示在最后一个维度复制D次变成(N,len_keep,D)
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore


















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









