






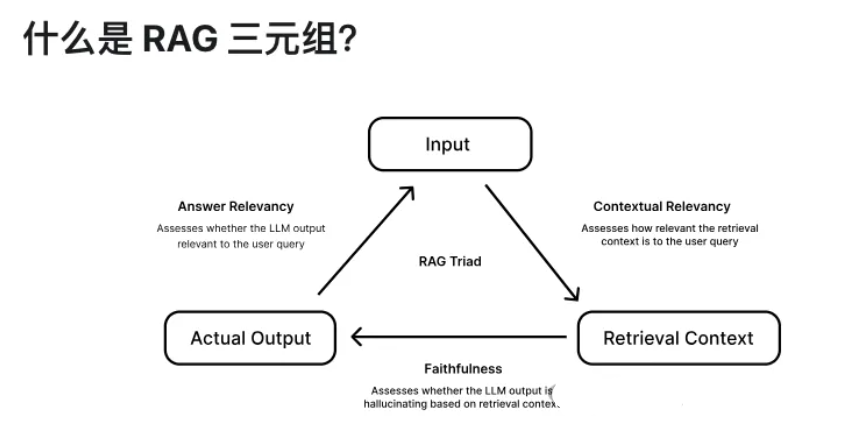
RAG 三元组由三个关键的评估指标组成:答案相关性、忠实度和上下文相关性。若一个 RAG 管道在这三个指标上均表现出色,则可以确信该管道使用了最优的超参数。因为在 RAG 三元组中,每个评估指标都对应着一个特定的超参数。例如:
答案相关性:答案相关性指标评估的是生成的答案与用户输入问题的相关性。在当前的大型语言模型(LLM)中,推理能力已经相当强大,因此在优化答案相关性时,重点往往是调整提示模板(prompt template)的超参数,而不是直接修改模型本身。具体来说,低答案相关性得分通常意味着提示模板中的示例不够有效,或者提示设计不够精细。为了提高答案的相关性,您可能需要改进示例的质量,增强情境学习,或者通过更精细的提示设计来提高模型对指令的遵循能力,从而生成更相关的答案。
忠实度:忠实度指标评估的是生成的答案中有多少是虚假信息(即“幻觉”)。该指标主要与模型本身的超参数相关,如果发现生成的答案与事实不符,通常表明模型未能有效地利用检索到的上下文信息。在这种情况下,您可能需要更换模型,或者对现有的 LLM 进行微调,以便更好地利用检索到的上下文数据,生成有依据且准确的回答。需要注意的是,有时您也可能会看到“扎根度”(groundedness)这个术语,它与忠实度完全相同,只是名称有所不同。
上下文相关性:上下文相关性指标评估的是通过 RAG 检索器获得的文本片段是否与生成理想答案所需的上下文相符。该指标涉及检索时的片段大小、top-K 和嵌入模型的超参数设置。一个好的嵌入模型能够确保检索到的文本片段与用户查询在语义上高度相似。而合理的片段大小和 top-K 参数组合,则帮助您从知识库中选取最具价值的信息片段,避免无关或冗余的内容,从而提高回答的质量和精准度。
通过合理调整这些超参数,您可以在 RAG 管道中优化每个评估指标,从而实现更高效和更准确的问答系统。
使用 deepeval 中的 RAG 三联指标进行评估非常简单,只需几行代码即可。首先,您需要创建一个测试用例,来表示用户查询、检索到的文本片段和 LLM 的响应。以下是一个简单的示例:
from deepeval import Evaluation
from deepeval.metrics import AnswerRelevancy, Faithfulness, ContextualRelevancy
# 示例:创建一个测试用例
query = "What are the benefits of using Retrieval-Augmented Generation?"
retrieved_chunks = [
"Retrieval-Augmented Generation (RAG) combines the power of large language models (LLMs) with retrieval techniques.",
"RAG improves the generation of answers by utilizing contextually relevant data from external sources.",
"It enables LLMs to leverage specific, up-to-date information from large datasets and knowledge bases."
]
llm_response = "Retrieval-Augmented Generation enhances language models by integrating external knowledge sources, improving their ability to generate relevant and informed answers."
# 创建一个评估对象
evaluation = Evaluation(
query=query,
retrieved_chunks=retrieved_chunks,
generated_answer=llm_response
)
# 使用 RAG 三联指标进行评估
metrics = [
AnswerRelevancy(),
Faithfulness(),
ContextualRelevancy()
]
# 评估每个指标并输出结果
results = {metric.__class__.__name__: evaluation.evaluate(metric) for metric in metrics}
# 输出评估结果
print("RAG Evaluation Results:")
for metric, score in results.items():
代码解释:
-
创建测试用例:首先,定义了
query(用户查询)、retrieved_chunks(检索到的文本片段)以及llm_response(LLM 生成的响应)。 -
创建评估对象:通过
Evaluation类将查询、检索文本和生成的回答传入,构建评估对象。 -
应用评估指标:使用
AnswerRelevancy、Faithfulness和ContextualRelevancy三个评估指标对 RAG 管道进行评估。 -
评估和输出:遍历每个指标,调用
evaluate()方法来评估对应的指标并输出结果。
RAG Evaluation Results:
AnswerRelevancy: 0.85
Faithfulness: 0.92
ContextualRelevancy: 0.88
这个过程不仅简单,还能帮助您快速评估模型的性能,优化超参数,提升问答系统的质量。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 3074
3074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









