







人脸小目标检测,就这个图:

HR
论文:HR - P. Hu, D. Ramanan. Finding Tiny Faces. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
之前我们讲过的一些方法都没有针对小目标去分析,小目标检测依然是检测领域的一个难题,本文作者提出的检测器通过利用尺度,分辨率和上下文多种信息融合来检测小目标,在上图的总共1000个人脸中成功检测到约800个,检测器的置信度由右侧的色标表示。
针对小目标人脸检测,作者主要从三个方面做了研究:尺度不变,图像分辨率和上下文,作者的算法在FDDB和WIDERFace取得了当时最好的效果。
作者分析了小目标人脸检测的三个问题:
Multi-task modeling of scales
一方面,我们想要一个可以检测小人脸的小模板;另一方面,我们想要一个可以利用详细特征(即面部)的大模板来提高准确性。取代“一刀切”的方法,作者针对不同的尺度(和纵横比)分别训练了检测器。虽然这样的策略提升了大目标检测的准确率,但是检测小目标仍然具有挑战性。
How to generalize pre-trained networks?
关于小目标检测的问题,作者提出了两个见解。
如何从预训练的深度网络中最佳地提取尺度不变的特征。
虽然许多应用于“多分辨率”的识别系统都是处理一个图像金字塔,但我们发现在插值金字塔的最底层对于检测小目标尤为重要。
因此,作者的最终方法是:通过尺度不变方式,来处理图像金字塔以捕获大规模变化,并采用特定尺度混合检测器,如下图:

(a)单一尺度模板和图像金字塔
(b)不同尺度模板和单一图像
(c)粗略尺度模板和粗略图像金字塔,(a)和(b)的结合
(d)含有上下文信息的固定大小多尺度模板和粗略图像金字塔
(e)定义了从深度模型的多个层中提取的特征模板,也就是foveal descriptors
How best to encode context?
作者证明从多个层中提取的卷积深度特征(也称为 “hypercolumn” features)是有效的“ foveal”描述符,其能捕获大感受野上的高分辨率细节和粗略的低分辨率线索。
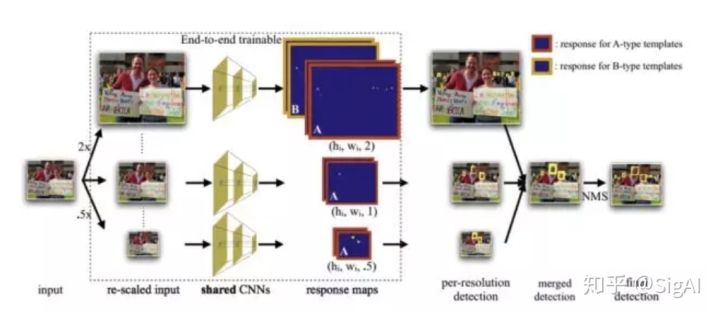
从输入图像开始,首先创建一个图像金字塔(2x插值)。然后我们将缩放的输入图像输入到CNN中,获得不同分辨率下人脸预测响应图(后续用于检测和回归)。最后将在不同尺度上得到的候选区域映射回原始分辨率图像上,应用非极大值抑制(NMS)来获得最终检测结果。
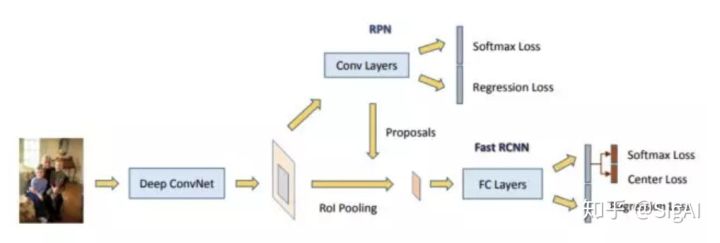
Face R-CNN
论文: Face R-CNN - H. Wang, Z. Li, X. Ji, Y. Wang. Face R-CNN. arXiv preprint arXiv:1706.01061, 2017
该方法基于Faster R-CNN框架做人脸检测,针对人脸检测的特殊性做了优化。
对于最后的二分类,在softmax的基础上增加了center loss。通过加入center loss使得类内的特征差异更小(起到聚类的作用),提高正负样本在特征空间的差异性从而提升分类器的性能。
加入在线困难样本挖掘(OHEM),每次从正负样本中各选出loss最大的N个样本加入下次训练,提高对困难样本的的分类能力。
多尺度训练,为了适应不同尺度影响(或者更好地检测小目标),训练阶段图片会经过不同尺度缩放。
SSH
论文:SSH - M. Najibi, P. Samangouei, R. Chellappa, L. Davis. SSH: Single Stage Headless Face Detector. IEEE International Conference on Computer Vision (ICCV), 2017
SSH最大的特色就是尺度不相关性(scale-invariant),比如MTCNN这样的方法在预测的时候,是对不同尺度的图片分别进行预测,而SSH只需要处以一个尺度的图片就可以搞定。实现方式就是对VGG网络不同level的卷积层输出做了3个分支(M1,M2,M3),每个分支都使用类似的流程进行检测和分类,通过针对不同尺度特征图进行分析,变相的实现了多尺度的人脸检测。
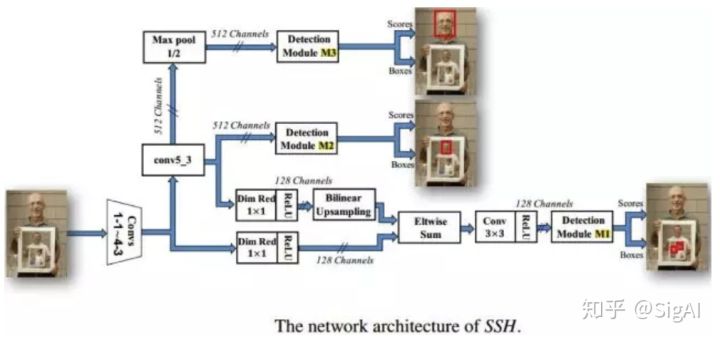
M1和M2,M3区别有点大,首先,M1的通道数为128,M2,M3的通道数为512,这里,作者使用了1*1卷积核进行了降维操作。其次,将conv4_3卷积层输出和conv5_3卷积层输出的特征进行了融合(elementwise sum),由于conv5_3卷积层输出的大小和conv4_3卷积层输出的大小不一样,作者对conv5_3卷积层的输出做了双线性插值进行上采样。
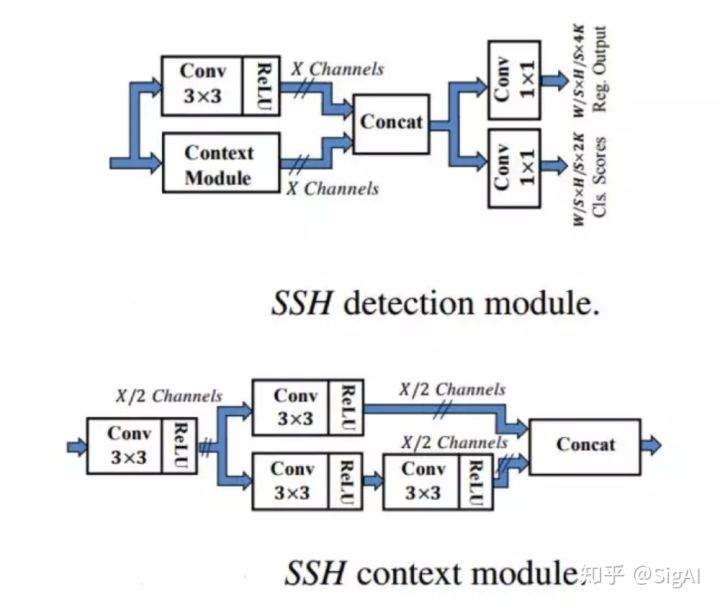
其中,M模块如上图所示,包含了分类和回归2个任务,其中Context Module的为了获得更多的上下文信息,更大的感受野,对该模块使用了等价的5*5和7*7的卷积分别进行操作,然后进行特征的concat最终形成了上图的Context Module。(由于大的卷积核效率问题,根据INCEPTION的思想,使用2个3*3的卷积核替代一个5*5的卷积核,使用3个3*3的卷积核替换1个7*7的卷积核)。
RSA
Recurrent Scale Approximation for Object Detection in CNN
ICCV2017
https://github.com/sciencefans/RSA-for-object-detection
本文还是针对人脸检测 中的 尺度问题 进展展开的。主要内容有以下三点:
1)首先使用一个 scale-forecast 网络来进行图像中人脸尺度的预测,
2)设计一个 recurrent scale approximation (RSA),使用 RSA 模块来 生产预测到尺度所对应的特征图,
3)提出一个 landmark retracing network (LRN),使用人脸局部特征信息来去除虚警。
对于多尺度问题 的三个解决方案如下图所示
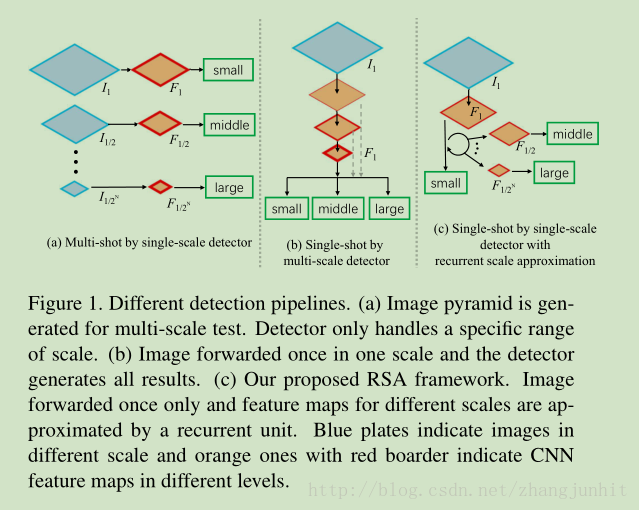
Multi-shot by single-scale detector 单尺度检测器对应 多尺度输入图像 得到不同尺度目标
Single-shot by multi-scale detector 多尺度检测器 对应 单尺度输入图像 得到不同尺度目标
本文的策略是直接将图像中目标的尺度检测出来,在知道尺度的情况下进行目标检测
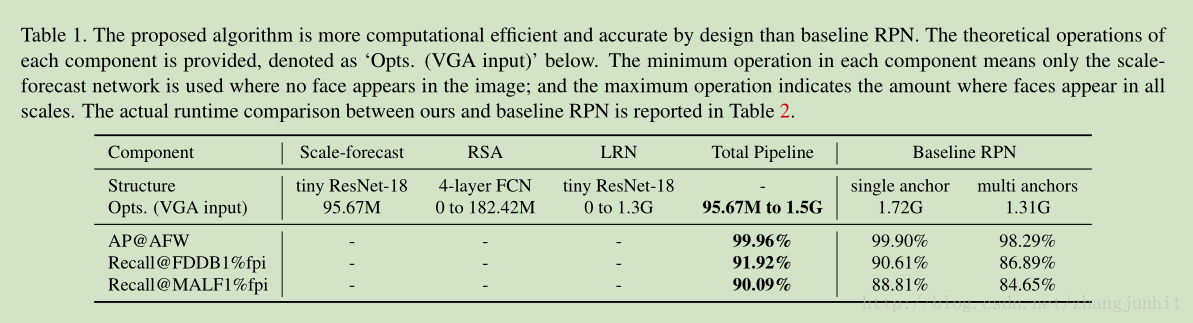
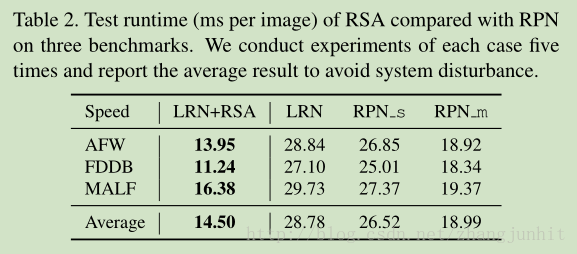
3.1. Scale-forecast Network
The network is a half-channel version of ResNet-18 with a global pooling at the end
Scale-forecast Network 采用 ResNet-18 的一半通道,最后使用 global pooling,
输出是一维向量, B 个 dimensions ,B = 60 is the predefined number of scales
通过公式将人脸框的长度映射到 一个直方图的 bin 中,直方图 bin 的数目是 B=60,
接着我们使用 Gaussian mixture model 来拟合该 直方图向量 来得到 我们想要的人脸尺度, 6个高斯对应 six main scales
determine the local maximum and hence the potential occurring scales
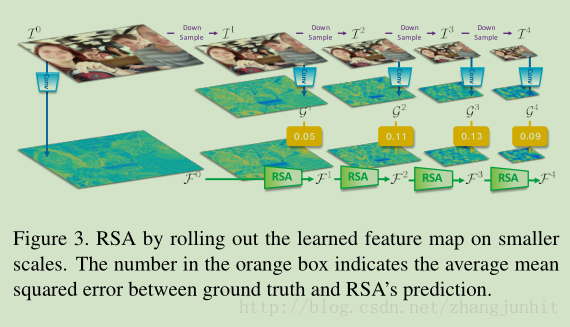
3.2. Recurrent Scale Approximation (RSA) Unit
使用 RSA 由最大尺寸的特征图得到我们期望的 尺寸的特征图
3.3. Landmark Retracing Network
这里主要使用人脸中的局部特征信息 Landmark 来去除检测中的 虚警

S3FD:
《S3FD: Single Shot Scale-invariant Face Detector》
code will be available at https://github.com/sfzhang15/SFD
1. 方法介绍
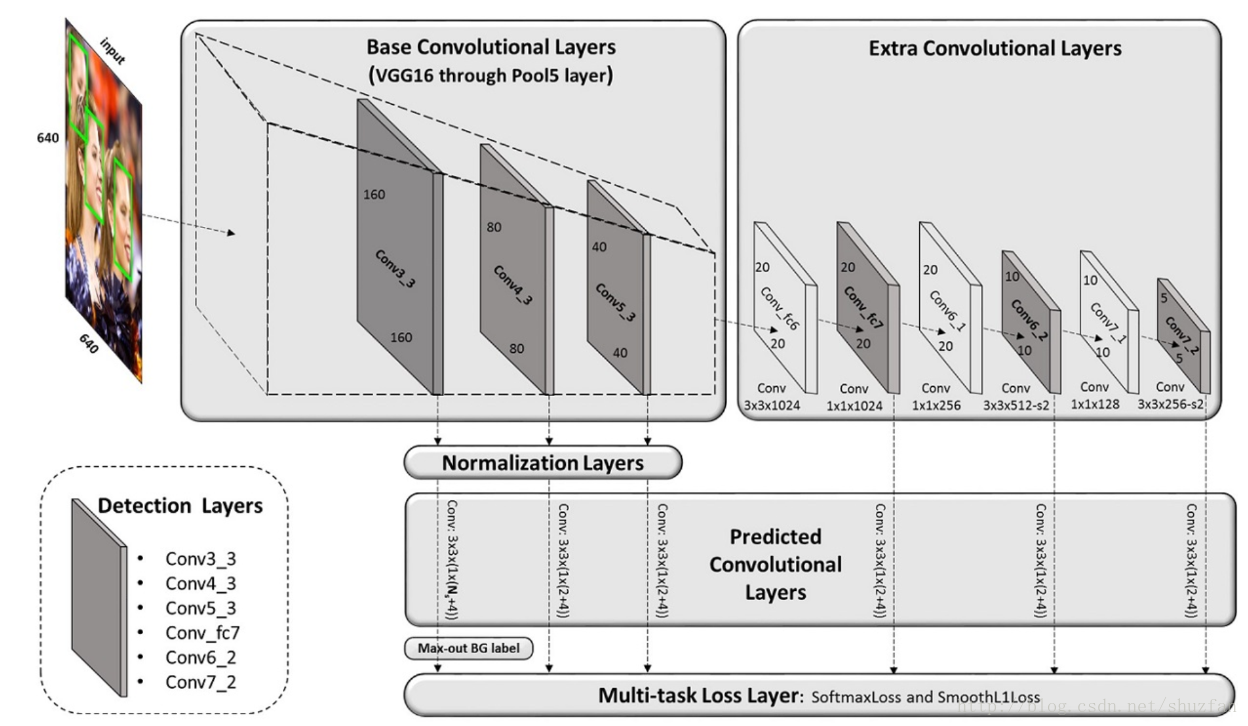
如上图,整体方法结构和SSD一致,在不同层使用不同尺度的anchor预测目标。
2. 要点介绍
(1)Reasons behind the problem of anchor-based methods
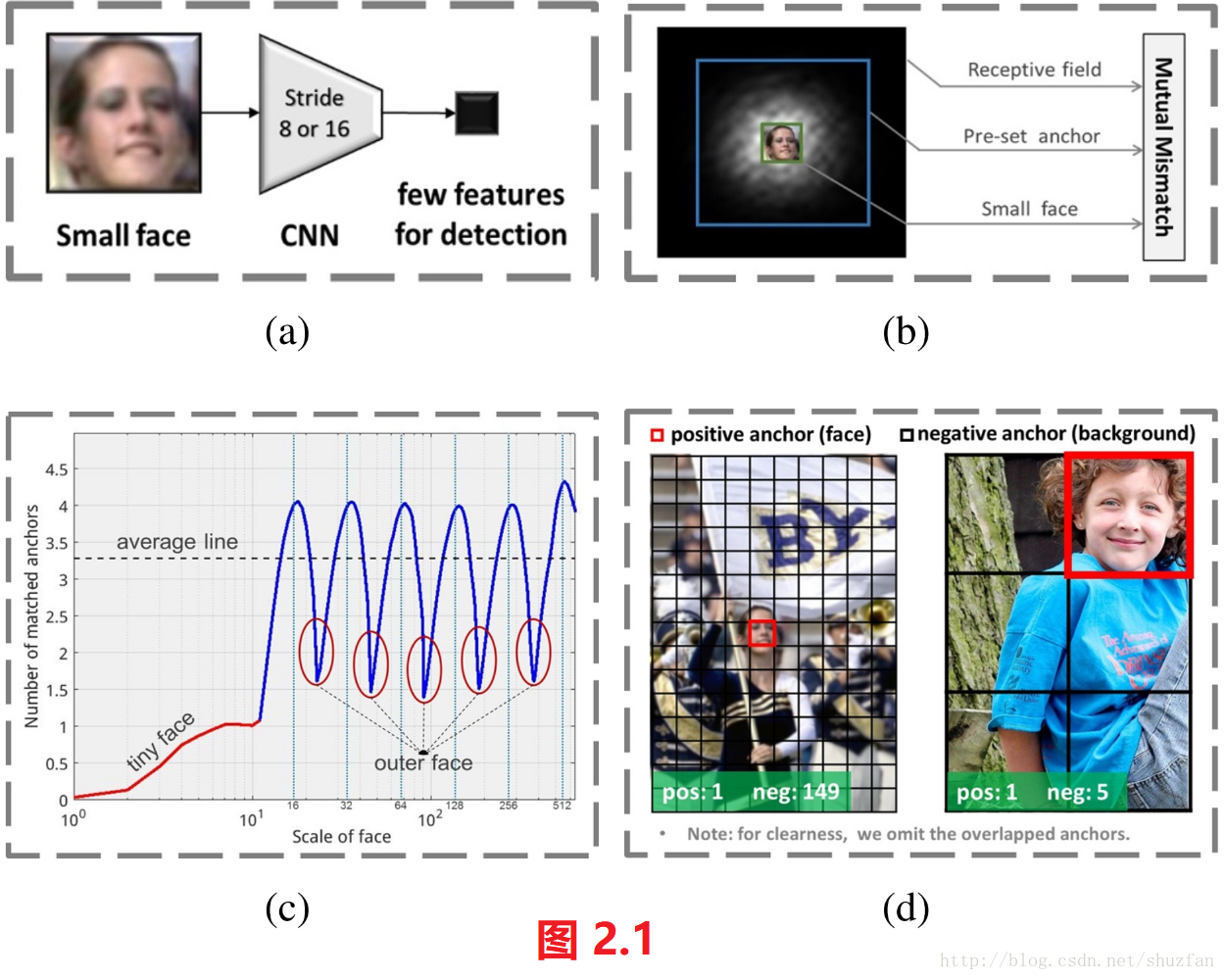
- (a) 由于spatial pooling,小尺度人脸最后拥有的特征太少;
- (b) anchor与感受野的尺度不匹配,且都太大而不适宜小人脸;
- (c) 离散尺度的anchor预测连续尺度的人脸,导致tiny face和outer face均不能获得足够多的匹配;
- (d) 小的anchor在进行匹配时会面临更多的负样本。
(2)Scale-equitable framework
首先看下表:(6个检测分支对应的空间stride、anchor以及感受野(RF)的大小)
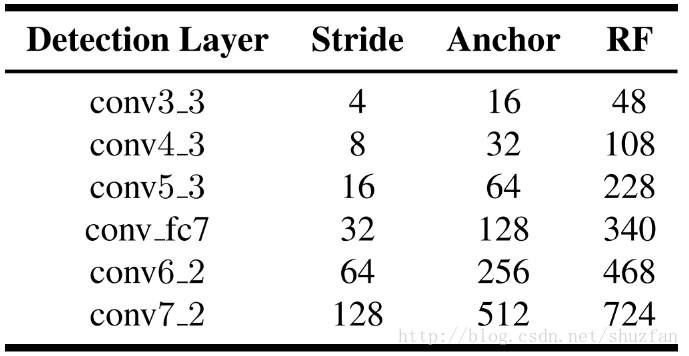
上表所表示的网络之所以如此设计,主要考虑下列两个因素:
* Anchor的size应当比(理论上的)感受野小*
理论上的感受野是指该范围内的任意输入都会影响到输出。 但实际上,这种影响不是均匀的,于是中间的输入对输出影响越重,类似于一种中心高斯分布。如下图(a)(b)所示:
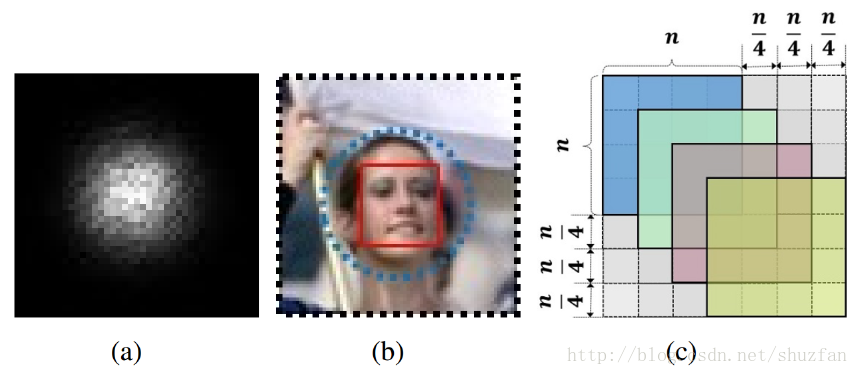
我们应当使得anchor的size与有效感受野相匹配,有效感受野如上图(b)中的蓝色圆圈所示。其中,黑色框为理论感受野。
* 不同size的anchor应当具有相同的空间密度分布*
如上图(c)所示,anchor的size与stride的比例始终保持为4。 这也就意味着,即使在不同尺度上,滑动过一定百分比(占anchor大小的百分比)的像素,得到的anchor的数量是一致的。
(3)Scale compensation anchor matching strategy
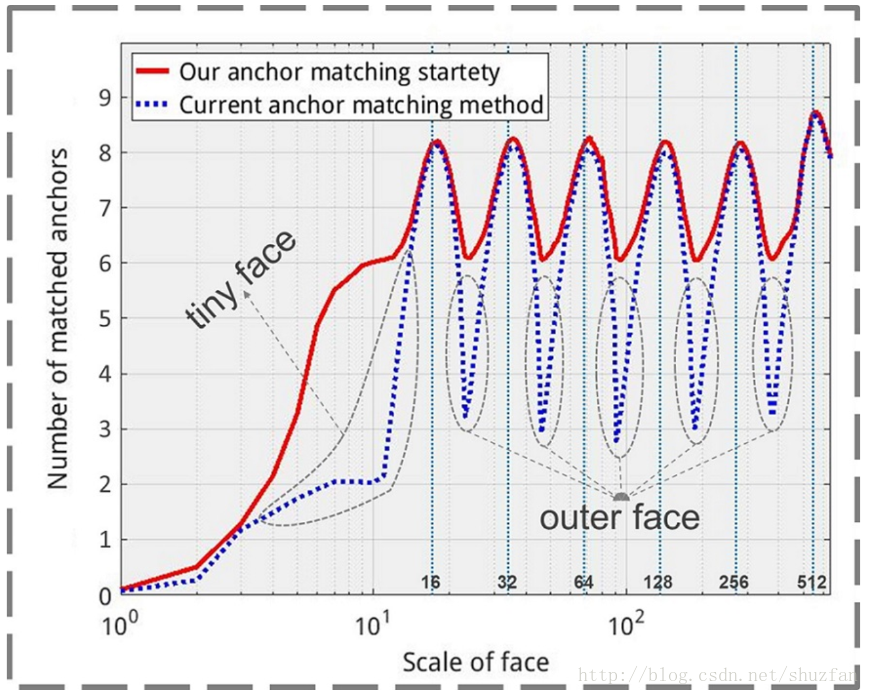
如图2.1(c)所示,平均匹配到的anchor数量约为3,太少;与anchor size差距较远的人脸匹配成功的数量尤其少(tiny face + outer face)。为了改善这种状况,主要采取了下列两种手段:
- (1)将原有的匹配阈值由0.5降到0.35,以此来增加更多的成功匹配。 (但该策略只能提高平均匹配数量,但不能改善tiny face和outer face。)
- (2)选出所有IOU大于0.1得到anchor并进行排序,从中选TOP N。(N为平均成功匹配数量。)
处理后的效果如下:
(4)Max-out background label
下表是一张640x640图片上所能产生的不同size的anchor的数量,显然尺寸小的anchor占了绝大比例,这也是false positive的主要来源。

为了减少小目标所产生的false positive,文中采用了下面的方法来加强对小目标的区分:
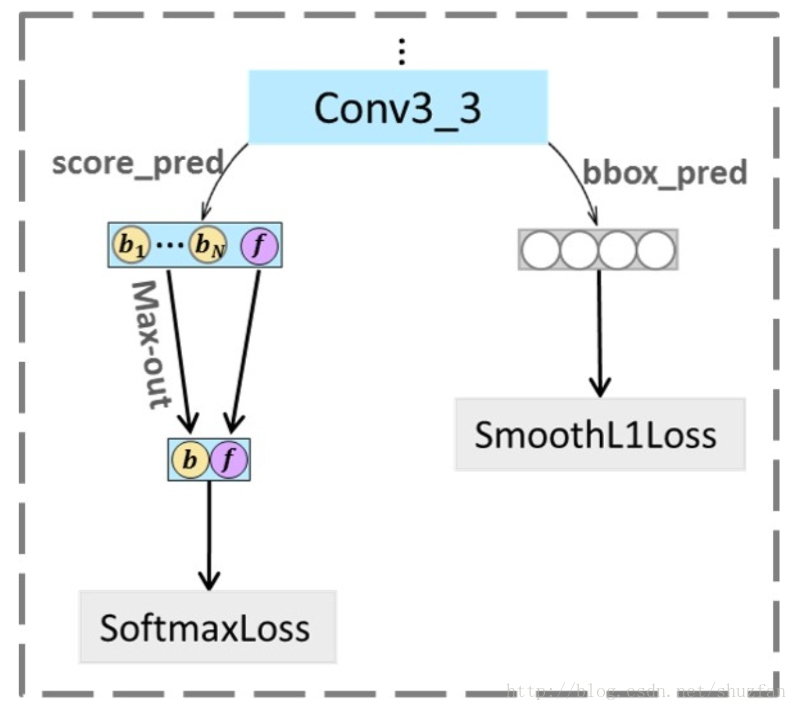
在conv3_3层(小目标产生最多的层),输出通道数为(Ns+4)(Ns+4),其中 Ns>2Ns>2,而其它所有检测层的输出通道数均为(2+4),表示二分类和4个bounding box坐标。 NsNs中包含了1个正样本的概率以及Ns−1Ns−1个负样本概率,我们从负样本概率中选出最大值与正样本概率一起完成之后的softmax二分类。 这种看似多余的操作实际上是通过提高分类难度来加强分类能力。
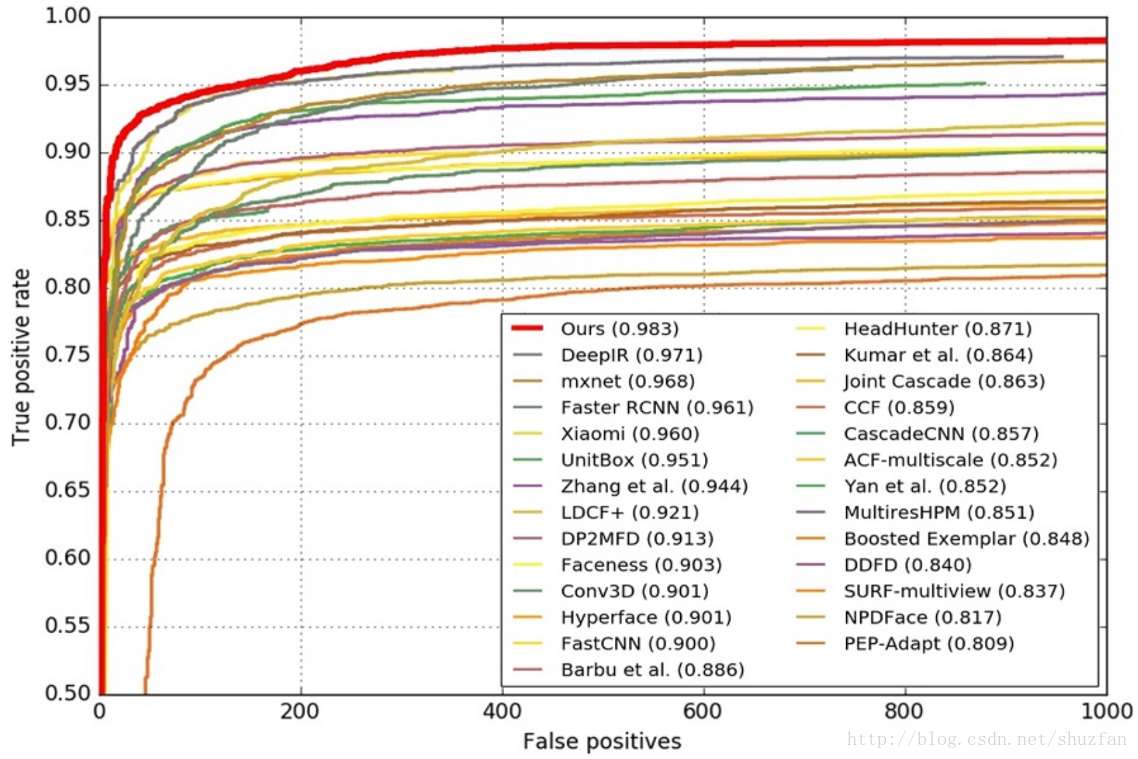
3. 实验结果
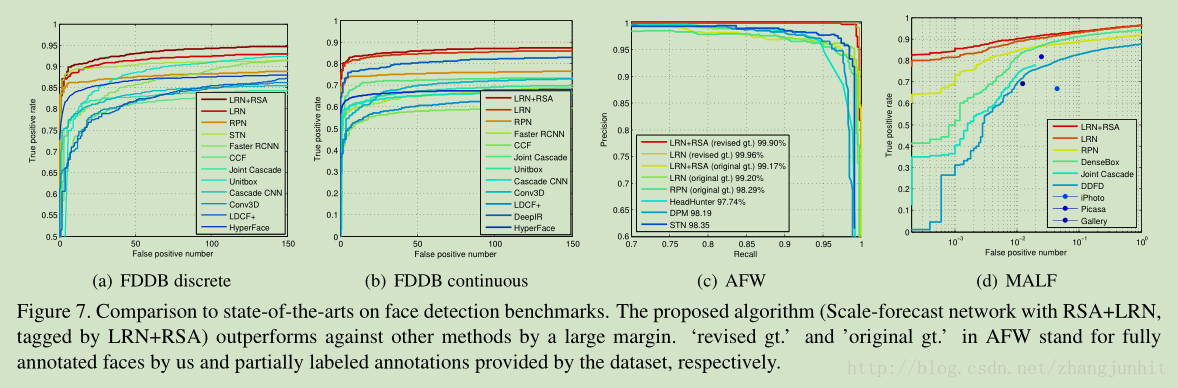
FDDB上的测试结果:
FaceBoxes
论文:《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》
1. 方法介绍
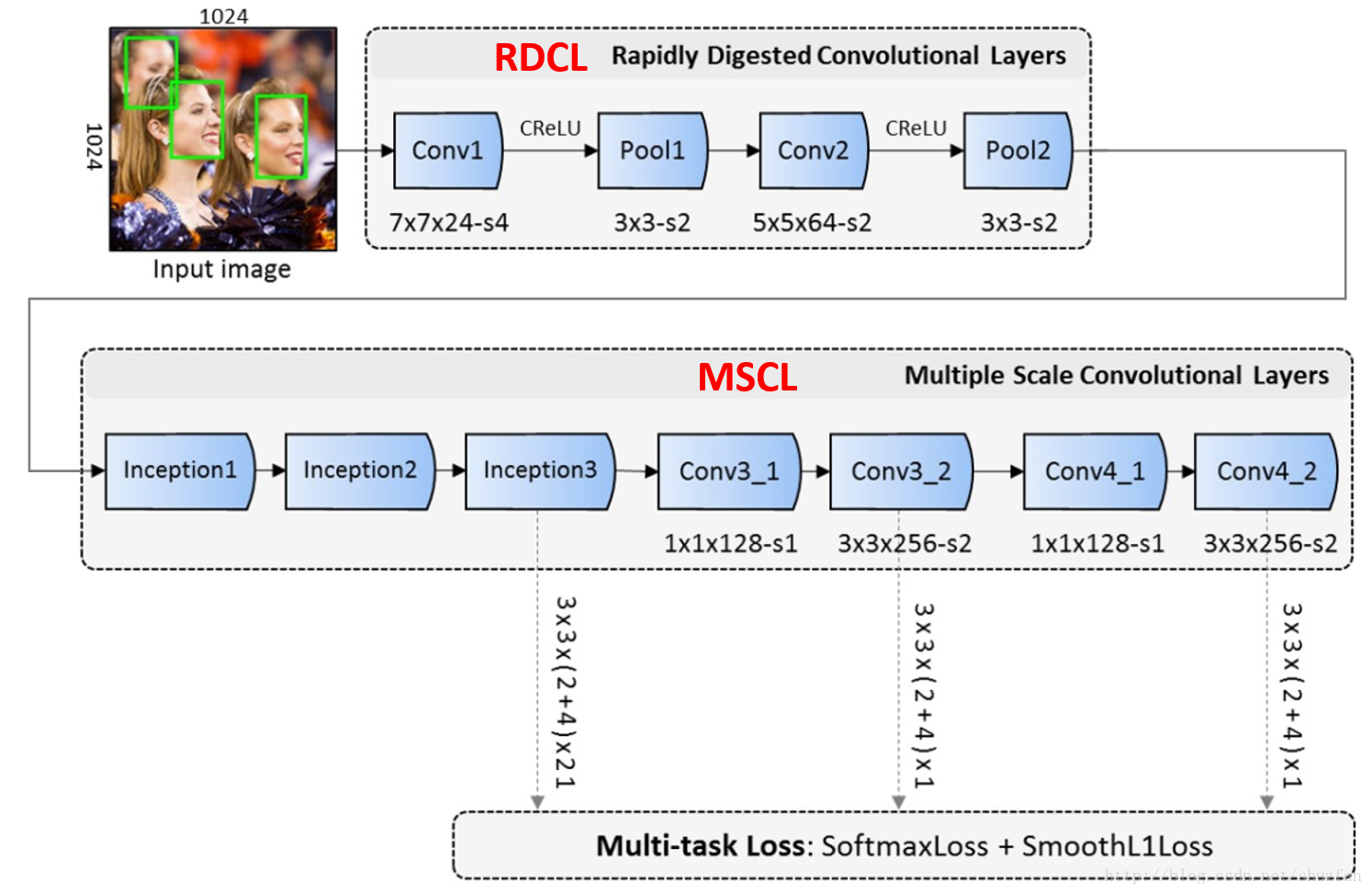
如上图,输入单张图片,在三个网络分支检测人脸。
2. 要点介绍
(1)Rapidly Digested Convolutional Layers(RDCL)
在网络前期,使用RDCL快速的缩小feature map的大小。 主要设计原则如下:
- (1) Conv1, Pool1, Conv2 和 Pool2 的stride分别是4, 2, 2 和 2。这样整个RDCL的stride就是32,可以很快把feature map的尺寸变小。
- (2)卷积(或pooling)核太大速度就慢,太小覆盖信息又不足。文章权衡之后,将Conv1, Pool1, Conv2 和 Pool2 的核大小分别设为7x7,3x3,5x5,3x3
- (3)使用CReLU来保证输出维度不变的情况下,减少卷积核数量。
(2)Multiple Scale Convolutional Layers(MSCL)
在网络后期,使用MSCL更好地检测不同尺度的人脸。 主要设计原则有:
- (1) 类似于SSD,在网络的不同层进行检测;
- (2) 采用Inception模块。由于Inception包含多个不同的卷积分支,因此可以进一步使得感受野多样化。
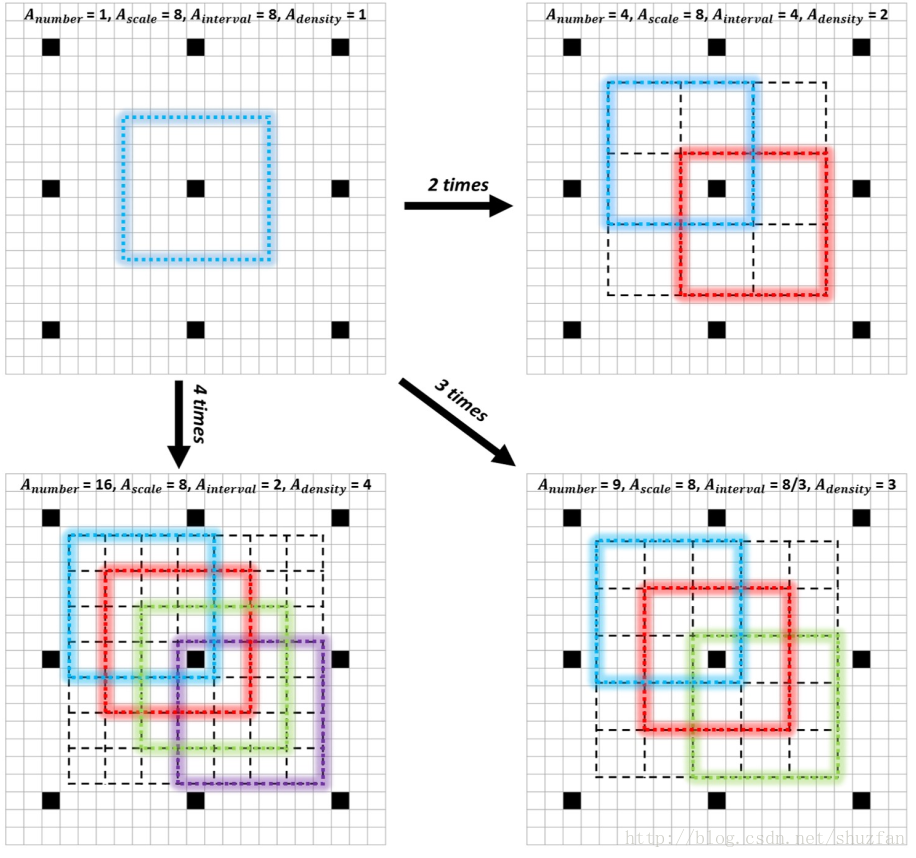
(3)Anchor densification strategy
SSD和Faster R-CNN此类方法对小目标效果不好,一定程度上是因为小目标所能对应的anchor比较少,导致训练不足。
下图是本文网络三个分支默认anchor的大小,以及每个分支对应的spatial stride。
我们可以据此定义anchor密度为(anchor大小 / stride)。 显然,第一个分支的一些anchor密度不足。这也是为什么小目标检测效果不佳的重要原因。

为了anchor密度均衡,可以对密度不足的anchor以中心进行偏移加倍,如下图所示:
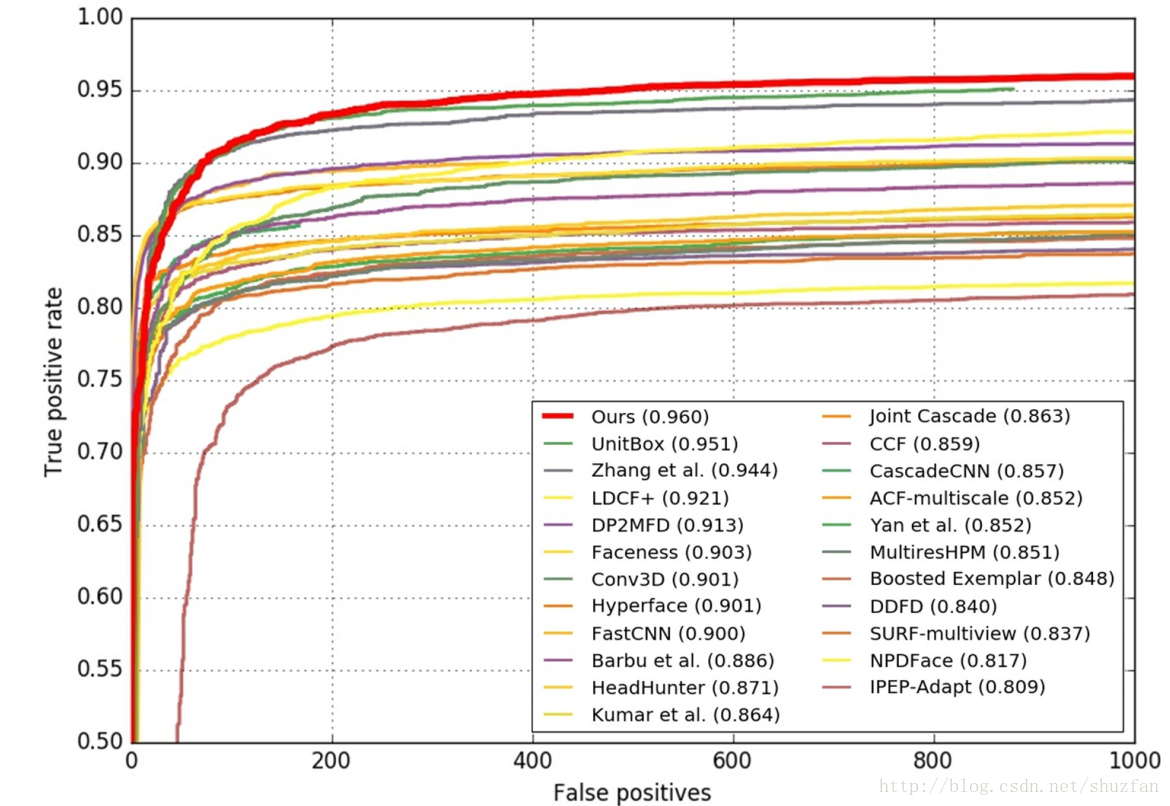
3. 实验结果
FDDB上的测试结果:
CPU速度测试:(这个CPU硬件性能有点好)

ScaleFace
文章链接: 《Face Detection through Scale-Friendly Deep Convolutional Networks》
1. 方法介绍
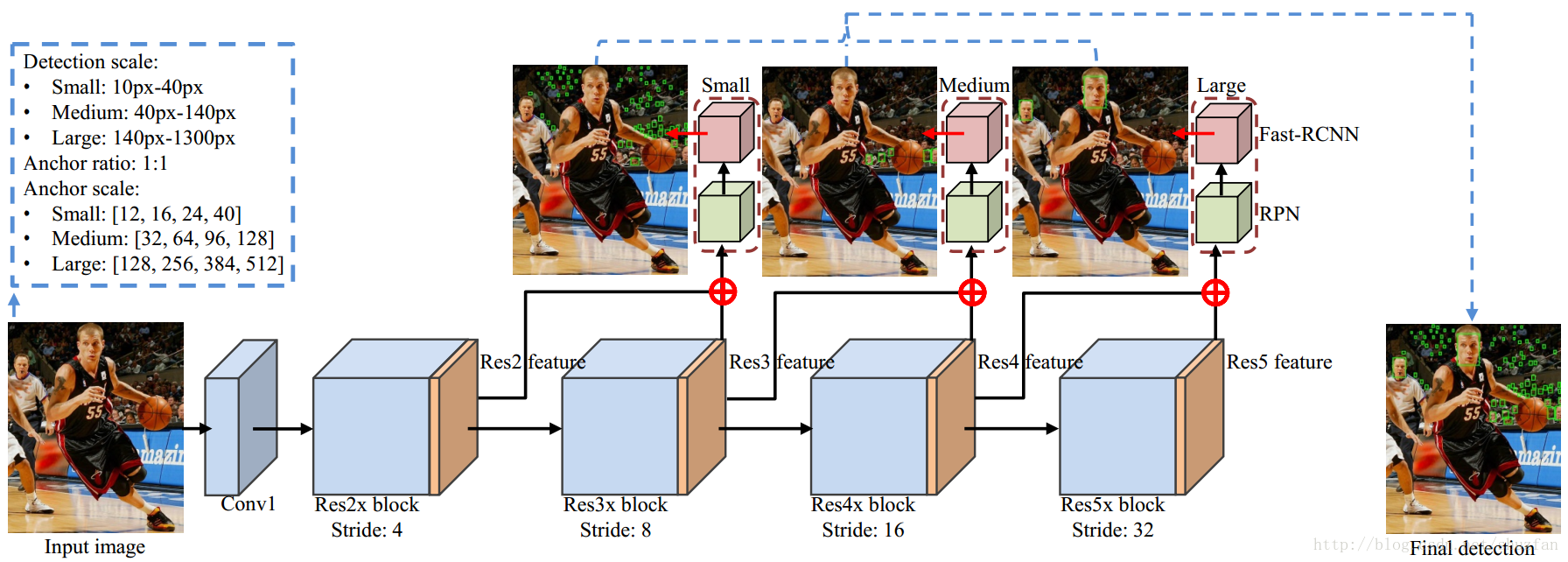
如上图,采用ResNet网络,输入单张图片。 在网络不同阶段引出分支,然后后接RPN和Fast R-CNN。 共有3个分支,每个分支只负责检测对应范围的人脸。
2. 要点介绍
(1)网络结构与检测目标尺度的关系
文章做了下面的对比实验:使用不同层级的特征检测指定尺度范围的人脸。
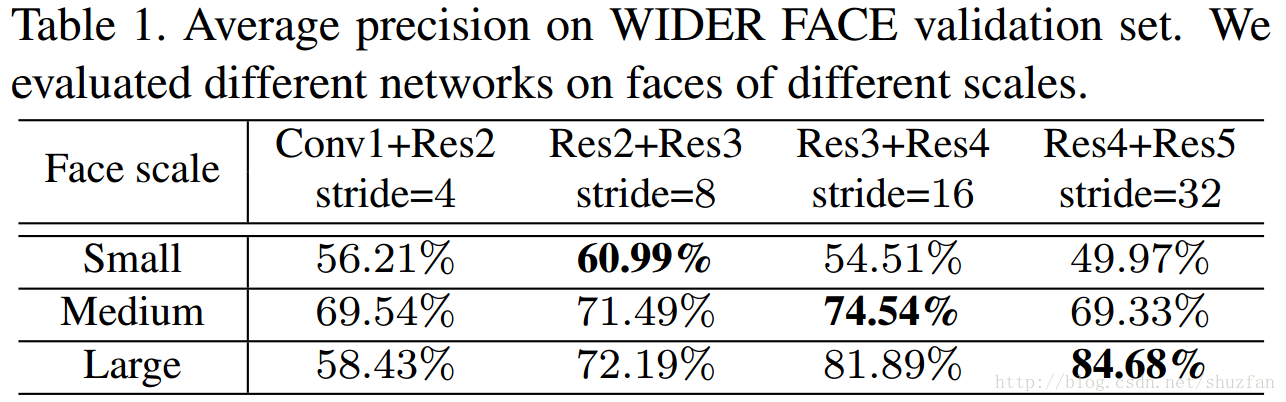
结论:不同层级的特征适用于检测不同尺度的人脸。 这一点其实很好理解,我们可以从网络自带的空间分辨率上去探讨这件事。 网络后期,经过多次spatial pooling,每一个输出都将和原图一块更大的ROI区域有关,因此更适宜检测大目标。
(2)如何划分人脸尺度范围
人脸尺度范围的划分需要结合网络结构,然后,通过实验确定。
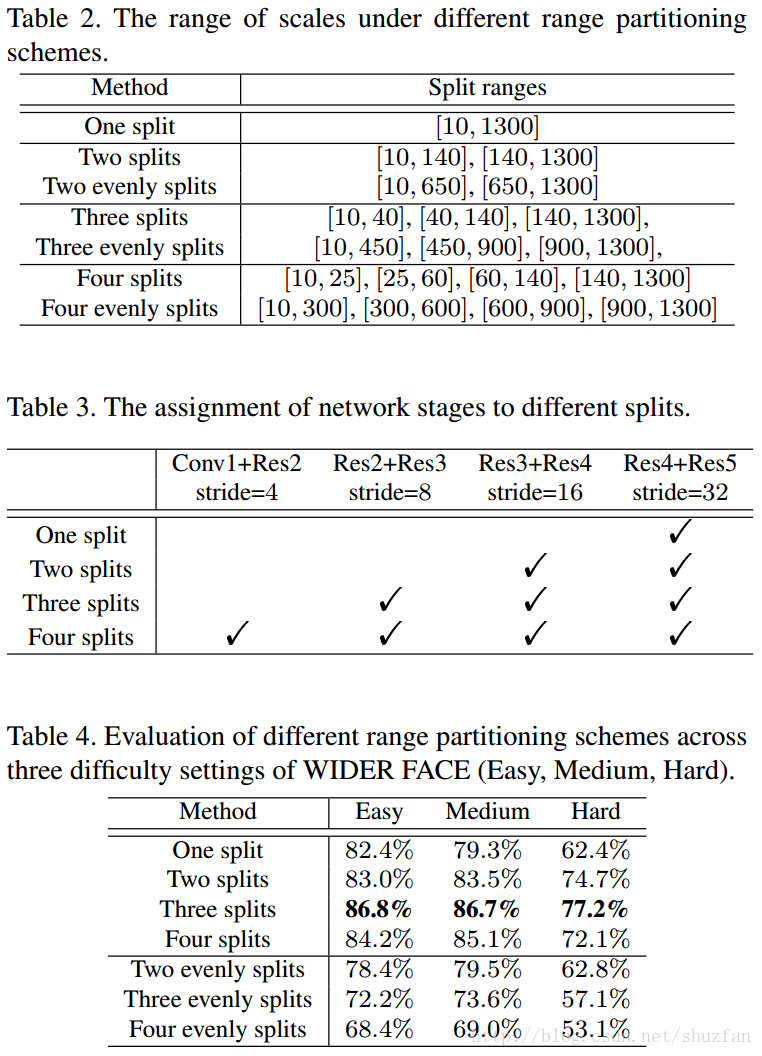
因此,最终划分为3个分组: [10,40],[40,140],[140,1300][10,40],[40,140],[140,1300]
(3)如何训练
这也是本文方法和SSD的一个重要不同,即针对不同分组只用对应尺度的样本进行训练。
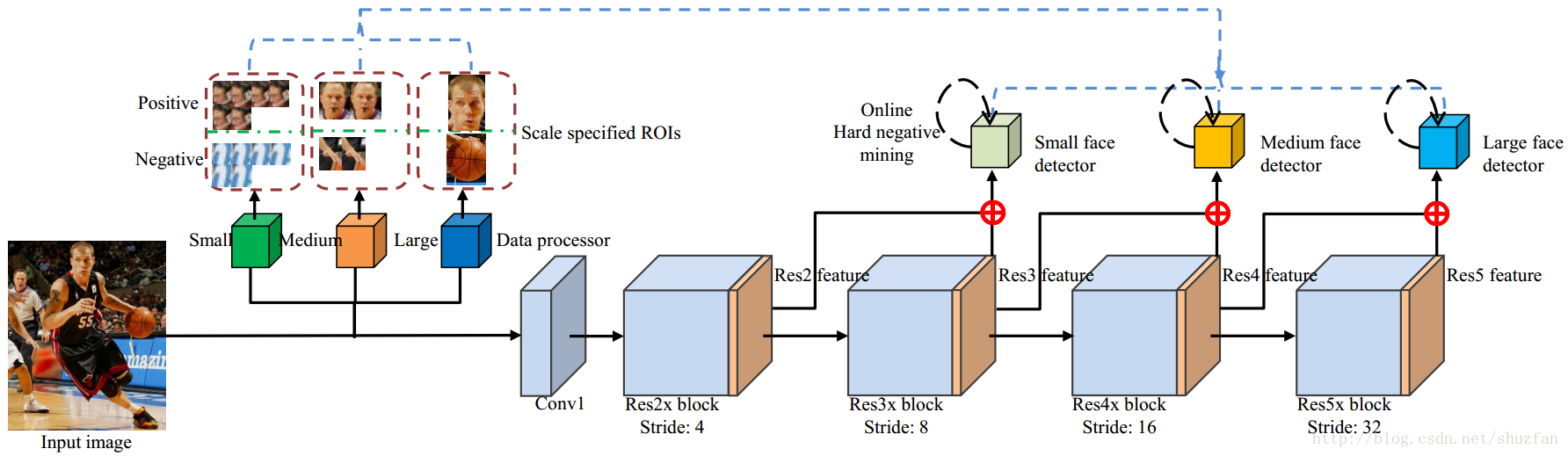
- (1) 每个分支只处理对应尺度的样本,其他样本直接忽略;
- (2) 输入图像最长边限定为小于等于1300;
- (3) IOU大于0.5认为是正样本,IOU处于 [0,0.1] 和 [0.1,0.3]的负样本按1:1选用;
- (4)训练时proposal保留2000,测试时保留500。
3. 实验结果
速度一般偏低,性能中上偏高。
在FDDB上的指标:
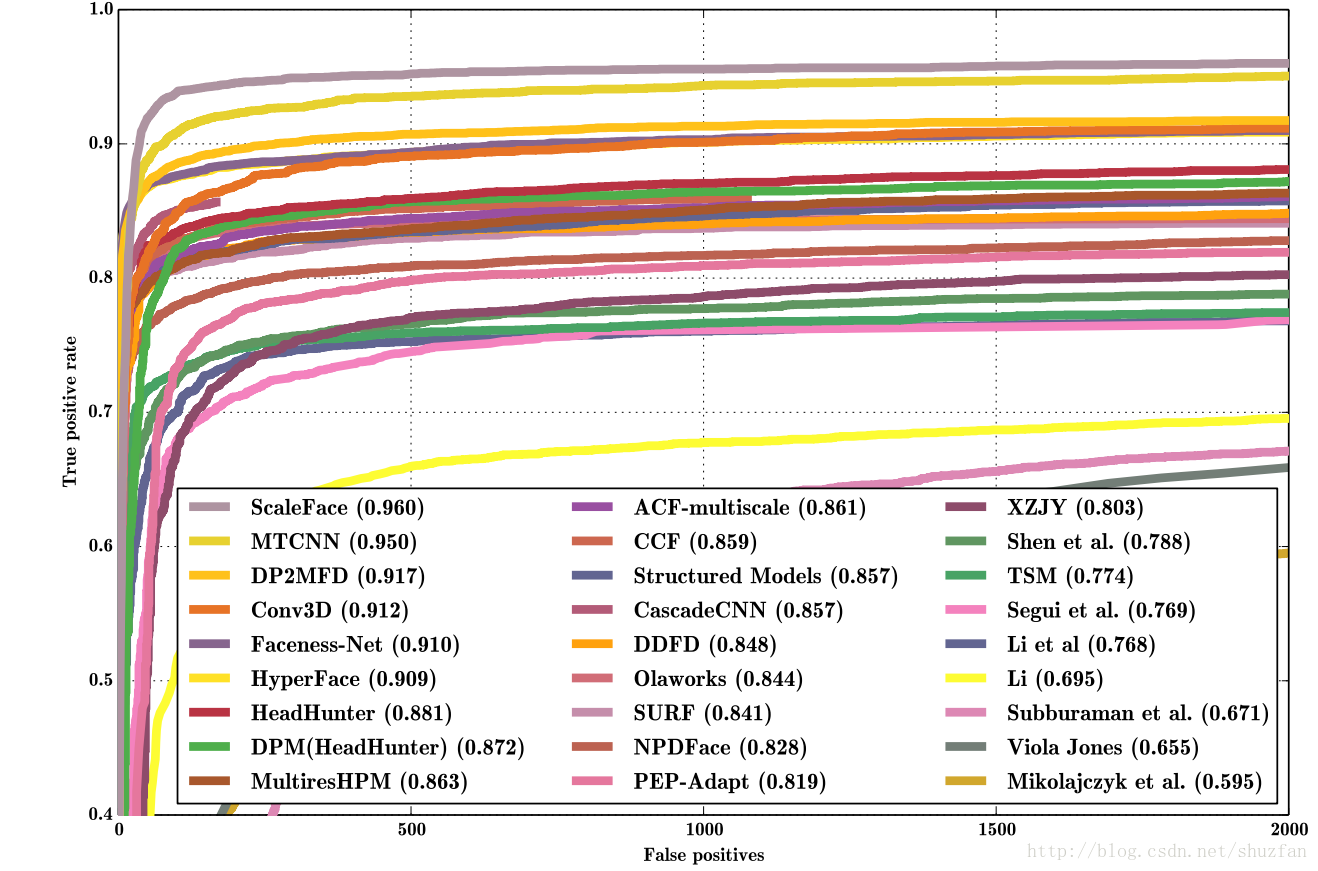
在Wider Face 上的指标:
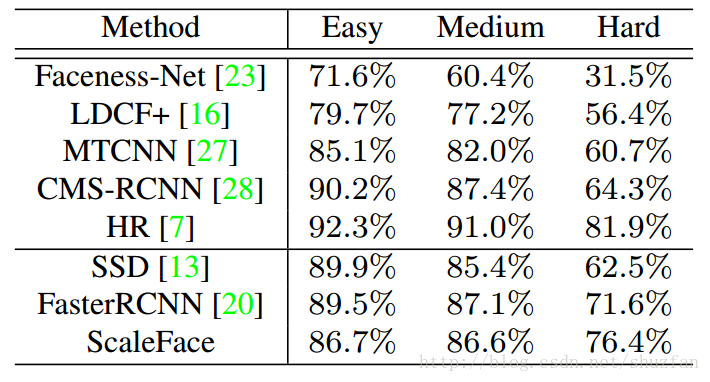
速度测试:
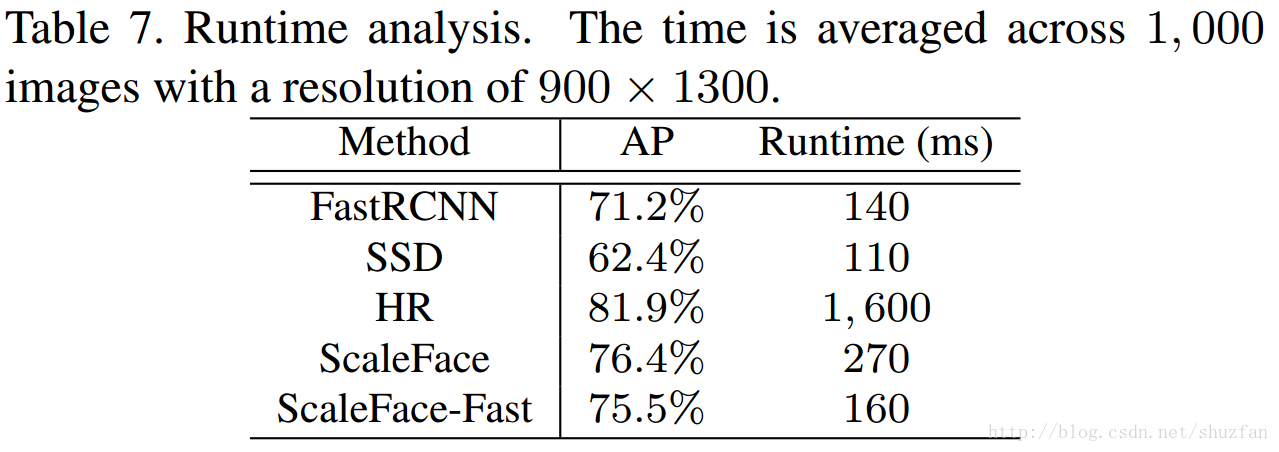
PyramidBox
论文:PyramidBox - X. Tang, Daniel K. Du, Z. He, J. Liu PyramidBox: A Context-assisted Single Shot Face Detector. arXiv preprint arXiv:1803.07737, 2018
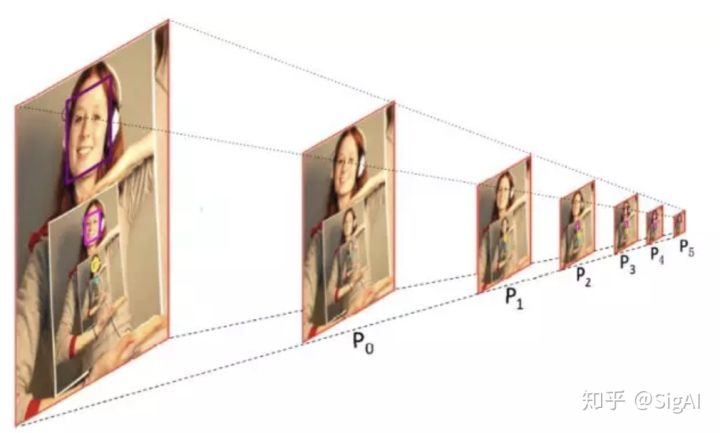
这张图又出现了!!!这一次是百度的“PyramidBox”跑出来的结果。880个人脸!!

PyramidBox从论文看主要是已有技术的组合应用,但是作者对不同技术有自己很好的理解,所以能组合的很有效,把性能刷的非常高。
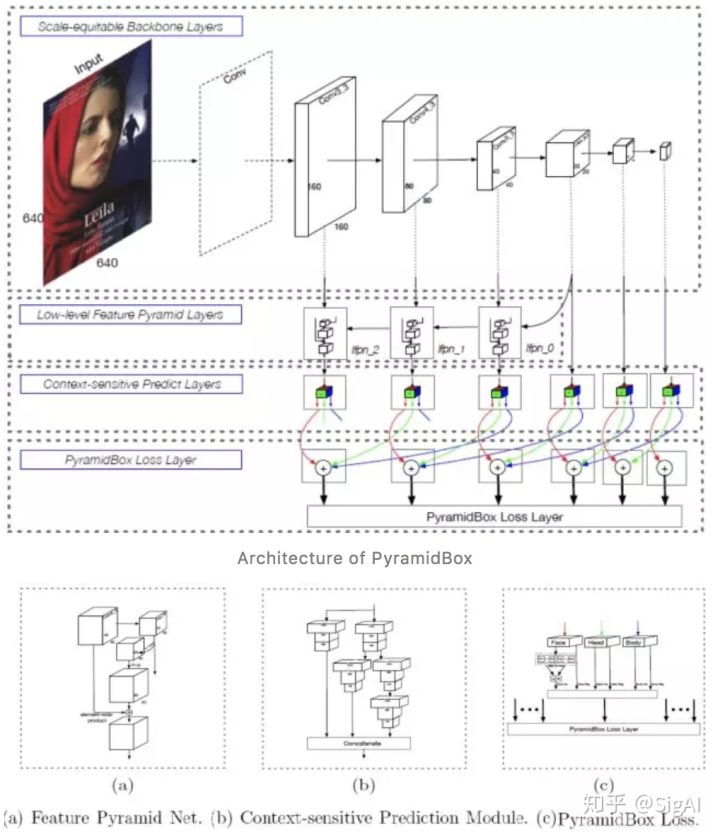
Architecture of PyramidBox
针对之前方法对上下文信息的利用不够充分的问题,作者提出了自己的优化方案:
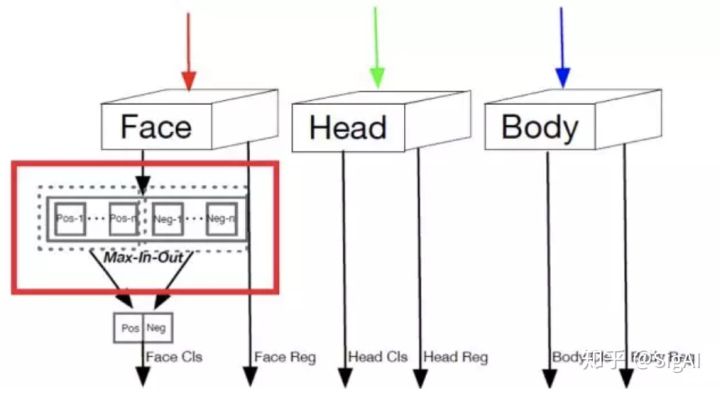
1. 提出了一种基于 anchor 的上下文信息辅助方法PyramidAnchors,从而可以引入监督信息来学习较小的、模糊的和部分遮挡的人脸的上下文特征(下图中紫色的人脸框为例可以看到P3,P4,P5的层中框选的区域分别对应face、head、body)。
2. 设计了低层特征金字塔网络 ( Low-level Feature
Pyramid Networks ) 来更好地融合上下文特征和面部特征,该方法在一次前向过程中(in a single shot)可以很好地处理不同尺度的人脸。
3. 文中提出了一种上下文敏感的预测模块,该模块由一个混合网络结构和max-in-out层组成,该模块可以从融合特征中学习到更准确的定位信息和分类信息(文中对正样本和负样本都采用了该策略,针对不同层级的预测模块为了提高召回率对正负样本设置了不同的参数)。max-in-out参考的maxout激活函数来自GAN模型发明人Ian J,Goodfellow,它对上一层的多个feature map跨通道取最大值作为输出,在cifar10和cifar100上相较于ReLU取得了更好的效果。
4. 文中提出了尺度敏感的Data-anchor-采样策略,改变训练样本的分布,重点关注了较小的人脸。














 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









