







LLaMA3-405B的模型效果已经赶上目前最好的闭源模型GPT-4o和Claude-3.5,这可能是未来大模型开源与闭源的拐点,这里就LLaMA3的模型结构、训练过程与未来影响等方面说说我的看法。
LLaMA3的模型结构
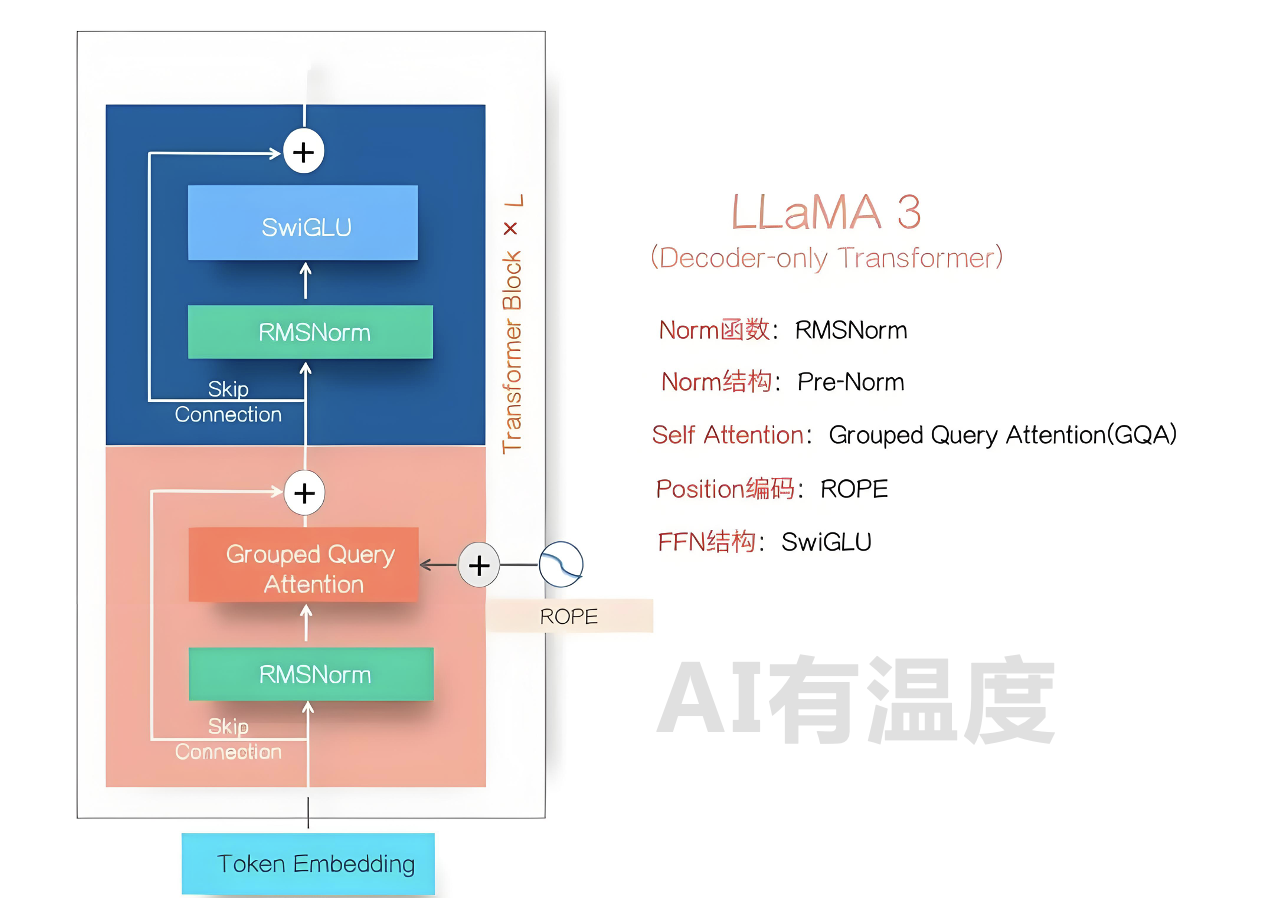
LLaMA3的模型结构如上图所示,这基本已经成为目前Dense LLM模型的标准结构了,很多采取MOE结构的LLM模型,其变化无非是把上图的FFN模块里的单个SwiGLU模块拓展成K个并联的SwiGLU模块,形成多个专家,再加上一个门控网络来选择目前Token走这么多专家里的哪几个。目前很少有结构能逃脱Transformer架构的影响,对比Transformer的部件升级主要有以下三点:
**第一:FFN层激活函数由GELU(ReLU的平滑版本)变为了SwiGLU,引入了更多的权重矩阵。**FFN层包括两个线性变换,中间插入一个非线性激活函数,最初的Transformer架构采用了ReLU激活函数:
FFN ( x , W 1 , W 2 , b 1 , b 2 ) = ReLU ( x W 1 + b 1 ) W 2 + b 2 \operatorname{FFN}\left(x, W_{1}, W_{2}, b_{1}, b_{2}\right)=\operatorname{ReLU}\left(x W_{1}+b_{1}\right) W_{2}+b_{2} FFN(x,W1,W2,b1,b2)=ReLU(xW1+b1)W2+b2
在他们的实验中使用了不包含bias项的FFN:
FFN ( x , W 1 , W 2 ) = ReLU ( x W 1 ) W 2 \operatorname{FFN}\left(x, W_{1}, W_{2}\right)=\operatorname{ReLU}\left(x W_{1}\right) W_{2} FFN(x,W1,W2)=ReLU(xW1)W2
经过不断研究提出了Switch激活函数,其中 σ ( x ) \sigma(x) σ(x)是Sigmoid 函数。现在又诞生了SwiGLU:
Swish 1 = x ⋅ σ ( x ) \operatorname{Swish}_{1}=x\cdot\sigma(x) Swish1=x⋅σ(x)
FFN Swish ( x , W 1 , W 2 ) = Swish 1 ( x W 1 ) W 2 \operatorname{FFN}_{\text {Swish }}\left(x, W_{1}, W_{2}\right)=\operatorname{Swish}_{1}\left(x W_{1}\right) W_{2} FFNSwish (x,W1,W2)=Swish1(xW1)W2
SwiGLU ( x , W , V , b , c ) = Swish 1 ( x W + b ) ⊗ ( x V + c ) \operatorname{SwiGLU}(x, W, V, b, c)=\operatorname{Swish}_{1}(x W+b) \otimes(x V+c) SwiGLU(x,W,V,b,c)=Swish1(xW+b)⊗(xV+c)

第二:归一化由post Layer Normalization变为pre RMSNorm,由后变前的同时计算公式也不同。
- Layer Norm:减去样本的均值,除以样本的方差,中心化的同时进行缩放
- RMSNorm:去除了减去均值的操作,也就是没有去中心化的操作,只有缩放的操作。所以RMSnorm就是均值为0的Layer Norm。推荐阅读:Batch Normalization究竟学到了数据的什么信息?
第三:由三角函数计算的绝对位置编码改为了RoPE相对旋转位置编码,解决了长文本预测外推性问题。推荐阅读:手把手带你从零推导旋转位置编码RoPE
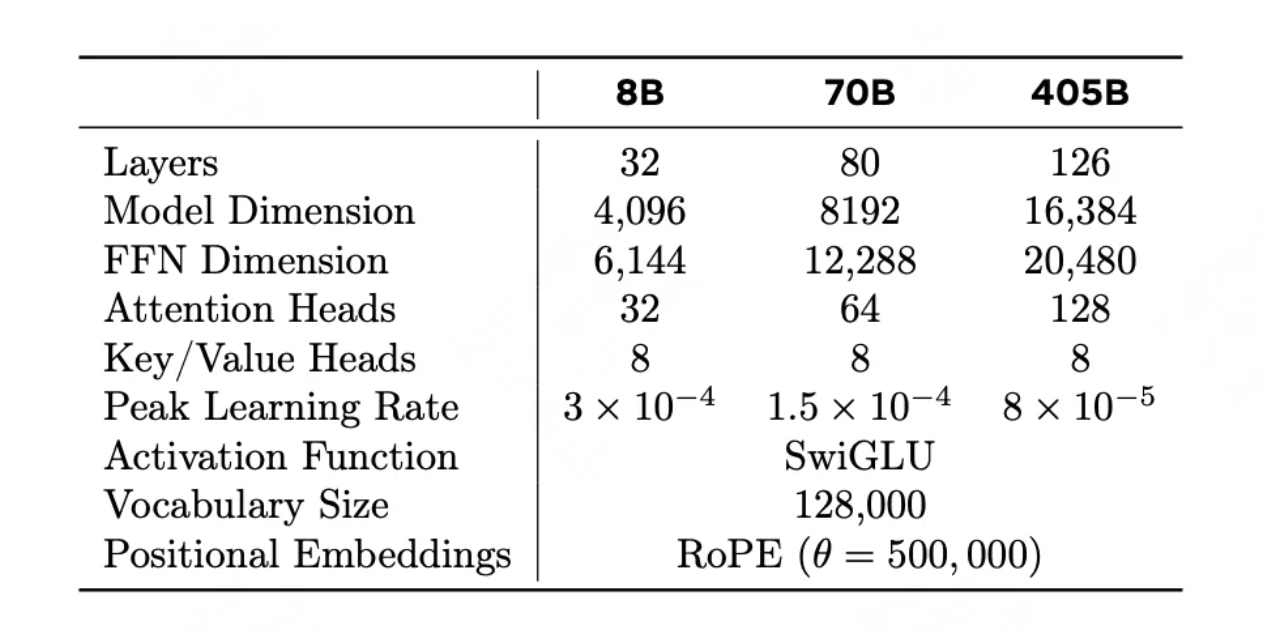
其余的变化就是模型层数横向及纵向的叠加(见上图),比如405B模型采用了126层的网络结构,RoPE theta 调到了50万等等。
LLaMA3训练过程
- 数据打标与配比:做细粒度的打标签工作,然后根据标签采样,最终敲定了:50% 通用数据、25% 数理数据、17% 代码数据、 8% 多语言数据。这个过程在实际操作过程中应该很复杂,因为需要不断的尝试实验,最终选择效果最好的模型
- 预训练:本文长度从8K 逐步增加到支持128K,的上下文窗口,这个长上下文预训练阶段使用了大约800B训练token数据
- 退火(annealing)训练:最后用高质量的4000万个token数据学习,线性地将学习率衰减至0,同时保持上下文长度为128K个token。在这一退火阶段,调整了数据混合配比,以增加高质量数据比如数学、代码、逻辑内容的影响
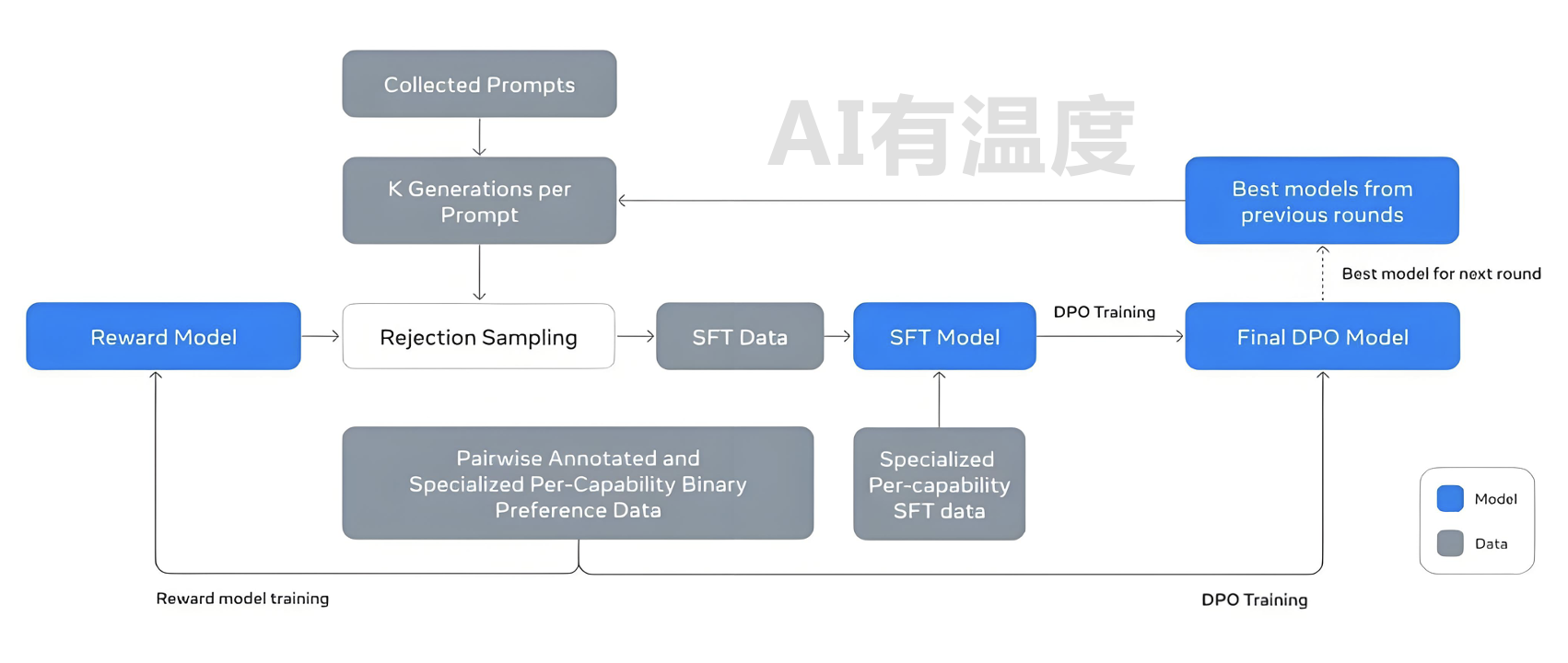
- 在Post-Training过程中(见上图),首先用人工标注数据训练RM模型,用来评价一个<Prompt,answer>数据的质量,然后用RM参与拒绝采样(Rejection Sampling),就是说对于一个人工Prompt,用模型生成若干个回答,RM给予质量打分,选择得分最高的保留作为SFT数据,其它抛掉。这样得到的SFT数据再加上专门增强代码、数学、逻辑能力的SFT数据一起,用来调整模型得到SFT模型
- 训练方法最终采用了DPO,并没有直接采用PPO的训练方式,官方的解释是Managing complexity。不懂DPO与PPO的同学推荐阅读:详解大模型的训练过程
- 之后用人工标注数据来使用DPO模型调整LLM参数,DPO本质上是个二分类,就是从人工标注的<Prompt,Good Answer,Bad Answer>三元数据里学习,调整模型参数鼓励模型输出Good Answer,不输出Bad Answer,这算完成了一个迭代轮次的Post-Training
- 上述过程会反复迭代几次,每次的流程相同,不同的地方在于拒绝采样阶段用来对给定Prompt产生回答的LLM模型,会从上一轮流程最后产生的若干不同DPO模型(不同超参等)里选择最好的那个在下一轮拒绝采样阶段给Prompt生成答案。很明显,随着迭代的增加DPO模型越来越好,所以拒绝采样里能选出的最佳答案质量越来越高,SFT模型就越好,如此形成正反馈循环
- 可以看出尽管RLHF 和DPO两种模式都包含RM,但是用的地方不一样:RLHF是把RM打分用在PPO强化学习阶段,而LLaMA 3则用RM来筛选高质量SFT数据
LLaMA3带来的影响
下图展示了开源和闭源模型随着时间能力差异曲线,可以看出两者差距随着时间是逐步减小的,而LLaMA 3-405B让两线出现了交点。
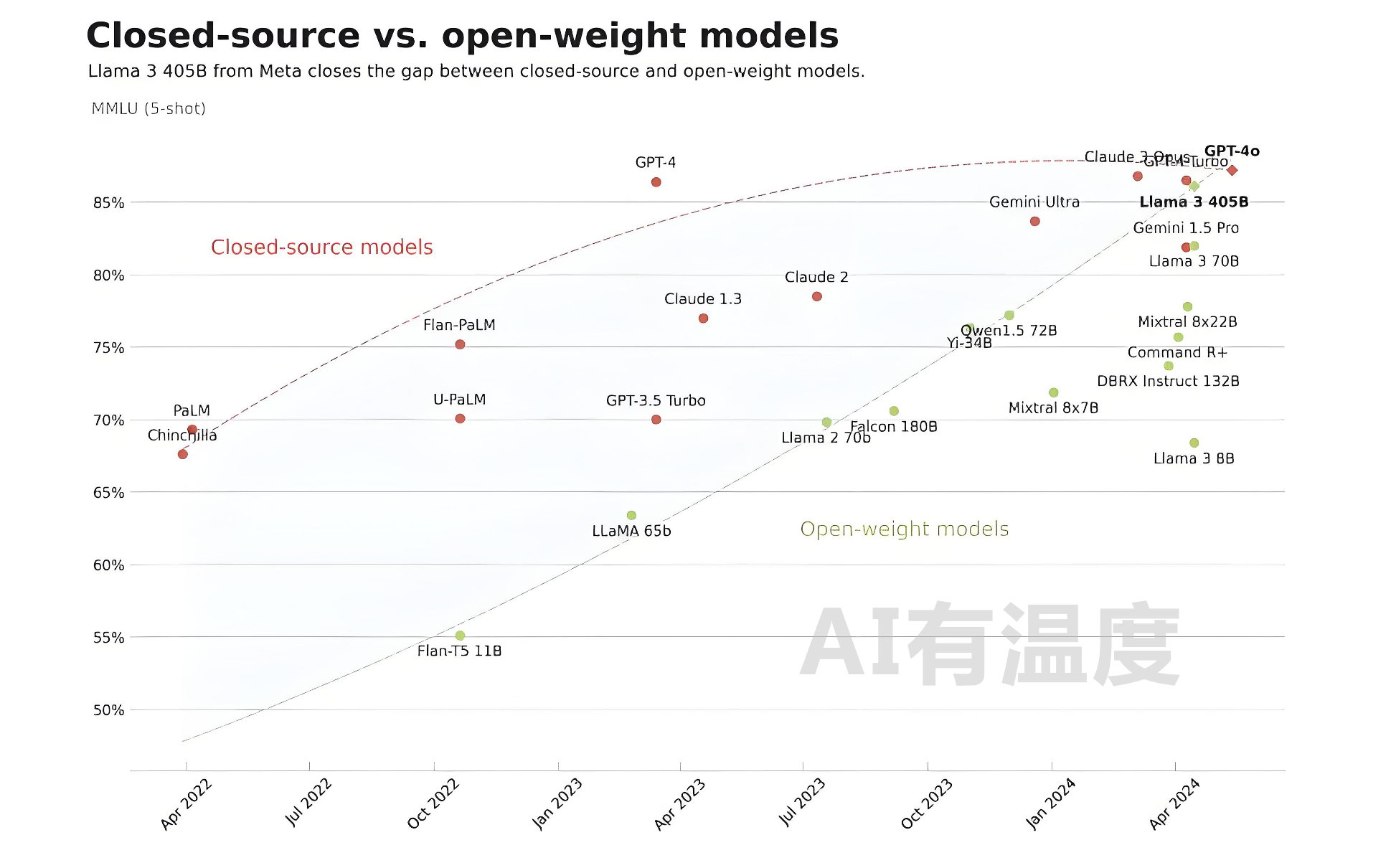
LLaMA 3-405B的开源,对于其它无论闭源还是开源模型,都有重大影响:
- 对于闭源模型,如果其能力还赶不上LLaMA3(比如GPT或GLM),那很多付费用户为什么不去使用开源模型呢?
- 对于开源模型而言,如果能力不如LLaMA 3,就需要考虑如何作出差异化和不同特色的模型
我认为最后大模型的结果会是一两家独大,因为它最重要的能力就是知识的全面性与对话推理能力,而如果做某一领域的模型,只要有那方面的数据,用以前的技术手段也能达到相同的效果。以目前情况来看,大模型的应用以调用为主,根据这个“大脑”开发配套的Agent即可,那我肯定会选一个最强的大脑进行开发…但是一家独大的发展可能并不利于以后这项技术以后的发展。
更多AI干货知识请关注【AI有温度】


















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









