







前言
其实在学过线性支持向量机的学习算法以及它的最优化问题数学形式的时候,非线形支持向量机的就很好理解了,唯一不同的是
x
i
∗
x
j
xi *xj
xi∗xj变成
K
(
x
i
∗
x
j
)
K(xi*xj)
K(xi∗xj)了

常用的核函数

带进去就完事。
smo个人白话理解
smo算法要做的基本思路是,如果所有的
α
i
\alpha_{i}
αi都满足KKT那么这个最优解就找到了。它选择两个变量(
α
1
,
α
2
\alpha_{1},\alpha_{2}
α1,α2),而固定其他变量,每次让这两个变量的解更接近原始问题的解,这样不断的选择两个变量去接近,最终会与原始问题的解无限接近。
这两个变量的选择是有要求的:
- 一个变量是违反KKT最严重的那一个;
- 另一个根据约束条件自动确定。
在选择变量之前,我们需要知道如果选择两个值,固定其他值会发生的变化。
首先之前的最优化问题将可以转为无数如下形式的子问题:

约束条件:

α
2
\alpha_{2}
α2在不同的条件下,考虑不等式约束时,是不同的:

那么在不考虑不等式约束之前,是如何计算的到的呢?计算公式如下,如何推导看书去。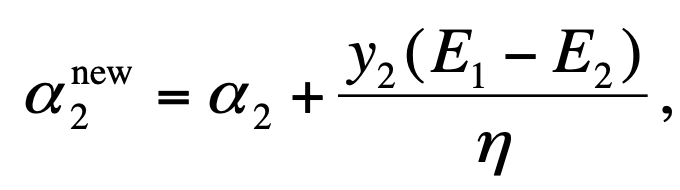
其中:
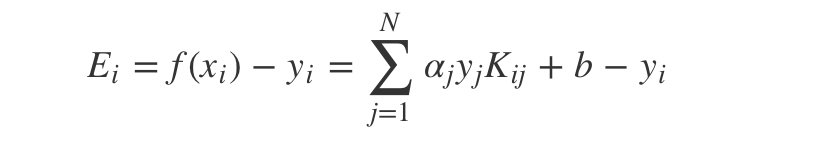
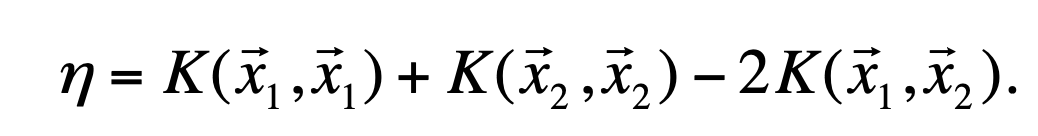
咱们再考虑上约束条件:
此时我们看新的
α
1
\alpha_{1}
α1为: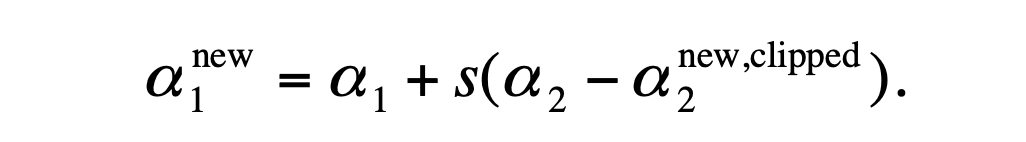
smo的两个变量如何选择
- 第一个变量要选择违反KKT条件的,那么什么是KKT条件:(这里的g就是上面的f)

查看smo论文中,在代码中的语句如下
# 其中self.tol 表示容错率
if ((self.Y[i] * Ei < -self.tol) and (self.alphas[i] < self.C)) or \
((self.Y[i] * Ei > self.tol) and (self.alphas[i] > 0)):
- 在论文中,把 α i \alpha_{i} αi既不等于0又不等于C的的值称为非边界值,如果违反KKT的值有很多,我们先在非边界集合中选取第一个变量。当所有非边界值满足KKT了, 就去遍历整个数据集。
- 第二个变量就在所有的非边界集合中找到一个可以满足 ∣ E i − E j ∣ |E_{i}-E_{j}| ∣Ei−Ej∣最大的,如果不能得到足够的下降,就去整个数据集找,找不到重新找第一个变量。其中足够的下降代码为
if np.abs(a2 - alpha2) < self.eps * (a2 + alpha2 + self.eps):
return 0
smo的b与Ei的更新
- 如果第一个变量与第二个变量都满足非边界值,则b1=b2;如果是0或者c则b取两者的中间值。
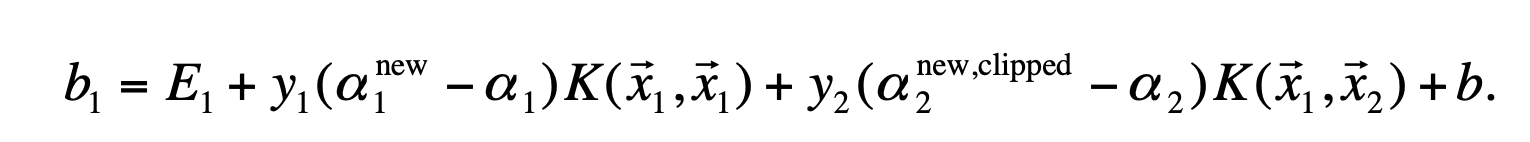
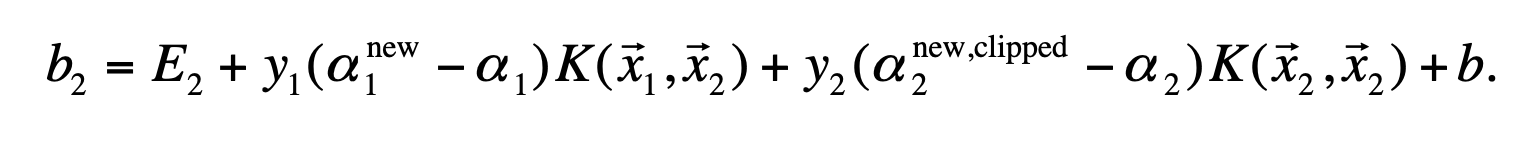
- E的更新公式与上面计算公式相同,不过注意b要用最新的。
smo代码
smo的代码强烈建议看参考中的知乎smo代码,与论文中的伪代码一致度很高。
参考
smo论文:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-98-14.pdf
博客smo代码:https://blog.sudoyc.com/2019/04/12/ml-smo-py/
知乎smo代码:https://zhuanlan.zhihu.com/p/66316880
bilibili教程(推荐):https://www.bilibili.com/video/BV1dJ411B7gh















 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









