






1、TAU-Bench: 测试真实环境中AI智能体的可靠性
TAU-bench 是一个评估AI智能体在真实世界环境中可靠性的基准测试。它评估智能体是否能够在动态的多轮对话中与用户进行交互,理解需求并完成任务。

T-bench测试流程包括:
- 智能体与模拟用户交互,通过多轮对话了解需求并收集信息
- 智能体使用特定领域的API工具(如预订航班、退货等)
- 智能体必须遵守提供的特定领域规则和限制
- 通过比较最终数据库状态来衡量成功与否
- 使用pass^k指标评估在多次(k)尝试中完成相同任务的可靠性
关键发现:
- 发布时的智能体成功率不到50%
- 包含零售和航空领域的10-15个工具和50-115个不同任务
- 智能体表现不稳定,会在之前成功过的任务上失败,pass^8得分低于25%
- 需要4次以上数据库写入的任务成功率仅约20%,而单操作任务成功率约75%
- 失败原因包括对数据库状态推理不足、误解或忽略规则、或处理复杂多步骤请求不当
- 移除领域指南会使复杂领域的性能下降22%
- 函数调用优于基于文本的ReAct和仅Act方法
- 评估是自动化的,并与最终数据库状态进行比较
虽然该基准测试于2024年6月发布,但现在感觉比以往任何时候都更重要。它不仅描述了我们目前面临的限制,还展示了如何为自己的智能体设置良好的评估流程!
论文标题:τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
论文链接:https://arxiv.org/abs/2406.12045
2、 Thinking Intervention:通过干预思考过程控制推理模型
该研究提出了一种名为"思考干预"的新范式,旨在通过战略性地插入或修改特定思考标记,明确引导LLM的内部推理过程。
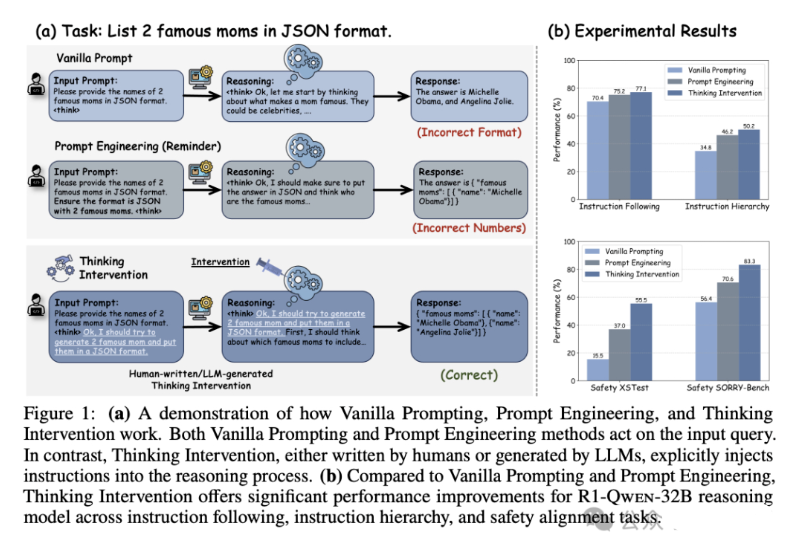
研究人员在多项任务上进行了全面评估,包括IFEval上的指令遵循、SEP上的指令层次结构,以及XSTest和SORRY-Bench上的安全对齐。结果表明,与基线提示方法相比,思考干预显著提高了性能:
(1)在指令遵循场景中准确率提高了6.7%
(2)在指令层次结构推理中提高了15.4%
(3)使用开源DeepSeek R1模型拒绝不安全提示的比率提高了40.0%
这项工作开辟了控制推理LLM的新研究方向,具有广阔的应用前景。
论文标题:Effectively Controlling Reasoning Models through Thinking Intervention
论文链接:https://arxiv.org/abs/2503.24370
3、 测试时扩展在复杂任务中的应用:现状与未来展望
该研究调查了扩展方法在九个最先进的模型和八个具有挑战性的任务中的优势和局限性,包括数学和STEM推理、日历规划、NP难问题、导航和空间推理。
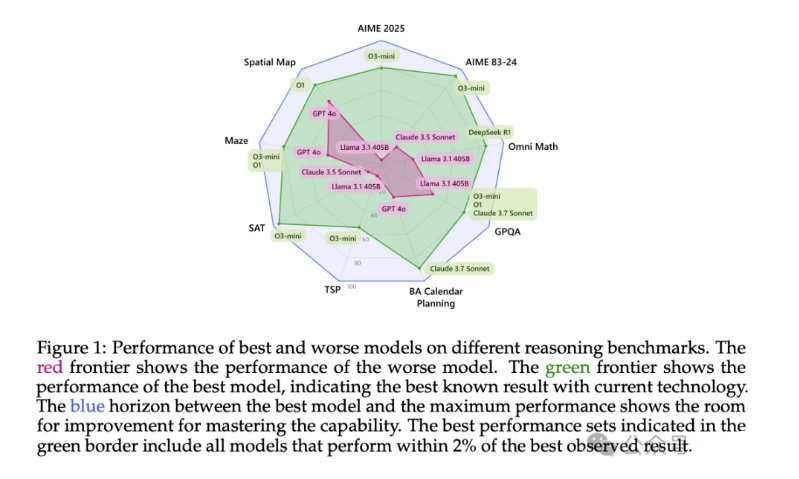
研究比较了传统模型(如GPT-4o)与针对测试时扩展微调的模型(如o1),通过评估协议进行,涉及独立或顺序带反馈的重复模型调用。
实证分析揭示了测试时扩展的优势在不同任务间存在差异,并随着问题复杂性增加而减弱。此外,简单地使用更多token并不一定转化为这些具有挑战性领域中的更高准确性。
令人鼓舞的是,当使用完美验证器或强反馈进一步扩展推理时,所有模型都表现出显著的性能提升,表明未来仍有很大的改进空间。
论文标题:Inference-Time Scaling for Complex Tasks: Where We Stand and What Lies Ahead
论文链接:https://arxiv.org/abs/2504.00294
4、 推理经济:LLM高效推理的综述
该调查提供了LLM在后训练和测试时推理阶段的推理经济全面分析,包括:
(1)推理低效的原因
(2)不同推理模式的行为分析
(3)实现推理经济的潜在解决方案
随着LLM从快速直觉思维(系统1)过渡到慢速深度推理(系统2),虽然系统2推理提高了任务准确性,但由于其缓慢思考性质和低效或不必要的推理行为,往往会产生大量计算成本。相比之下,系统1推理计算效率高但性能次优。
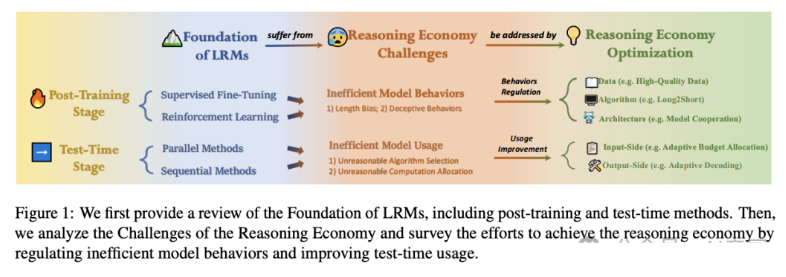
在性能(收益)和计算成本(预算)之间找到平衡至关重要,这就催生了推理经济的概念。调查通过提供可行的见解和强调开放性挑战,旨在阐明改善LLM推理经济的策略,从而成为推动这一不断发展领域研究的宝贵资源。
论文标题:Harnessing the Reasoning Economy: A Survey of Efficient Reasoning for Large Language Models
论文链接:https://arxiv.org/abs/2503.24377
5、 Open-Qwen2VL:学术资源上的完全开源多模态LLM预训练
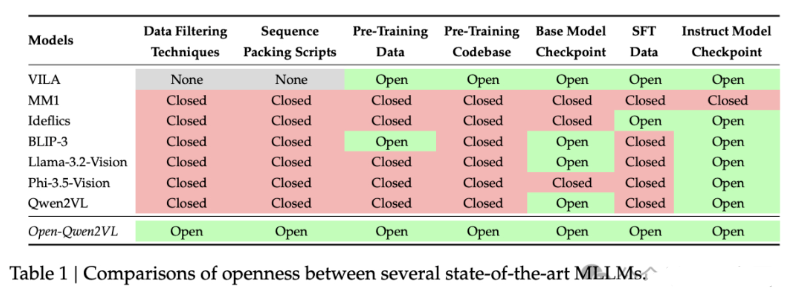
研究者介绍了Open-Qwen2VL,一个完全开源的2B参数多模态大语言模型,它在仅使用442个A100-40G GPU小时的情况下,在29M图像-文本对上高效预训练。
该方法采用从低到高的动态图像分辨率和多模态序列打包,显著提高了预训练效率。训练数据集经过精心筛选,使用基于MLLM的过滤技术(如MLM-Filter)和传统的基于CLIP的过滤方法,大大提高了数据质量和训练效率。
Open-Qwen2VL预训练在UCSB的学术级8xA100-40G GPU上进行,使用5B打包的多模态tokens,仅为Qwen2-VL 1.4T多模态预训练tokens的0.36%。
最终的指令调优Open-Qwen2VL在MMBench、SEEDBench、MMstar和MathVista等各种多模态基准测试中的表现优于部分开源的最先进MLLM Qwen2-VL-2B,表明Open-Qwen2VL具有显著的训练效率。
研究者开源了工作的所有方面,包括计算高效和数据高效的训练细节、数据过滤方法、序列打包脚本、WebDataset格式的预训练数据、基于FSDP的训练代码库,以及基础和指令调优的模型检查点。
论文标题:Open-Qwen2VL: Compute-Efficient Pre-Training of Fully-Open Multimodal LLMs on Academic Resources
论文链接:https://arxiv.org/abs/2504.00595
6、 Z1模型:当AI高效思考的秘密被揭开,推理速度提升70%!
该论文提出了一种高效的测试时扩展方法,通过在代码相关推理轨迹上训练LLM,帮助减少多余的思考token,同时保持性能。
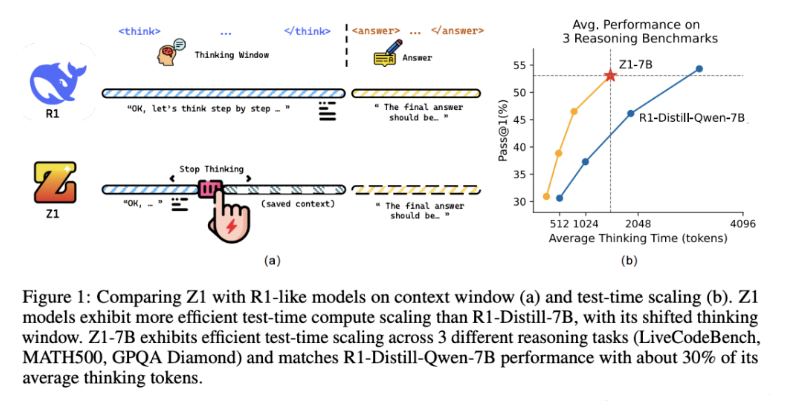
首先,研究者创建了Z1-Code-Reasoning-107K,一个精心策划的简单和复杂编码问题及其短期和长期解决方案轨迹的数据集。其次,提出了一个新颖的移位思考窗口,通过移除上下文分隔标签(例如,…)和限制推理token来减轻过度思考开销。
经过长短轨迹数据训练并配备移位思考窗口的Z1-7B模型,展示了根据问题复杂性调整推理水平的能力,并在不同推理任务中表现出高效的测试时扩展,使用约30%的平均思考token就能达到R1-Distill-Qwen-7B的性能。
值得注意的是,仅使用代码轨迹微调的Z1-7B展示了对更广泛推理任务的泛化能力(GPQA Diamond上达到47.5%)。该研究对高效推理诱导的分析也为未来研究提供了宝贵见解。
论文标题:Z1: Efficient Test-time Scaling with Code
论文链接:https://arxiv.org/abs/2504.00810
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









