






如何避免大模型面对200条规则直接崩溃?
上班第一天,领导让你完成一个任务,要求一小时搞定
但这个任务附带200个业务规则,50个工具和30个demo
你会怎么办?
当然是:

那么问题来了,为什么会有人觉得,人都办不到的要求,把指令一股脑塞给大模型做Agent
它就能毫无偏差的执行、完美交付?

既然AI也办不到,那该怎么办?
推荐一个GitHub 最近很火的开源agent框架Parlant。
相比LangChain / LlamaIndex 等传统框架只能静态一股脑注入所有上下文,Parlant可以通过动态规则注入、自我批判机制以及条件化工具调用,让agent变得可控可解释。
那么,Parlant是如何设计的,我们如何将其结合Milvus用于生产级agent?本文将一一解释。
01
传统框架的不足与Parlant的创新
传统的几百条规则、几十个工具与demo式饱和式上下文注入,往往在小规模测试中表现还不错,但在生产环境中就会立刻暴露三个致命问题:
规则冲突无法解决:当多条规则同时适用时,LLM会随机选择或混合执行,导致行为不可预测。例如,一个电商Agent同时面对"VIP用户优先处理"和"高额订单需要二次确认"两条规则时,执行优先级完全依赖模型的随机性。
边缘情况覆盖不足:你无法预知所有可能的用户输入组合。当遇到训练数据中罕见的场景时,Agent会退化到通用回复模式,丢失业务特异性。
调试与优化成本高昂:当Agent行为出现问题时,你无法确定是哪条规则失效了,只能重新调整整个系统提示,然后再次进行全量测试。
针对以上问题,Parlant引入了动态****规则注入:将规则定义与规则执行分离,通过动态匹配机制确保只有最相关的规则被注入到LLM上下文中。
这个设计理念类似于现代Web框架中的路由系统——你不会在每个请求中加载所有路由处理器,而是根据URL动态匹配对应的处理逻辑。
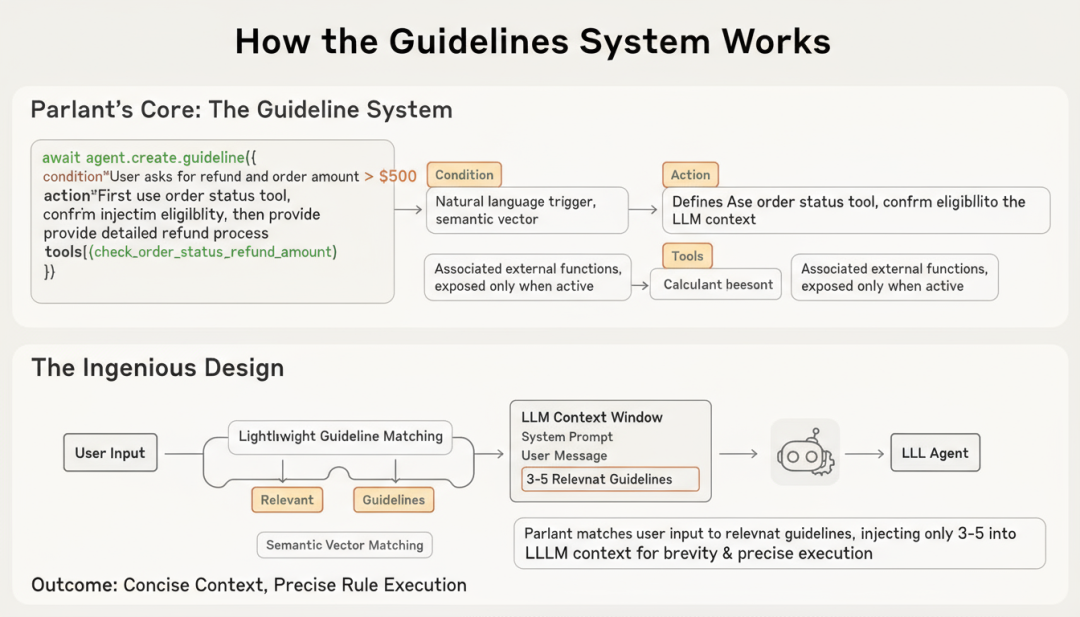
具体来说,Parlant的核心是Guidelines系统,每条指南包含三个要素:
await agent.create_guideline(
condition="用户询问退款且订单金额超过500元",
action="先调用订单状态检查工具,确认是否符合退款条件,然后提供详细的退款流程说明",
tools=[check_order_status, calculate_refund_amount]
)
Condition(条件):用自然语言描述触发场景,Parlant会将其转换为语义向量进行匹配。
Action(行动):明确定义Agent应该如何响应,这部分会在条件匹配时被注入到LLM上下文。
Tools(工具):关联的外部函数,只有在指南激活时才会暴露给Agent。
这个设计的精妙之处在于:Parlant在每次用户输入时,会先进行一次轻量级的指南匹配过程,只将相关的3-5条指南注入到LLM上下文中。这样既保持了上下文的简洁性,又确保了规则的精准执行。
在此基础上,Parlant还引入了自我批判机制作为双重保险,来提升规则遵循的一致性与可控性。其流程分为三步走:
- 生成候选回复:基于匹配的指南和对话上下文生成初步回复
- 合规性检查:将候选回复与激活的指南进行对比,验证是否完全遵循
- 修正或确认:如果发现偏差,触发修正流程;如果符合要求,输出最终回复
此外,传统Agent框架会将所有可用工具暴露给LLM,从而导致两个问题:一是上下文膨胀,二是工具误用。Parlant通过将工具与指南绑定,实现了条件化执行:
# 只有当"用户要转账"这个条件满足时,才会暴露余额查询工具
await agent.create_guideline(
condition="用户想要进行转账操作",
action="首先检查账户余额,如果余额低于500元,提醒可能产生透支费用",
tools=[get_user_account_balance]
)
这种设计确保了工具调用的精准性,避免了Agent在不恰当的时机调用敏感API。
02
动态规则注入的关键:Milvus
当我们深入Parlant的指南匹配机制时,会发现一个核心技术挑战:如何在毫秒级延迟内,从数百甚至数千条指南中找到与当前对话最相关的3-5条?这就是向量数据库发挥作用的场景。
(1)语义匹配的技术实现
Parlant的指南匹配本质上是一个语义检索问题。系统会将每条指南的condition字段转换为向量嵌入(Embedding),当用户输入到达时:
第一步,将用户消息和对话历史编码为查询向量
第二步,在指南向量库中执行相似度搜索
第三步,返回Top-K最相关的指南
第四步,将这些指南注入到LLM上下文中
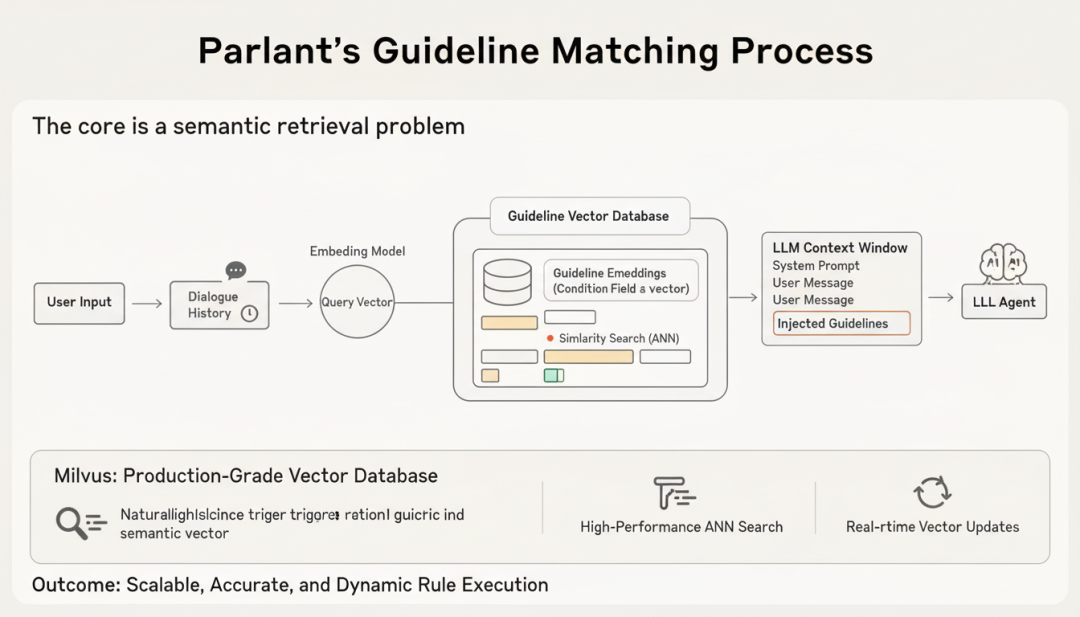
这个过程需要向量数据库具备三个核心能力:高性能的近似最近邻搜索(ANN)、灵活的元数据过滤、以及实时的向量更新。Milvus在这三个维度上都提供了生产级的支持。
(2)Milvus在Agent系统中的实际应用
以一个金融服务Agent为例,假设系统中定义了800条业务指南,覆盖账户查询、转账、理财产品咨询等场景。使用Milvus作为指南存储层的架构如下:
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
import parlant.sdk as p
# 连接Milvus
connections.connect(host="localhost", port="19530")
# 定义指南集合的Schema
fields = [
FieldSchema(name="guideline_id", dtype=DataType.VARCHAR, max_length=100, is_primary=True),
FieldSchema(name="condition_vector", dtype=DataType.FLOAT_VECTOR, dim=768),
FieldSchema(name="condition_text", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="action_text", dtype=DataType.VARCHAR, max_length=2000),
FieldSchema(name="priority", dtype=DataType.INT64),
FieldSchema(name="business_domain", dtype=DataType.VARCHAR, max_length=50)
]
schema = CollectionSchema(fields=fields, description="Agent Guidelines")
guideline_collection = Collection(name="agent_guidelines", schema=schema)
# 创建HNSW索引以实现高性能检索
index_params = {
"index_type": "HNSW",
"metric_type": "COSINE",
"params": {"M": 16, "efConstruction": 200}
}
guideline_collection.create_index(field_name="condition_vector", index_params=index_params)
在实际运行时,当用户输入"我想把10万元转到我妈妈的账户"时,系统会:
- 向量化查询:将用户输入转换为768维向量
- 混合检索:在Milvus中执行向量相似度搜索,同时应用元数据过滤(如business_domain=“transfer”)
- 结果排序:根据相似度分数和priority字段综合排序
- 上下文注入:将Top-3匹配的指南的action_text注入到Parlant Agent的上下文中
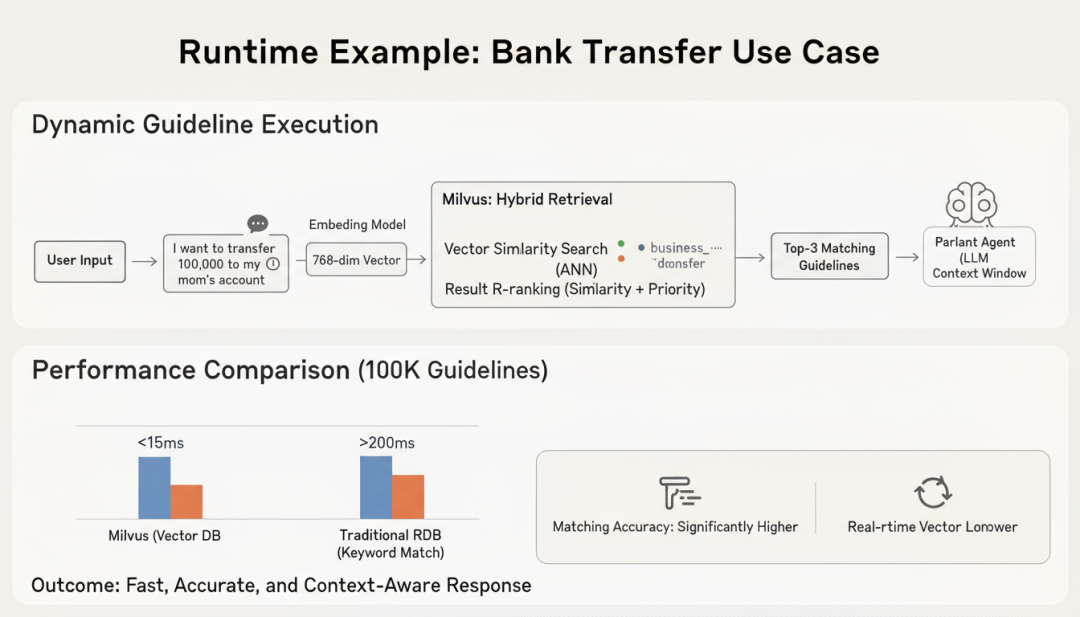
这个过程在Milvus中的P99延迟通常低于15ms,即使指南库规模达到10万条。相比之下,如果使用传统关系型数据库存储指南并通过关键词匹配,延迟会超过200ms,且匹配精度显著下降。
(3)长期记忆与个性化的实现
Milvus的价值不仅限于指南匹配。在需要长期记忆的Agent场景中,Milvus可以存储用户的历史交互向量,实现个性化响应:
# 存储用户交互历史
user_memory_fields = [
FieldSchema(name="interaction_id", dtype=DataType.VARCHAR, max_length=100, is_primary=True),
FieldSchema(name="user_id", dtype=DataType.VARCHAR, max_length=50),
FieldSchema(name="interaction_vector", dtype=DataType.FLOAT_VECTOR, dim=768),
FieldSchema(name="interaction_summary", dtype=DataType.VARCHAR, max_length=500),
FieldSchema(name="timestamp", dtype=DataType.INT64)
]
memory_collection = Collection(name="user_memory", schema=CollectionSchema(user_memory_fields))
用户再次访问时,Agent可以从Milvus中检索相关的历史交互,提供连贯的对话体验。例如,用户上周咨询过理财产品,本周再次访问时,Agent可以主动询问"您对上次了解的那款基金产品还有疑问吗?"
(3)性能优化的关键参数
在生产环境中部署Milvus支持的Agent系统时,需要关注几个关键参数:
索引类型选择:HNSW适合高召回率场景(金融、医疗),IVF_FLAT适合超大规模但对召回率要求相对宽松的场景(电商推荐)。
分片策略:当指南库超过100万条时,建议使用Milvus的分区(Partition)功能按业务域分片,减少检索范围。
缓存配置:对于高频访问的指南(如常见问题处理),可以利用Milvus的查询结果缓存,将延迟降低到5ms以内。
03
Parlant + MilvusLite五分钟demo
本demo主要展示Parlant的核心能力:通过智能准则让LLM普通问题直接回答,专业问题自动触发知识库检索并提供结构化的可追溯回答。
环境准备:
1.Parlant GitHub: https://github.com/emcie-co/parlant
2.Parlant文档: https://parlant.io/docs
3.python3.10+
4.OpenAI_key
5.MlivusLite
1.依赖安装
# 安装必要的Python包
pip install pymilvus parlant openai
# 或者如果使用conda环境
conda activate your_env_name
pip install pymilvus parlant openai
2.环境变量配置
# 设置OpenAI API密钥
export OPENAI_API_KEY="your_openai_api_key_here"
# 验证环境变量是否设置成功
echo $OPENAI_API_KEY
3.核心代码实现
3.1 自定义嵌入器 (OpenAIEmbedder)
class OpenAIEmbedder(p.Embedder):
# 实现文本向量化,支持超时和重试机制
# 维度: 1536 (text-embedding-3-small)
# 超时设置: 60秒,最大重试2次
3.2知识库初始化
- 创建Milvus集合 kb_articles
- 插入示例数据(退款政策、换货政策、物流时间)
- 建立HNSW索引以加速检索
3.3向量检索工具
@p.tool
async def vector_search(query: str, top_k: int = 5, min_score: float = 0.35):
# 1. 将用户查询转换为向量
# 2. 在Milvus中执行相似度搜索
# 3. 返回相关度超过阈值的结果
3.4Parlant Agent配置
- 准则1 : 对于事实性/政策性问题,必须先执行向量检索
- 准则2 : 有证据时使用结构化模板回复(摘要+要点+来源)
# 核心准则 1:当用户问事实类/政策类问题,必须先做向量检索
await agent.create_guideline(
condition="User asks a factual question about policy, refund, exchange, or shipping",
action=(
"Call vector_search with the user's query. "
"If evidence is found, synthesize an answer by quoting key sentences and cite doc_id/title. "
"If evidence is insufficient, ask a clarifying question before answering."
),
tools=[vector_search],
)
# 核心准则 2:当有证据时使用模板化回复,统一口径与风格
await agent.create_guideline(
condition="Evidence is available",
action=(
"Answer with the following template:\\n"
"Summary: provide a concise conclusion.\\n"
"Key points: 2-3 bullets distilled from evidence.\\n"
"Sources: list doc_id and title.\\n"
"Note: if confidence is low, state limitations and ask for clarification."
),
tools=[],
)
3.5完整代码
import os
import asyncio
import json
from typing import List, Dict, Any
import parlant.sdk as p
from pymilvus import MilvusClient, DataType
# 1) 环境变量:使用 OpenAI(默认生成模型 + 作为嵌入服务)
# 请确保已设置 OPENAI_API_KEY
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
if not OPENAI_API_KEY:
raise RuntimeError("Please set OPENAI_API_KEY environment variable")
# 2) 初始化 Milvus Lite(本地内嵌,无需独立服务)
# MilvusClient 使用本地文件路径启用 Lite 模式(需 pymilvus>=2.x)
client = MilvusClient("./milvus_demo.db") # Lite 模式使用本地文件路径
COLLECTION = "kb_articles"
# 3) 示例数据:三段政策或 FAQ(实际可从文件加载并分块)
DOCS = [
{"doc_id": "POLICY-001", "title": "Refund Policy", "chunk": "Refunds are available within 30 days of purchase if the product is unused."},
{"doc_id": "POLICY-002", "title": "Exchange Policy", "chunk": "Exchanges are permitted within 15 days; original packaging required."},
{"doc_id": "FAQ-101", "title": "Shipping Time", "chunk": "Standard shipping usually takes 3–5 business days within the country."},
]
# 4) 使用 OpenAI 生成嵌入(你也可以替换为别的嵌入服务)
# 这里我们通过 Parlant 的内置 OpenAI embedder(更简单),也可直接用 openai SDK。
class OpenAIEmbedder(p.Embedder):
async def embed(self, texts: List[str], hints: Dict[str, Any] = {}) -> p.EmbeddingResult:
# 使用 OpenAI API 进行文本嵌入,优化超时和重试设置
import openai
try:
client = openai.AsyncOpenAI(
api_key=OPENAI_API_KEY,
timeout=60.0, # 增加到60秒超时
max_retries=2 # 设置重试次数
)
print(f"正在生成 {len(texts)} 个文本的嵌入向量...")
response = await client.embeddings.create(
model="text-embedding-3-small",
input=texts
)
vectors = [data.embedding for data in response.data]
print(f"成功生成 {len(vectors)} 个嵌入向量")
return p.EmbeddingResult(vectors=vectors)
except Exception as e:
print(f"OpenAI API调用失败: {e}")
# 返回模拟向量用于测试Milvus连接
print("使用模拟向量进行测试...")
import random
vectors = [[random.random() for _ in range(1536)] for _ in texts]
return p.EmbeddingResult(vectors=vectors)
@property
def id(self) -> str:
return "text-embedding-3-small"
@property
def max_tokens(self) -> int:
return 8192
@property
def tokenizer(self) -> p.EstimatingTokenizer:
from parlant.core.nlp.tokenization import ZeroEstimatingTokenizer
return ZeroEstimatingTokenizer()
@property
def dimensions(self) -> int:
return 1536
embedder = OpenAIEmbedder()
async def ensure_collection_and_load():
# 创建集合(schema:主键、向量、附加字段)
if not client.has_collection(COLLECTION):
client.create_collection(
collection_name=COLLECTION,
dimension=len((await embedder.embed(["dimension_probe"])).vectors[0]),
# 使用默认度量(COSINE);如需变更可指定 metric_type="COSINE"
auto_id=True,
)
# 创建索引以加速检索(HNSW 作为示例)
client.create_index(
collection_name=COLLECTION,
field_name="vector",
index_type="HNSW",
metric_type="COSINE",
params={"M": 32, "efConstruction": 200}
)
# 插入数据(若已存在可跳过;这里简单处理为幂等)
# 生成嵌入
chunks = [d["chunk"] for d in DOCS]
embedding_result = await embedder.embed(chunks)
vectors = embedding_result.vectors
# 检查是否已存在相同 doc_id;演示用,实际应做更严格的去重
# 这里直接插入。生产环境请使用 upsert 逻辑或显式主键
client.insert(
COLLECTION,
data=[
{"vector": vectors[i], "doc_id": DOCS[i]["doc_id"], "title": DOCS[i]["title"], "chunk": DOCS[i]["chunk"]}
for i in range(len(DOCS))
],
)
# 加载到内存
client.load_collection(COLLECTION)
# 5) 定义向量检索工具(Parlant 的 Tool)
@p.tool
async def vector_search(context: p.ToolContext, query: str, top_k: int = 5, min_score: float = 0.35) -> p.ToolResult:
# 5.1 生成查询向量
embed_res = await embedder.embed([query])
qvec = embed_res.vectors[0]
# 5.2 Milvus 检索
results = client.search(
collection_name=COLLECTION,
data=[qvec],
limit=top_k,
output_fields=["doc_id", "title", "chunk"],
search_params={"metric_type": "COSINE", "params": {"ef": 128}},
)
# 5.3 组装结构化证据并做分数阈值筛选
hits = []
for hit in results[0]:
score = hit["distance"] if "distance" in hit else hit.get("score", 0.0)
if score >= min_score:
hits.append({
"doc_id": hit["entity"]["doc_id"],
"title": hit["entity"]["title"],
"chunk": hit["entity"]["chunk"],
"score": float(score),
})
return p.ToolResult({"evidence": hits})
# 6) 运行 Parlant Server,并创建 Agent + 行为准则
async def main():
await ensure_collection_and_load()
async with p.Server() as server:
agent = await server.create_agent(
name="Policy Assistant",
description="Rule-controlled RAG assistant with Milvus Lite",
)
# 示例变量:当前时间(可用于模板或日志)
@p.tool
async def get_datetime(context: p.ToolContext) -> p.ToolResult:
from datetime import datetime
return p.ToolResult({"now": datetime.now().isoformat()})
await agent.create_variable(name="current-datetime", tool=get_datetime)
# 核心准则 1:当用户问事实类/政策类问题,必须先做向量检索
await agent.create_guideline(
condition="User asks a factual question about policy, refund, exchange, or shipping",
action=(
"Call vector_search with the user's query. "
"If evidence is found, synthesize an answer by quoting key sentences and cite doc_id/title. "
"If evidence is insufficient, ask a clarifying question before answering."
),
tools=[vector_search],
)
# 核心准则 2:当有证据时使用模板化回复,统一口径与风格
await agent.create_guideline(
condition="Evidence is available",
action=(
"Answer with the following template:\\n"
"Summary: provide a concise conclusion.\\n"
"Key points: 2-3 bullets distilled from evidence.\\n"
"Sources: list doc_id and title.\\n"
"Note: if confidence is low, state limitations and ask for clarification."
),
tools=[],
)
# 提示:本地 Playground 在下述地址
print("Playground: <http://localhost:8800>")
if __name__ == "__main__":
asyncio.run(main())
4.运行代码
# 运行主程序
python main.py
4.1访问前端
<http://localhost:8800>
5.访问测试
5.1测试一
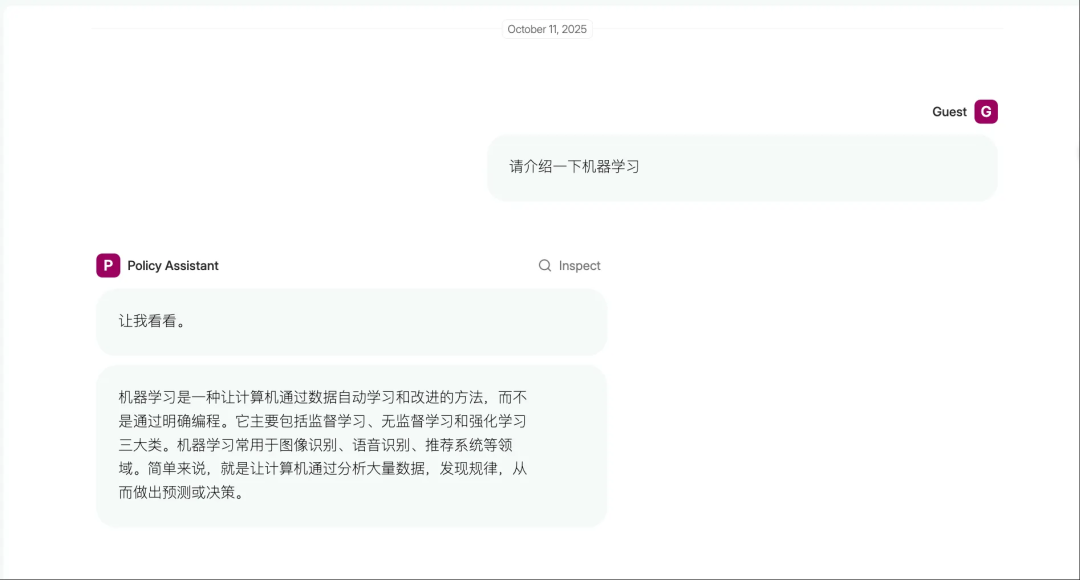
##一般性问题(直接LLM回答)
请介绍一下机器学习?
5.2测试二
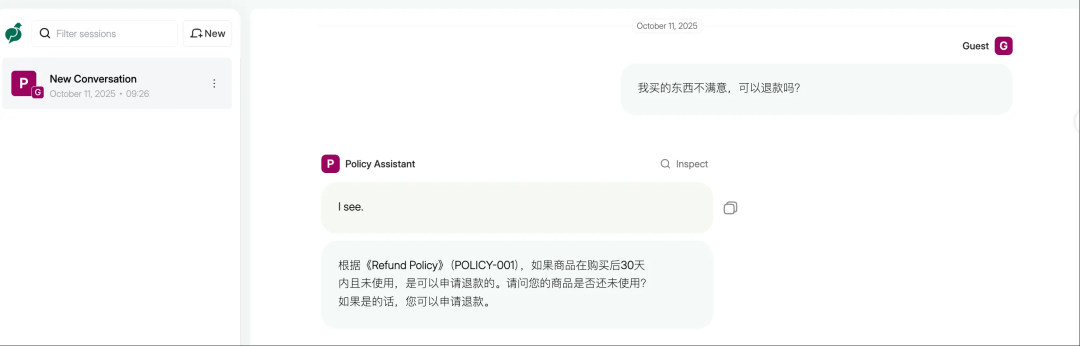
#触发向量检索+规则
我买的东西不满意,可以退款吗?

我的包裹什么时候能收到?
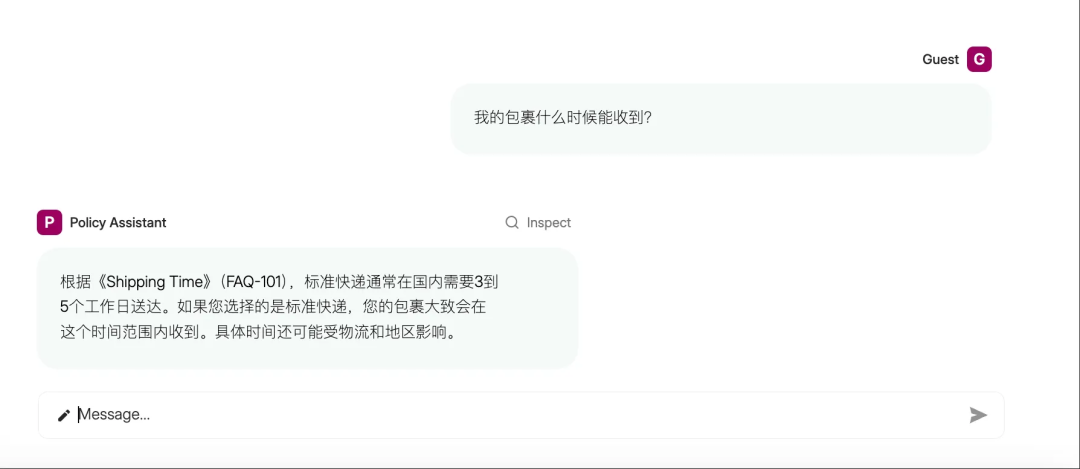
测试结果完全符合预期。对于一般性问题(如机器学习介绍),系统直接使用LLM给出回答;而对于专业问题(如退款和物流咨询),系统自动触发向量检索并按照结构化模板提供可追溯的答案,验证了Parlant的动态准则机制和Milvus的语义检索能力。
04
写在结尾
很多开发者会问:Parlant与现有的Agent框架(如LangChain、LlamaIndex)有什么区别?
LangChain/LlamaIndex:通用型框架,提供丰富的组件和集成,适合快速原型开发和研究探索。但在生产环境中,需要开发者自行实现规则管理、可靠性保障等机制。
Parlant:专注于生产级Agent的控制与合规,开箱即用的指南系统、自我批判机制和可解释性工具。适合需要高可靠性的面向客户场景(金融、医疗、法律)。
两者可以互补使用:用LangChain构建复杂的数据处理Pipeline,用Parlant封装最终面向用户的交互层。而Milvus这样的向量数据库,正是这个pipeline中不可或缺的基础设施。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 150
150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









