







KV Cache 是大模型推理性能优化的一个常用技术,该技术可以在不影响任何计算精度的前提下,通过空间换时间的思想,提高推理性能。
冗余计算是如何产生的?
我们先推理一下基于Decoder架构的大模型的生成过程。用户输入“中国的首都”,模型续写得到的输出为“是北京”,模型的生成过程如下:
- 将“中国的首都”输入模型,得到每个token的注意力表示(绿色部分)。使用“首都”的注意力表示,预测得到下一个token为“是”
- 将“是”拼接到原来的输入,得到“中国的首都是”,将其输入模型,得到注意力表示,使用“是”的注意力表示,预测得到下一个token为“北”
- 将“北”拼接到原来的输入,依此类推,预测得到“京”,最终得到“中国的首都是北京”
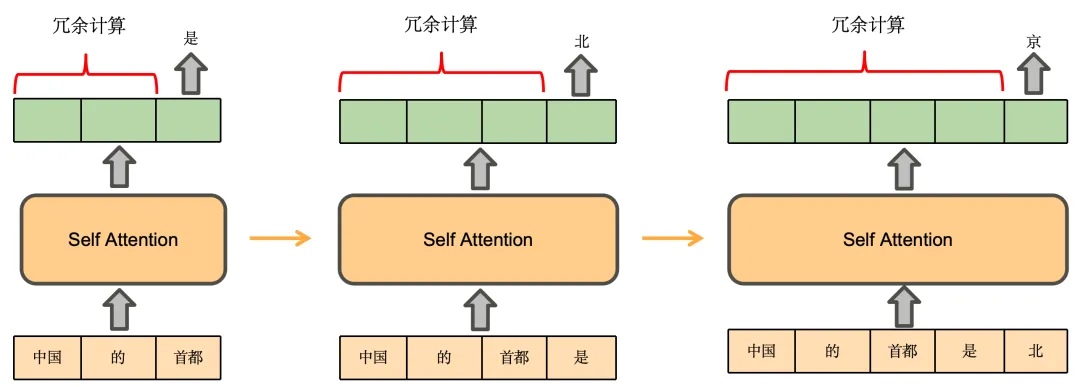
即在预测“是”时,实际发生的计算是这样的:
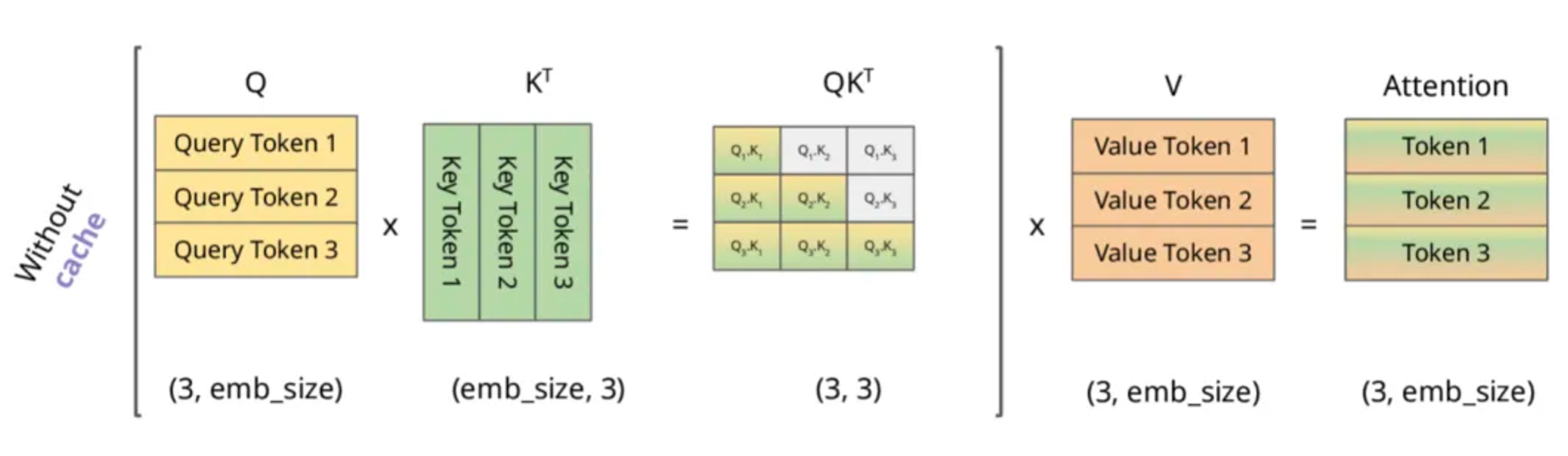
T o k e n 1 → Att 1 ( Q , K , V ) = softmaxed ( Q 1 K 1 T ) V 1 → T o k e n 2 → Att 2 ( Q , K , V ) = softmaxed ( Q 2 K 1 T ) V 1 → + softmaxed ( Q 2 K 2 T ) V 2 → T o k e n 3 → Att 3 ( Q , K , V ) = softmaxed ( Q 3 K 1 T ) V 1 → + softmaxed ( Q 3 K 2 T ) V 2 → + softmaxed ( Q 3 K 3 T ) V 3 → \begin{array}{l}Token1 \rightarrow \operatorname{Att}_{1}(Q, K, V)=\operatorname{softmaxed}\left(Q_{1} K_{1}^{T}\right) \overrightarrow{V_{1}} \\ Token2 \rightarrow \operatorname{Att}_{2}(Q, K, V)=\operatorname{softmaxed}\left(Q_{2} K_{1}^{T}\right) \overrightarrow{V_{1}}+\operatorname{softmaxed}\left(Q_{2} K_{2}^{T}\right) \overrightarrow{V_{2}} \\ Token3 \rightarrow \operatorname{Att}_{3}(Q, K, V)=\operatorname{softmaxed}\left(Q_{3} K_{1}^{T}\right) \overrightarrow{V_{1}}+\operatorname{softmaxed}\left(Q_{3} K_{2}^{T}\right) \overrightarrow{V_{2}}+\operatorname{softmaxed}\left(Q_{3} K_{3}^{T}\right) \overrightarrow{V_{3}}\end{array} Token1→Att1(Q,K,V)=softmaxed(Q1K1T)V1Token2→Att2(Q,K,V)=softmaxed(Q2K1T)V1+softmaxed(Q2K2T)V2Token3→Att3(Q,K,V)=softmaxed(Q3K1T)V1+softmaxed(Q3K2T)V2+softmaxed(Q3K3T)V3
根据上述图解与公式可发现:
- 对于
T
o
k
e
n
1
Token1
Token1的计算,由于$Q_1K_2^T
和
和
和Q_1K_3^T
会
m
a
s
k
掉,所以在计算
会mask掉,所以在计算
会mask掉,所以在计算Token1
时仅与
时仅与
时仅与Q_1
、 、 、K_1 、 、 、V_1$有关 - 对于
T
o
k
e
n
2
Token2
Token2的计算,由于$Q_2K_3^T
会
m
a
s
k
掉,所以在计算
会mask掉,所以在计算
会mask掉,所以在计算Token2
时仅与
时仅与
时仅与Q_2
、 、 、K_1 、 、 、K_2 、 、 、V_1 、 、 、V_2$有关 - 对于
T
o
k
e
n
3
Token3
Token3的计算,仅与$Q_3
、 、 、K_1 、 、 、K_2 、 、 、K_3 、 、 、V_1 、 、 、V_2 、 、 、V_3 $有关
由此发现在计算
T
o
k
e
n
3
Token3
Token3“是”时,我们仅需$Q_3
与所有的
与所有的
与所有的KV
值即可,而不需要对之前的
值即可,而不需要对之前的
值即可,而不需要对之前的Token$进行重复计算,所以当前方式存在大量冗余计算,可以得出以下结论:
-
Att
k
(
Q
,
K
,
V
)
\operatorname{Att}_{k}(Q, K, V)
Attk(Q,K,V)的计算过程中,主要与$Q_k
$有关 - 每一次生成新的Token都需要用到之前的KV,所以我们需要把每一步的KV缓存起来
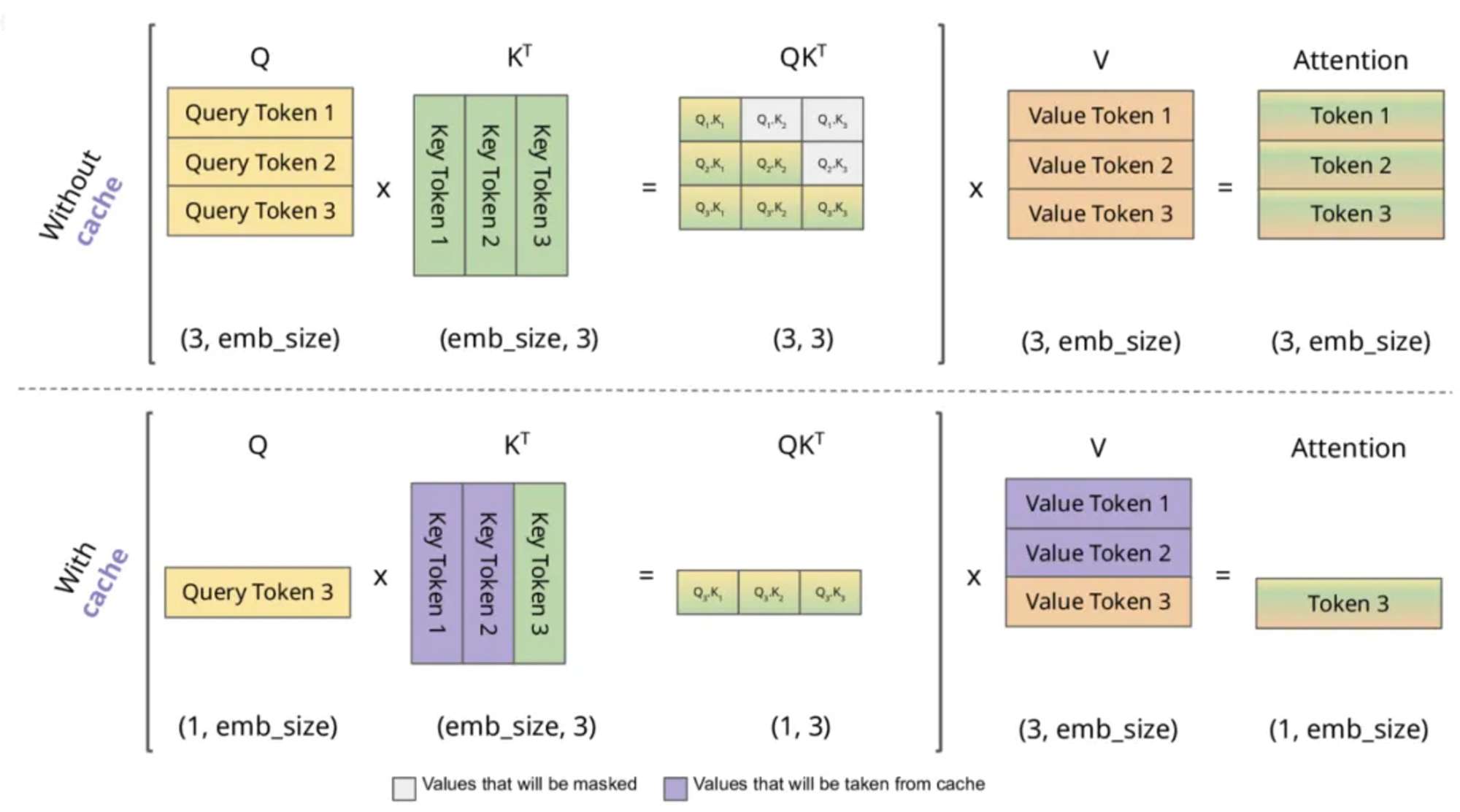
KV Cache是如何进行的?
KV Cache的本质是以空间换时间,它将历史输入的token的KV缓存下来,避免每步生成都重新计算历史的KV值。一个典型的带有 KV cache 优化的生成大模型的推理过程包含了两个阶段:
- 预填充阶段:输入一个prompt序列,为每个transformer层生成 key cache 和 value cache(KV cache),此步骤为并行同时计算序列的KV值
- 解码阶段:使用之前的KV cache并计算当前的KV值,并将当前的KV值保存到cache中,然后生成token
KV Cache 存在的问题以及优化措施
当将大模型应用输入过长时,使用原始的 Dense Attention 会出现两个主要挑战:
- 上下文越长,那么矩阵占用的内存也会越多,同时还会增加Decoder的延迟
- 现有模型的长度外推能力有限,即当序列长度超出预训练期间设置的attention窗口大小时,其性能会下降。
因此,目前提出了使用滑动窗口的注意力机制,主要有如下几种方式:
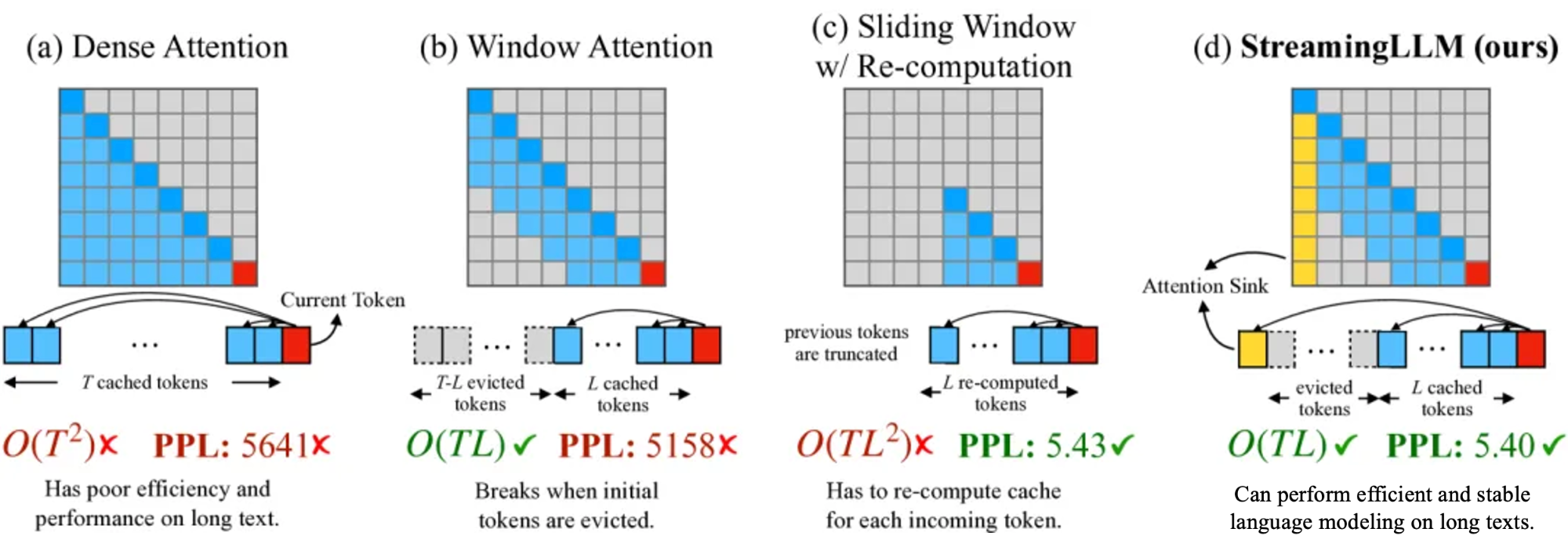
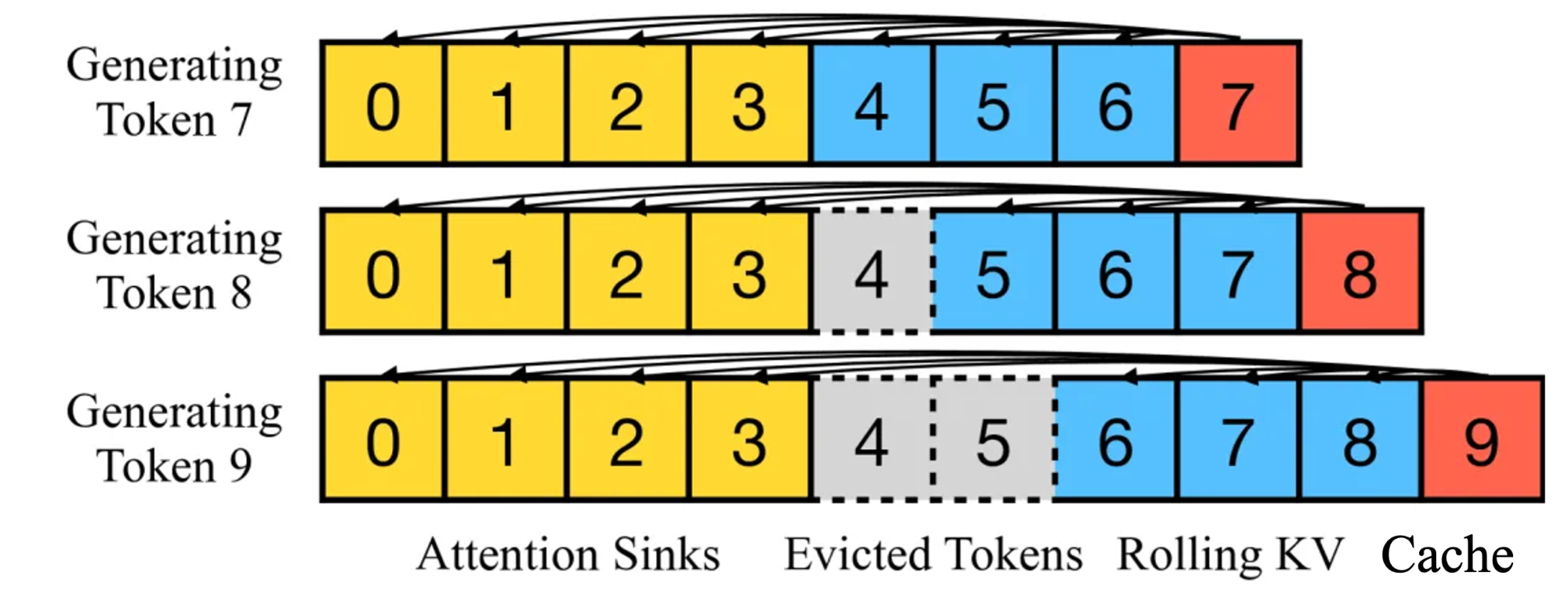
- 一种方式是如下图 B 的窗口注意力(Window Attention):只缓存最近的 L 个 Token 的 KV。虽然推理效率很高,但若起始Token的键和值被驱逐,性能就会急剧下降
- 一种方式是下图 C 的滑动窗口重计算(Sliding Window w/ Re-computation):根据每个新 Token 的 L 个最近 Token 重建 KV 状态。虽然它在长文本上表现良好,但其 O ( T L 2 ) O(TL^2) O(TL2)的复杂性(源于上下文重新计算中的二次注意力)使其相当慢
- 还有一种方式是StreamingLLM,在当前滑动窗口方法的基础上,重新引入了一些最初的 tokens 的KV在注意力计算中使用。StreamingLLM 中的KV缓存可以概念上分为两部分,如下图所示:attention sink 是 4 个最初的 tokens,稳定了注意力计算;Rolling KV Cache 保留了最近的token,这个窗口值是固定的。此外,还需要有些小改动来给attention注入位置信息,StreamingLLM就可以无缝地融入任何使用相对位置编码的自回归语言模型,如RoPE和ALiBi
同时,还有一些权重共享的思路来对空间缓存进行优化,以达到减少 Key 和 Value 矩阵的参数量的目的,比如GQA与MQA。
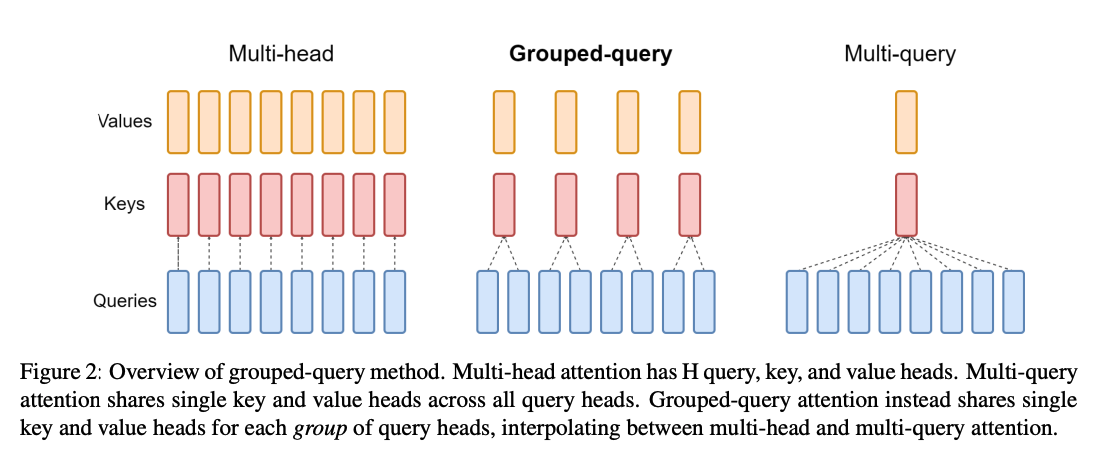
- MHA:n个Q对应n个K与V,QKV之间一一对应
- GQA:一组Q共享一个K与V
- MQA:所有Q共享一个K与V
KV Cache 是一种典型的通过空间换时间的技术,在以Transformer-decoder架构为主的生成式大语言模型中能取得巨大的收益。

















 1436
1436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









