









前面我们分篇讲述了transformer的原理,但是对于很多刚接触transformer的人来说可能会有一点懵,所以我们接下来会分三篇文章用白话的形式在将transformer 讲一遍。
前文链接
Bert基础(一)–自注意力机制
注意力机制其实最大的作用就是对词嵌入也就是embedding的优化,下面我们来看下是怎么做到的
白话transformer(一)
1、 词嵌入
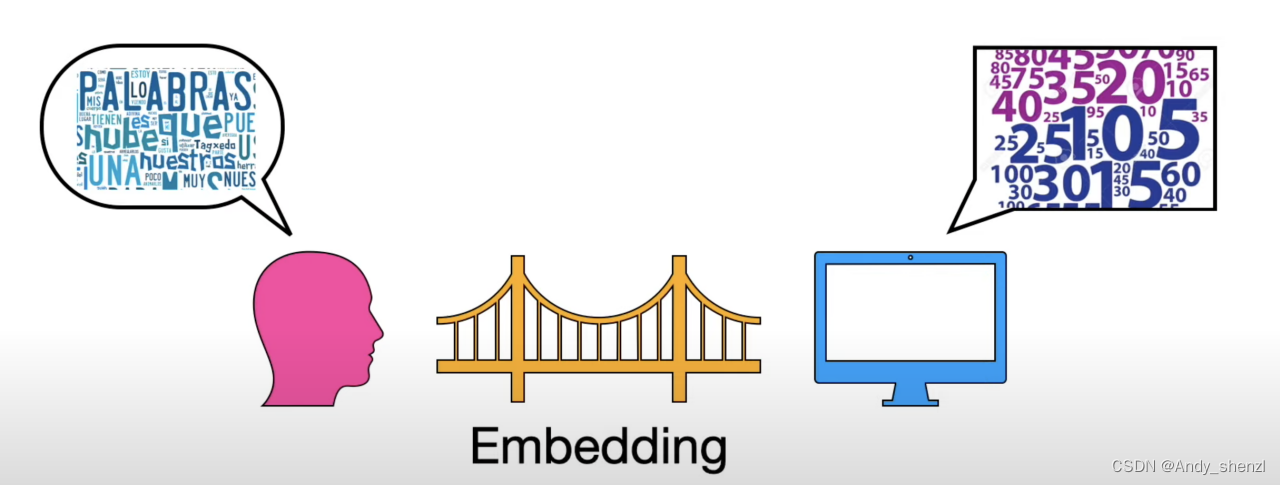
我们人类最擅长的就是自然语言的表达,而计算机擅长的事数字的计算,如何将人类的表达方式让计算机能够理解呢,就需要一个桥梁连接起来。
这个桥梁就是embedding,embedding 即词嵌入,是NLP领域最重要部分;embedding就是将文本变成数字,让每个或者每段文本都有很好的与之对应的数字表示,那么需要解决的问题就会变得容易很多,embeddings 越好模型就会越好
2、 例子
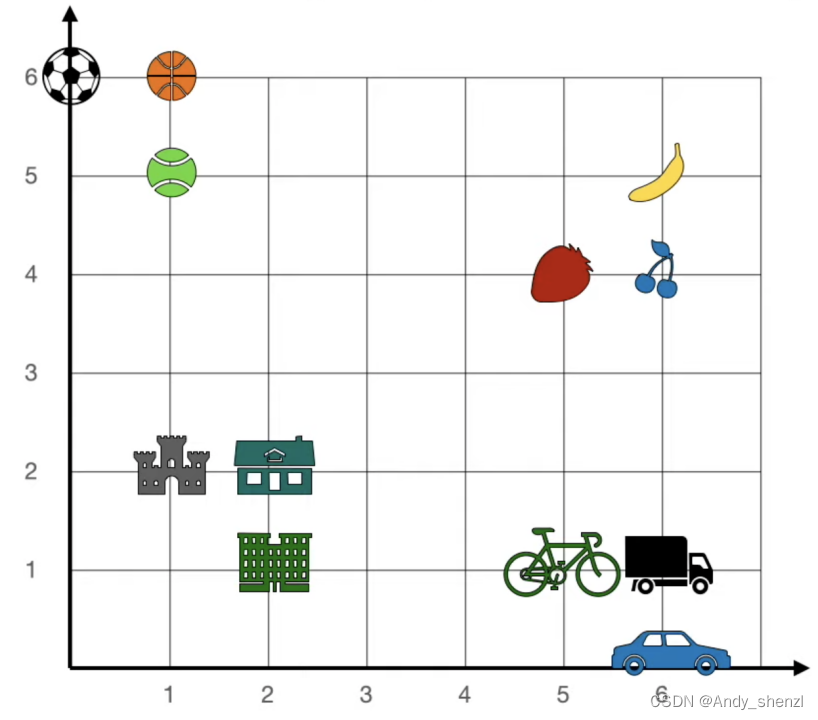
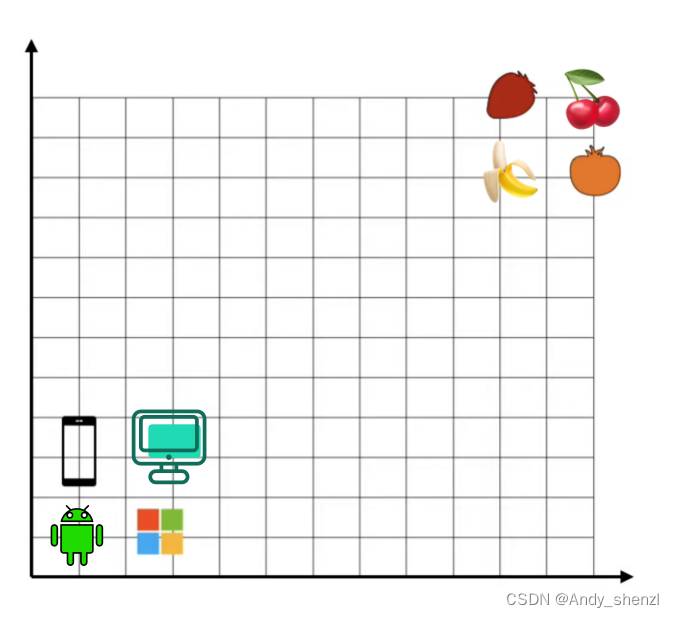
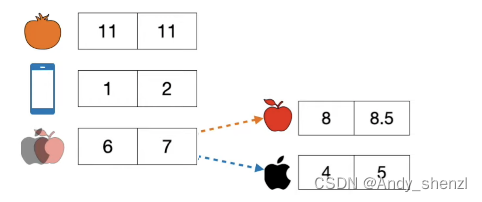
我们这里有一堆文本单词,在一个二维的坐标系中,每个单词都有一个水平和垂直的坐标,比如香蕉是6,5,
那么现在出现了一个新的单词,apple(🍎),如果让我们给苹果安排一个位置,应该在哪里最合适呢?
很明显是右上角,因为这里全部是水果,embedding的作用就是相似的单词会被赋予相似的数字
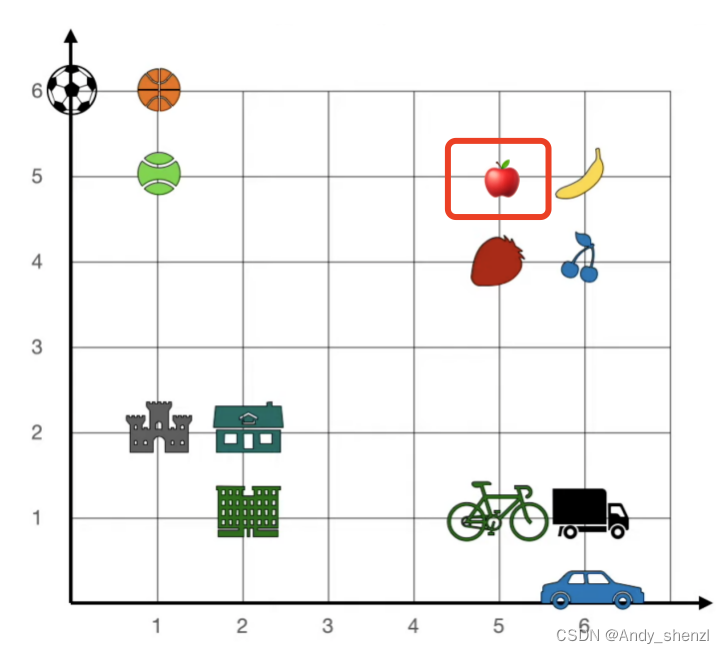
当然,对于一个单词其实不会只有两个维度,可以使很多,分别来表示其中一个属性,比如大小、颜色、形状等,如下
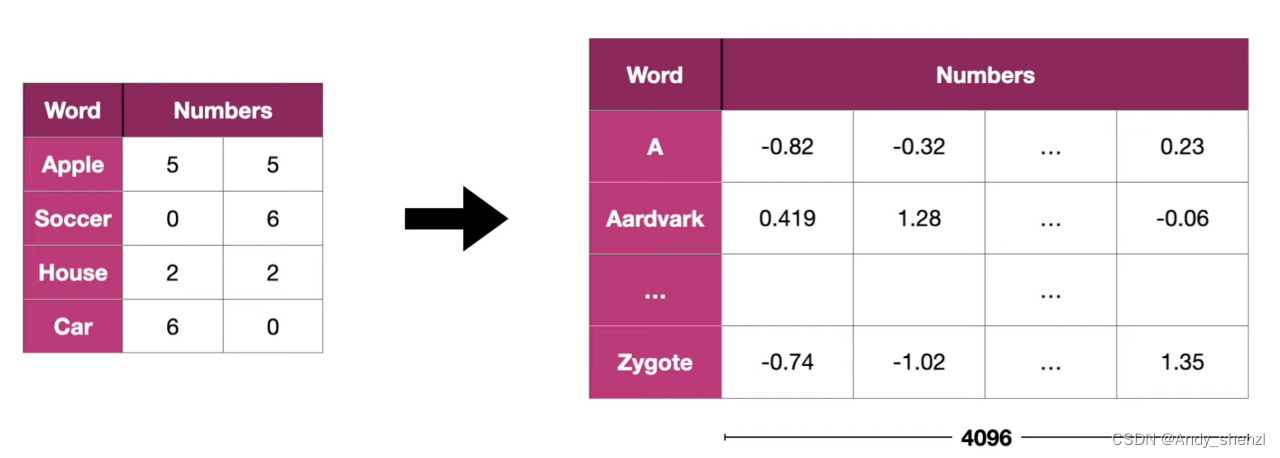
3、 问题
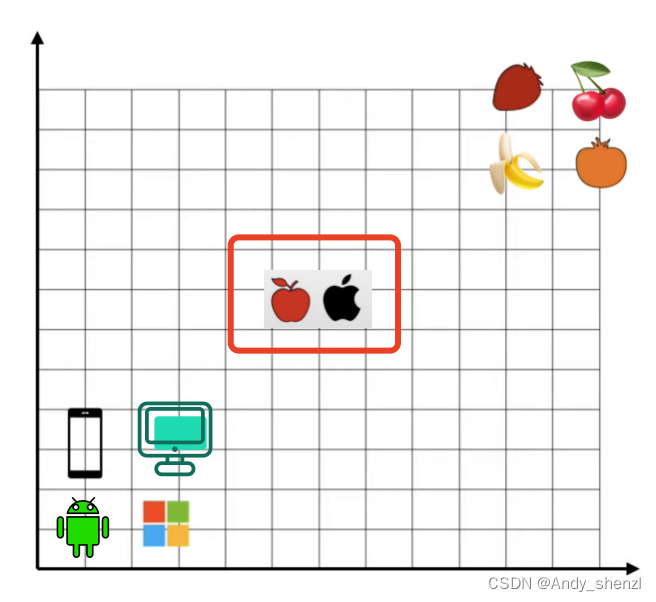
现在我们重新定义一个坐标系

右上角是草莓和橘子,左下角是苹果和window系统;根据我们的正常理解,右上角是水果类,左下角是计算机类;
OK,下面我们又有几个新的单词出现了,需要我们预测他们的坐标。

我们其实很容易的可以区分,车厘子和香蕉是水果,应该在右上角;安卓和电脑应该属于计算机那个类别,放在右下角。
到现在为止,事情看上去还是很简单的,但是现在来了一个单词苹果(apple)
这个单词应该放在哪里呢???
苹果如果表示吃的水果应该在右上角,如果是手机的话应该在左下角。而对于embedding而言,不管是自己创建Vocabulary单词表还是使用word2vec,都不能解决歧义。
我们先把单词苹果(apple)放在中间的位置,那么我们该如何解决这个问题的,下面注意力就要出场了。
4、 注意力机制
注意力机制就是来解决单词歧义问题的

论文中提到的注意力就是使用了查询、键、值三个矩阵,我们在介绍中不是为了解释论文架构,而是说清楚注意力到底是怎么实现的。

现在我们来看两个文本,根据第一句话我们应该明白,这里面提到了橘子,我们人类是知道橙子属于水果,提到苹果这个词语时,那么苹果应该是可以吃的苹果;同样在第二个句子中提到了手机,那么我们应该明白这里指的是苹果手机。

我们人类可以根据经验进行判断,但是计算机是不知道的
下面我们来看看注意力机制是如何做到的?
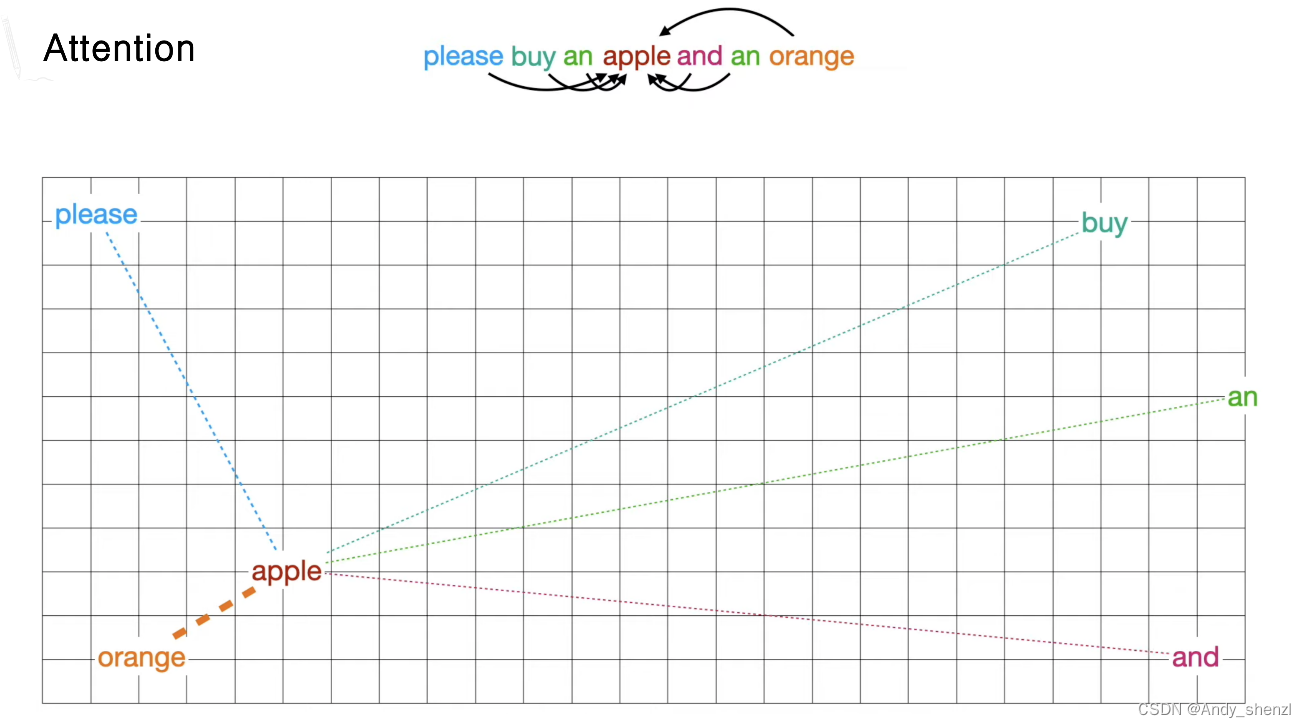
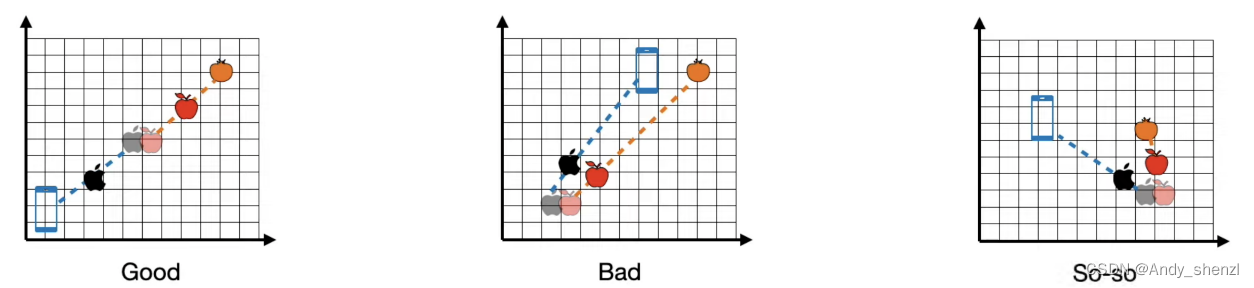
在前面我们提到了,我们先把苹果这个单词初始化,放在中间的位置;当输入是第一句话时,提到了orange,那么这个地方出现的apple应该向右上角移动。
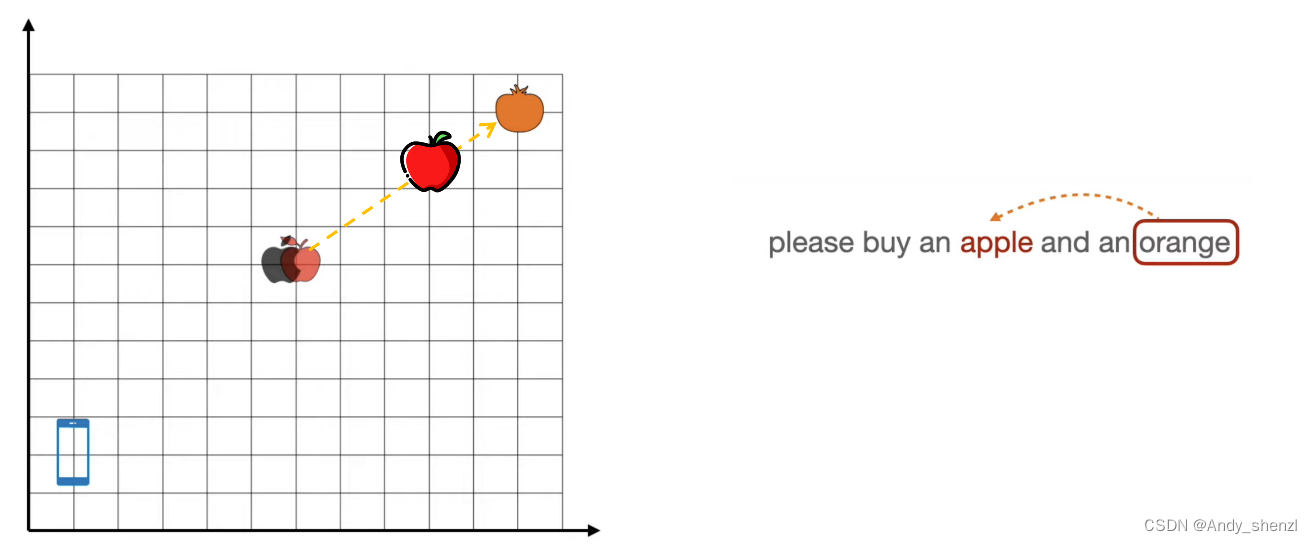
而,第二句话出现时,apple这个单词应该向左下角移动
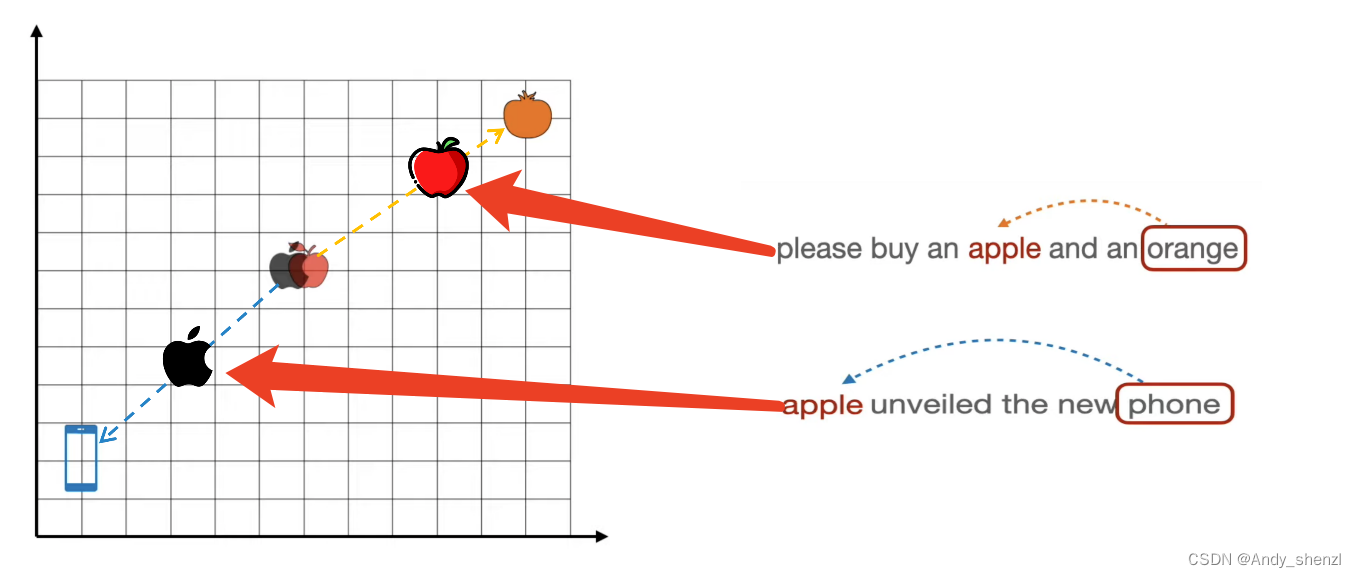
其相应的坐标如下
5、 原理
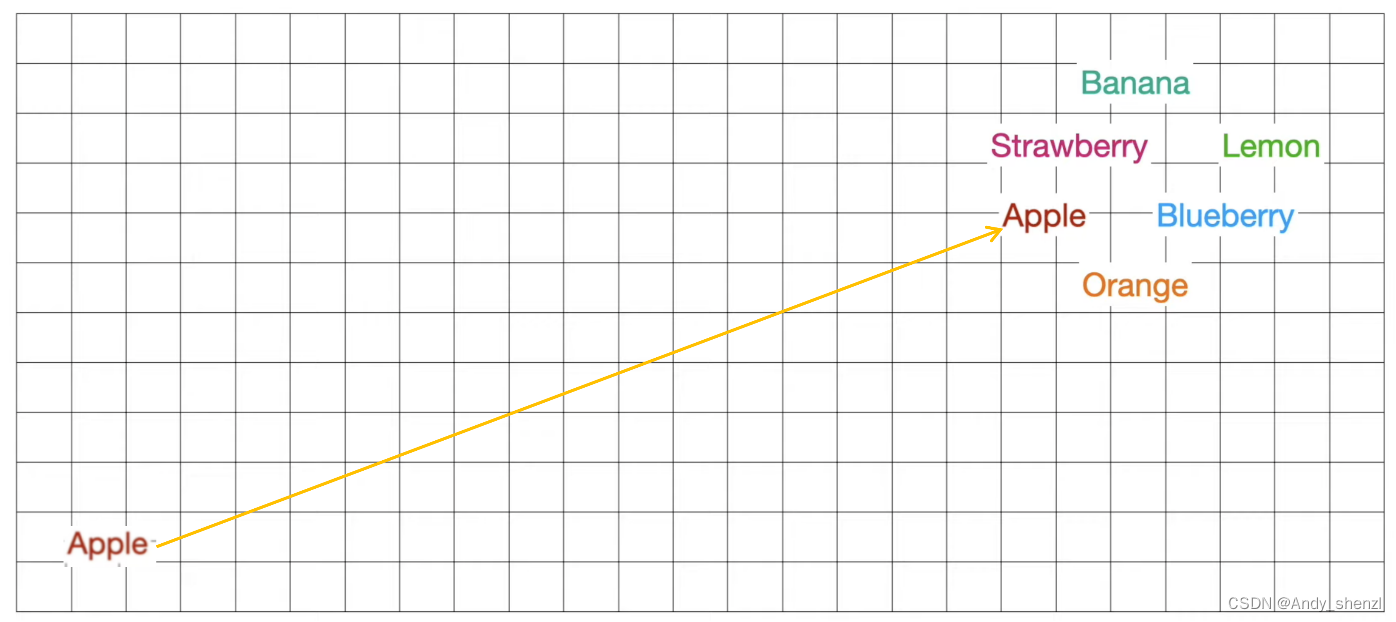
要想实现上述过程,计算机就必须要计算所有单词来查看或者评估苹果这个词,通过程序不断的训练会发现,苹果和橘子这两个词比较接近,而与其他的词关系不是很大,那么orang就与apple这个单词相关性更大,我们这里绘制了更粗的连线,我们可以把他们想象成单词之间是有相互吸引力的,连线越粗其吸引力越大,最后距离就会越近。
其实,所有的单词之间都有相互的吸引力,但是随着不断的训练,单词之间会趋于一个平衡,比如buy这个单词,与他相关的单词会相互吸引聚成一簇,比如sell等,而苹果、橘子等水果相关的词会聚集在一起,可以想象成Kmeans聚类算法。
或者想象一下我们的宇宙空间的星球,他们之间都是有作用力的,因为地球和月球比较近,相互吸引力越大,所以相关性越大;而月球与其他的相求也有吸引力,但是比起与地球之间的相互吸引力就太弱了,也就是月球的大部分注意力都在地球上。
所以如果上下文一直在讨论香蕉、橘子等水果,那么接下来出现的apple这个单词大概率就是我们吃的苹果,那么聚集在一起的水果这个簇就会把apple这个单词拉到水果簇中心的方向。
其实这就模型跟踪内容的方式,也就是注意力机制的可视化的步骤。
6、 多头注意力
当我们建立好了一个注意力机制后,那么我们怎么确定这是一个非常好的embedding呢?
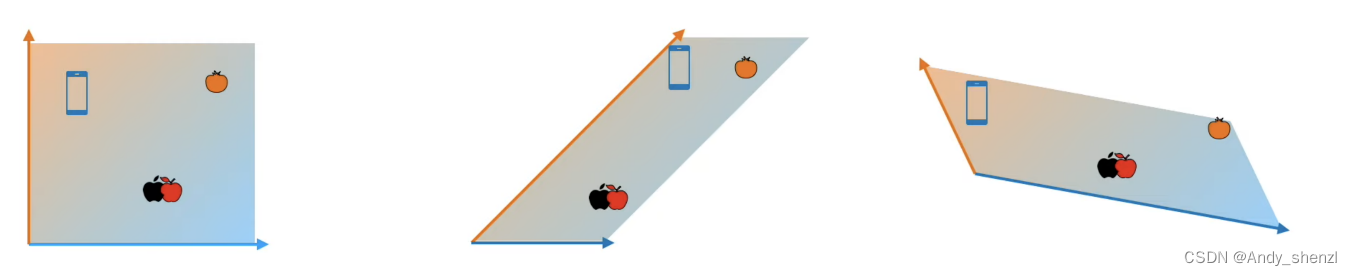
理想情况下可以有很多的词嵌入,把他们结合起来形成一个更强大的词嵌入矩阵
我们看一下现在我们有三个初始化的embedding矩阵,自己想一下,哪一个词嵌入是最好的
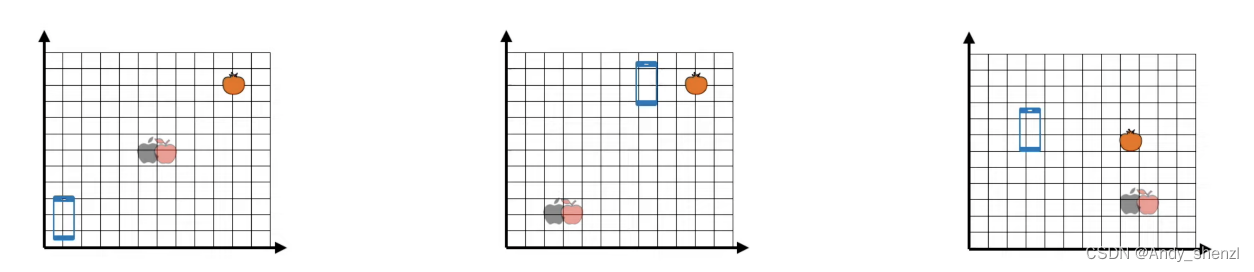
当然是第一个,因为他可以把两个不同簇分得更开,更加容易辨别。当我们对apple进行训练时,不管结果是拉向橘子还是手机,他们在拉近一个的同时会远离另外一个,这样就类似于聚类时可以很确定的将这个点进行归类,消除歧义。
所以我们初始化一个词嵌入时,有可能是第一种好的,也有可能是第二个比较差的,所以我们多使用几个,获取得到好的embedding的概率就会越大。
7、 线性变换
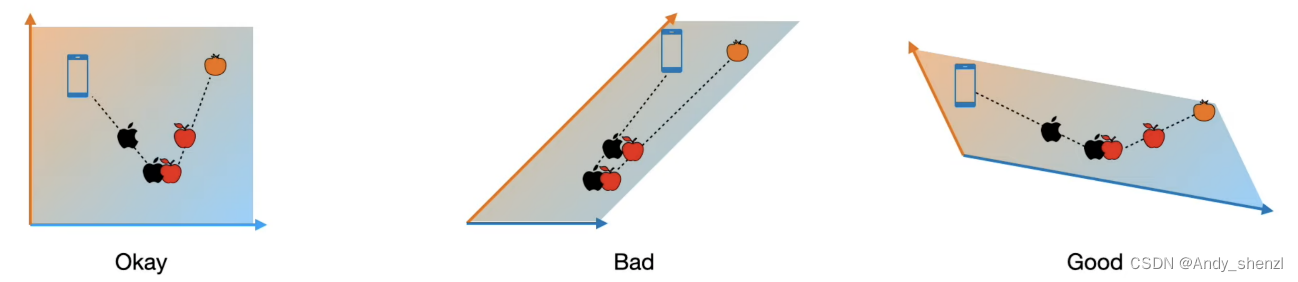
当然如果嵌入多了也会有问题,如果我们从不同的方式或者维度进行创建词嵌入矩阵,那么结果会变的不可控制,所以我们不能仅仅采用一大堆的嵌入进行组合
我们要做的是建立一个词嵌入矩阵,在此基础上进行修改和转换,就是我们要讲的线性变换
比如我们对原始embedding进行了两种变换,那么大家可以考虑下那种变换是变得更好呢
很明显是第三种,那么现在我们为了能够选出更好的词嵌入,我们可以给出评分,好的词嵌入给高的分数,不好的给予低的分数
最终的得分就是查询矩阵、键矩阵和值矩阵要做的事情
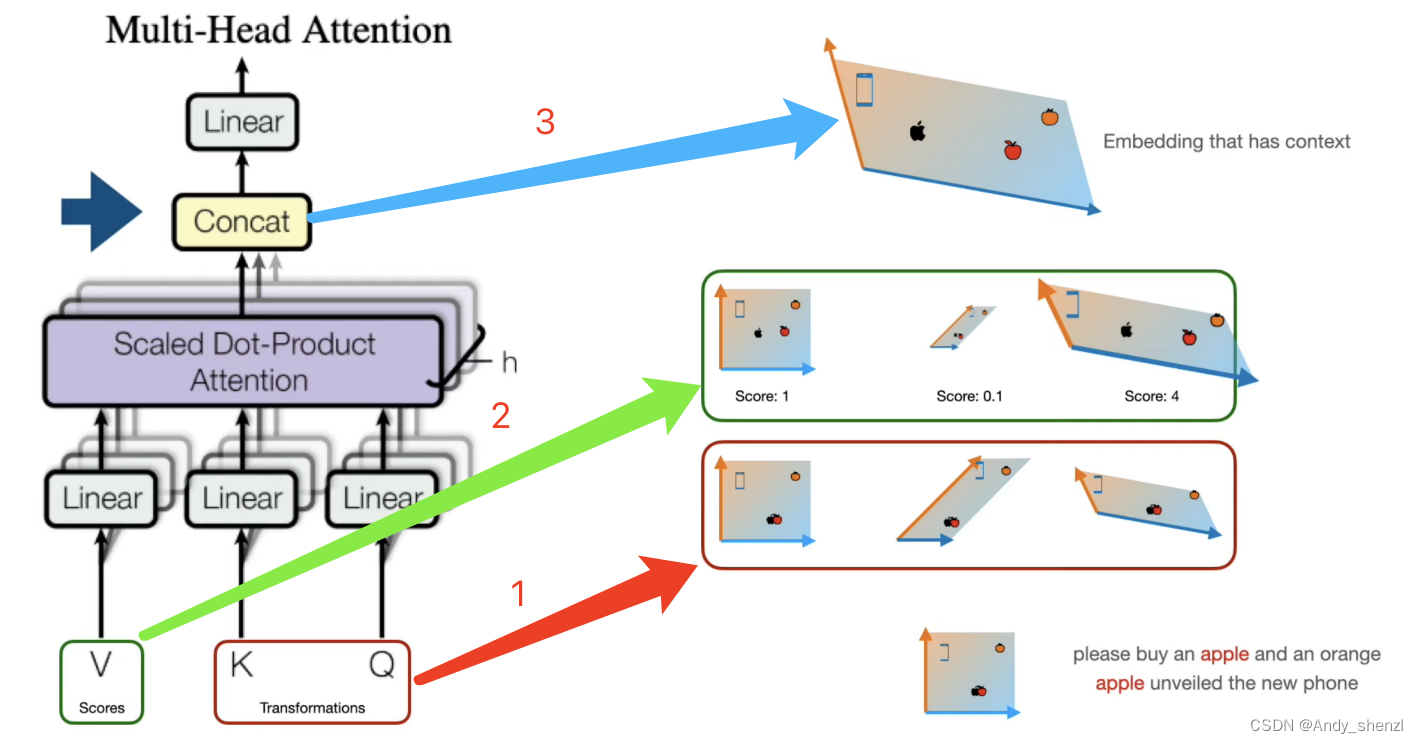
- 首先我们根据文本创建一初始的词嵌入,现在我们使用Q、K来创建变换
- V矩阵帮助我们进行评分,好的变化给予高的权重,不好的赋值较低的权重
- 根据得分我们将所有的矩阵进行加权求和得到最终的词嵌入
以上就是注意力机制的全部内容,下一篇会讲一下Q、K、V矩阵相关知识。。。















 4019
4019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











