






本文根据博客以及课堂老师讲授内容整理而来。
吐槽:
继上周介绍了Minimax和Expectimax后,外教这周又给我们介绍了马尔科夫模型,上周兴高采烈的感觉对Optimal Policy有点理解了但是今天被束大神一问彻底懵逼(一不小心暴露了渣渣特质),下课又研究了一会才发现之前理解的完全错误=。=不求甚解,思考的不够深入又不够专注,老毛病又犯了呢 :(一下午下来还是有不少干货的,决定每次课下来都要记笔记,虽然只有6周23333)
首先:
学习:
学习的本质就是找到特征和标签之间的关系。以便在输入有特征而无标签的未知数据输入时,通过已有的关系得到未知数据的标签。
有监督学习、无监督学习和半监督学习:
有监督学习:输入有标签,从标记好的训练数据中进行训练,常用来做分类和回归。
无监督学习:输入无标签,从未标记的训练数据中进行训练,根据数据的特征直接对数据的结构和数值进行归纳,常用来做聚类。
半监督式学习:从部分标记的和部分没有标记的训练数据进行训练,常用来做回归和分类。
增强学习(Reinforcement Learning)
基本思想:
- 以回报的形式获取反馈
- 所有的学习都是在已经观察到的输出状态的基础上。
- 每一步决策都是为了获得最大的整体的回报。
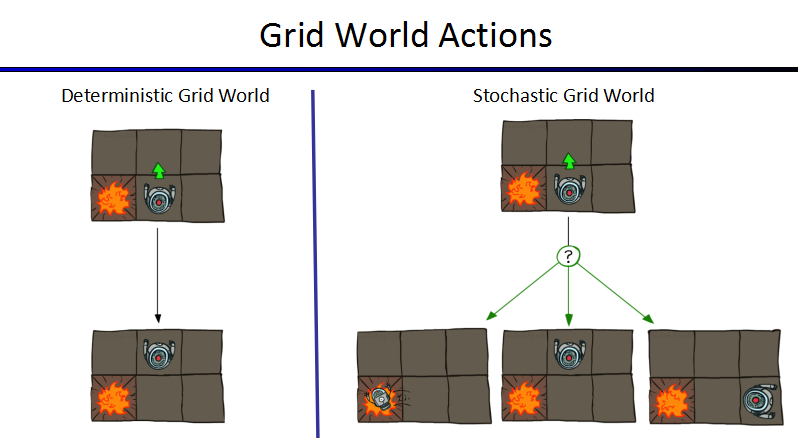
网格问题:
描述:
- 一个智能体在一个格子中,路径中可能会有墙阻隔。
- Noisy movement(?怎么翻译):有些因素会影响智能体,导致其不能采取计算好的动作。
- 80%的概率,智能体会走他的正北方向。
- 10%的概率,智能体会走他的西边。
- 10%的概率,智能体会走他的东方。
- 如果计算出的方向是墙,智能体会依旧在选择这个方向走。
- 每一步都会获得收益。
1.每一小步都会获得收益(可能为负)
2.在最后会收获一个大的收益(好的或坏的) - 目标:最大化收益。
决策确定(Deterministic)与决策随机(Stochastic)情况:
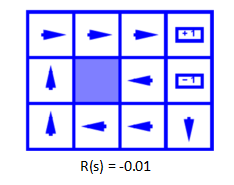
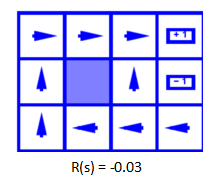
MDP下的最优决策(Optimal Policies):
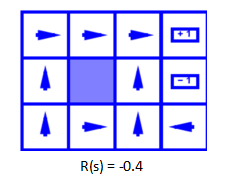
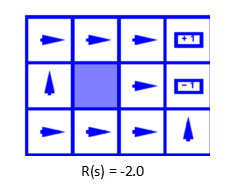
每一步收益为-0.01时,由于智能体有10%的可能会走两边,所以他肯定会选择背对坑的方向,尽量减少走进坑的概率。所以智能体选择朝向西边作为最优决策,不停撞墙,每次撞墙依旧会减少0.01,但是相比1来说-0.01真的是太小了,智能体有这个“资本”不停的在这“浪费生命”,反正这个方向对目前来说就是最优的方案。当轮到那10%的概率向其东边走时,继续选择最优决策,最终走到终点。
每一步的消耗变大为0.03,但是感觉0.03和0.01并没有差很多,不理解为什么这时候会直接选择北方,后来助教解释说是计算出来的,好吧,那就这样理解吧。
消耗加大为0.4,很容易理解他不能这样浪费生命啦,此时对于他来说最优的就是直接向北走,直接走向终点。
消耗加大到2,此时只要是动一下,就比直接死亡花费还要多,为了获得最大的收益,哪怕是负数,智能体直接commit a suicide…….
马尔科夫决策:
一个马尔科夫决策过程(Markov Decision Processes, MDP)是一种Non-Deterministic Search。
定义:
1 定义为:
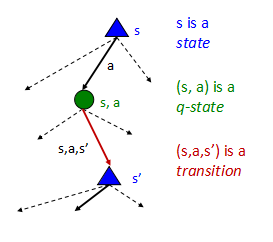
- 状态集合:S
- 动作集合:A
- 转换函数:P(s′|s,a)(或者T(s,a,s′))
从状态s经过动作a会导致状态s′的概率,例如P(s′|s,a) - 回报函数R(s,a,s′),有可能就是R(s)或者R(s′)
- 折扣函数Γ∈(0,1)
- 起始状态s0
- 或许会有一个终止状态
2.目前为止有以下两个属性:
- 策略:每个状态所选择的动作
- 效用:累计折扣回报
U([r0,r1,r2,....])=r0+Γr1+Γ2r2...
3.最优解:
- V∗(s)定义为:在状态s时选择最优的动作的最大折扣回报期望。
- Q∗(s,a)定义为:从状态s开始选择动作a作为第一个动作,并继续选择最优动作的最大累计折扣回报期望。
- π∗(s)定义为:在状态s所选择的最佳动作。
动态过程:
我们有U([r0,r1,r2,....])=r0+Γr1+Γ2r2...
如果回报函数只与状态有关的话,那么回报函数便可以写成r(s0)+Γr(s1))+Γ2r(s2)+...
我们的目标是最大化收益,使全部的回报加权和期望最大
即最大化E[r(s0)+Γr(s1)+Γ2r(s2)+...]
由于Γ<1,所以要more and now的拿到最大回报!
数学表示:
未完待续。。。















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









