






前言
This chapter is mainly about the article, which mainly tells about the application of CNN and LSTM models and their combination models in forecasting storm surge levels.Through data comparison, it is found that these three models are far superior to other models in accuracy. Secondly, I learn the specific process of forward propagation and back propagation of CNN. This part mainly learns how the convolution layer updates parameters.
本章主要阅读文章,这个文章主要讲述了作者将CNN和LSTM模型以及两者的组合模型应用在预测风暴潮水平中,通过数据对比发现这三个模型在准确率上要远优于其他模型。其次,学习了CNN前向传播和反向传播的具体过程。这部分主要学习卷积层是如何更新参数。
文献阅读
题目:Multi-step ahead short-term predictions of storm surge level using CNN and LSTM network
作者:Bao Wang, Shichao Liu, Bin Wang, Wenzhou Wu, Jiechen Wang, Dingtao Shen
名词:storm surge 风暴潮,SL 风暴潮水位,ROI regions of interest
摘要
风暴潮是最危险的海洋灾难之一,其特点是高变异性和不确定性。SL 预测在降低洪水风险和保护沿海地区人民生命安全和海洋活动中有关键作用。目前,SL预测的主要方法有经验预测(过度依赖个人经验)和数值建模(成本高、耗时长)。近年来,CNN和LSTM模型在时间序列预测中有明显的优越性和可靠性,但是很少用在风暴潮或海平面的预测中。CNN主要擅长在原始信号中收集显著特征,LSTM主要擅长学习时间特征。本研究中将应用CNN和LSTM模型及两个顺序组合LSTM-CNN和CNN-LSTM,以1h,2h,4h,6h为提前期进行multi-step-ahead short-term SL forecasts。
研究过程:
1.根据不同区域的SL分布生成样本数据
2.构建并训练SVR\MLP\CNN\LSTM\LSTM-CNN\CNN-LSTM等SL预测模型
3.通过不同度量指标和统计分析衡量模型的优越性证明CNN和LSTM在风暴潮预测中的适用性。
方法
基于统计的样本生成
神经网络模型中训练样本的分布应涵盖实际可能出现的各种情况。在没有台风的情况下,SL相对低,如果将有效时间内的所有时间序列数据都作为模型的输入,台风引起的潮汐变化所占的比例非常小,训练数据集会有很高的偏差,这会导致在台风过程中预测风暴潮水平的模型性能降低。但如果只用台风经过前后一段时间的数据,在无法确定台风过境的情况下就无法做出准确的预测。折中方法是在站点周围划定一个ROI,选择台风进入该区域后的某段时间作为样本,不管台风是否会经过站点。样本生成转化为一下两个问题:1.ROI的大小和位置;2.台风进入ROI后的LTP(the length of time period 时间段的长度)
案例研究
本研究使用特征输入的数量为24,构建了六个模型进行比较,模型的数据组织和网络结构如下图,所有六个模型的原始输入都是三位张量(none,24,3),第一维是样本数量,二维是时间序列的长度,三维是变量的数量(SL,U10,V10)。
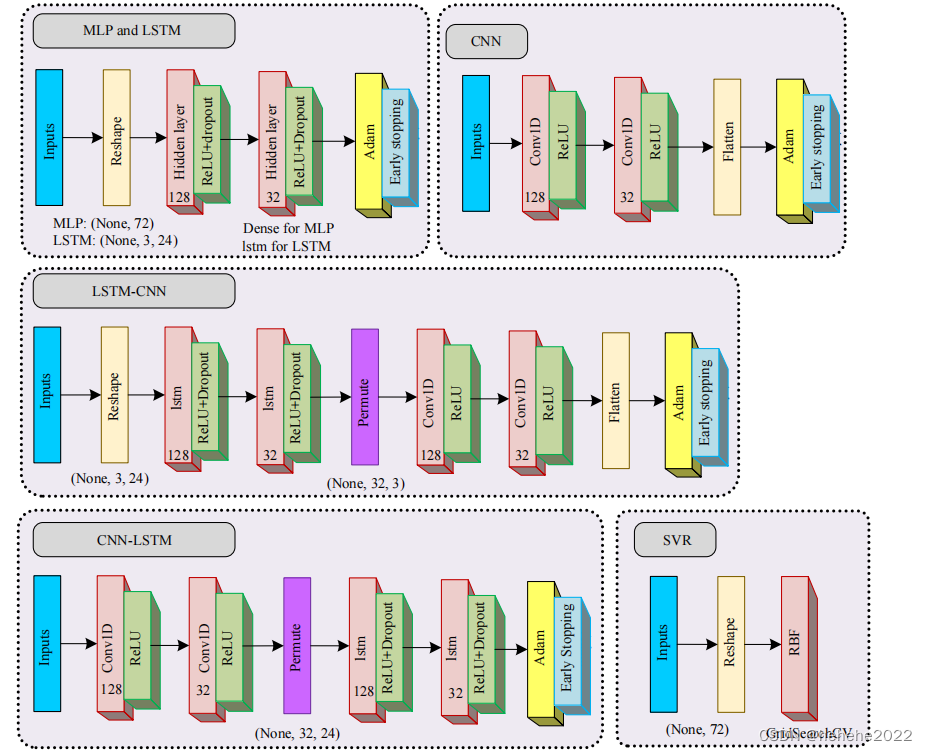
结果讨论
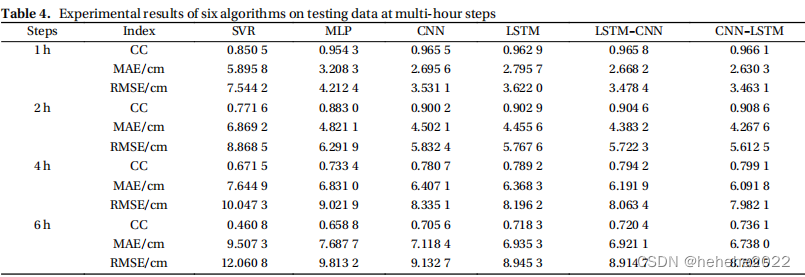
上表总结了六种算法的结果,观察到CNN和LSTM的表现由于SVR和MLP,并且CNN和LSTM的组合比单独的结果更准确。实验表明,CNN和LSTM模型在预测精度方面优于SVR和MLP模型,CNN和LSTM的组合使性能提高。
CNN学习
感受野
问题:如果堆叠3个3X3的卷积层,并且保持滑动窗口的步长为1,其感受野就是7X7 的了,这跟一个使用7x7 卷积核的结果是一样的,那为什么非要堆叠3个小卷积呢?
假设输入大小为hwc,并且都使用c个卷积核(得到c个特征图),计算各自所需要的参数:
一个7 * 7: c*7 *7 * c=49 *c^2
三个3 * 3:3c * 3 *3 * c=27 *c^2
结论:堆叠小的卷积核所需要的参数更少一些,并且卷积过程越多,特征提取的会越细致,加入的非线性变换也会随之增加,还不会增加权重参数个数。
CNN的前向传播过程
1.从输入到卷积层
前向传播的过程可以表示为:
a2 = σ(z2)=σ(a1 * W2 +b2)
σ为ReLU激活函数,*代表卷积操作,W为卷积核的参数,b为偏置。
将上面的公式推广到一般情况的话表示为:
al = σ(zl)=σ(al-1 * Wl +bl)
其中,上标 l 代表当前为l层,*代表卷积操作,W为卷积核的参数,b为偏置,al-1 代表上一层的输出。
卷积的具体操作如下所示:
假设输入图片的大小为7x7x3,filter卷积核的大小为3x3x3,有两个卷积核;在图片左边的三张x图分别代表了图片三个通道的值,一个filter也有三个通道,每个分别和输入图片对应的通道做卷积运算,将三个卷积结果加起来,再加上偏置b0的值就得到输出结果的第一个特征图;输入再与第二个卷积核做与前面类似的操作,得到第二个特征图,两个特征图堆叠在一起得到结果3x3x2。卷积核的个数与得到的特征图个数相关,每个卷积核的的数值是不相同的,要分别进行各自的参数更新。
卷积参数共享:一个卷积核与图片中的不同块进行特征提取的时候,卷积核的值不变,减少了参数量。
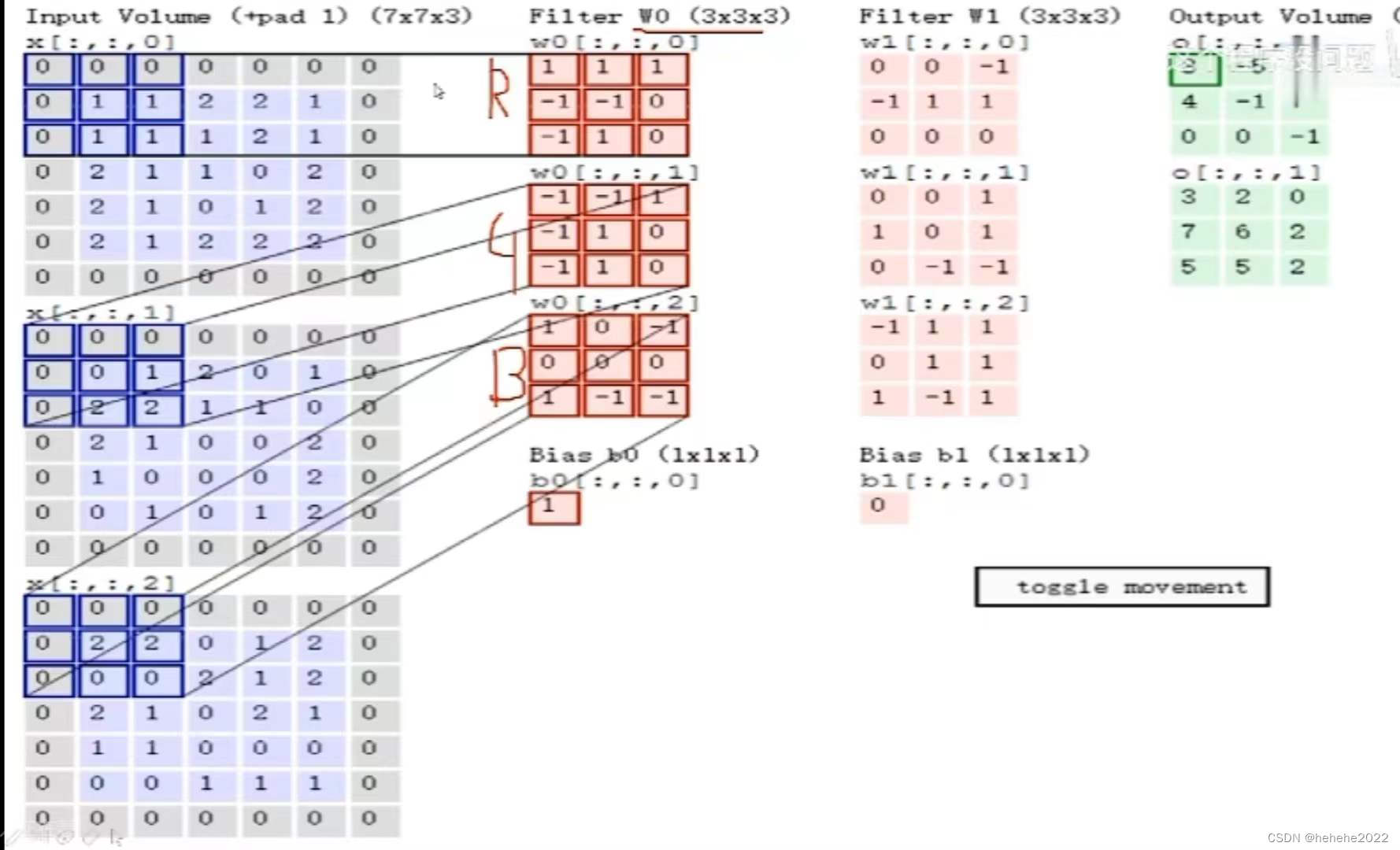
上面进行了卷积层操作,卷积层虽然可以显著减少网络中的连接的数量,但特征映射组的神经元个数没有显著减少。如果在后面接一个分类器,分类器的输入维度依然会很高,容易出现拟合的现象。所以要在卷积层之后加上一个池化层,从而降低特征维数,避免拟合。
常用的池化方法为最大池化 Max pooling,假设池化层的输入特征映射组为Χ∈RMXNXD,其中每一个特征映射Xd∈RMXN,1<d<D,将其划分为很多区域Rdm,n,这些区域可以重叠也可以不重叠,池化是对每个区域进行下采样得到一个值,作为这个区域的概括。
最大池化:对于一个区域Rdm,n,选择这个区域内所有神经元的最大活性值作为这个区域的代表,表示为:ydm,n=max xi,其中xi为区域Rdm,n内每个神经元的活性值。
经过卷积池化等一系列操作进行特征提取,得到多个特征图,然而我们最终的目的是分类,说出图片属于什么类别,所以就需要一个类似分类器的东西,全连接层在整个卷积神经网络中起到了分类器的作用,这中间我们要将这些特征图转换成向量序列的形式,即进行flatten操作,才能与全连接层一一对应,然后用一个全连接层输出最后的结果,分类任务,一般会利用softmax激活函数输出相应的分类结果。经过全连接层,我们获得K个范围在(-∞,+∞)的值,为了得到属于每个类别的概率,通过指数将值映射到(0,+∞),再归一化到(0,1)之间,公式为
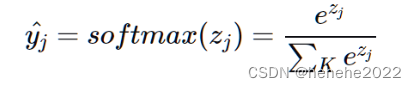
前面计算出了输出,还需要用损失函数来计算预测值与真实值之间的差距,在分类任务中,常用的损失函数是交叉熵函数CrossEntropyLoss,
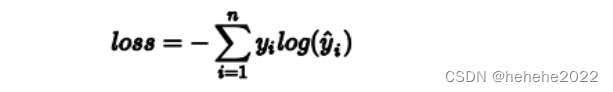
y为真实值,yhat为预测值。
卷积层的反向传播
回顾之前DNN的反向传播的核心公式:
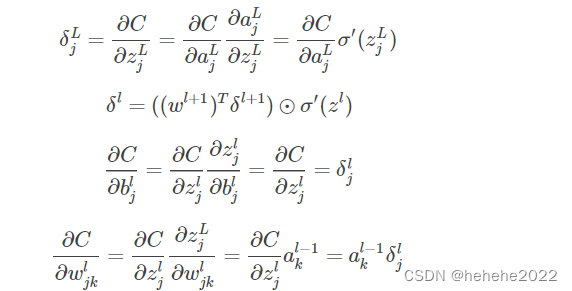
求出loss对偏置和权重的导数就能够用梯度下降法对参数进行更新,训练神经网络。
卷积层的梯度求取举例说明:
假设第l层的激活输出是一个3X3的矩阵,第L+1层卷积核W是一个2x2的矩阵,步长为1,输出Zl+1是一个2X2的矩阵,为了简化计算b=0,公式为:

矩阵表达为:
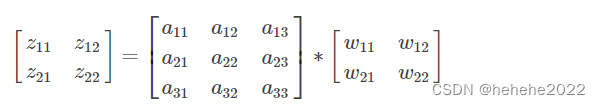
利用卷积展开为:
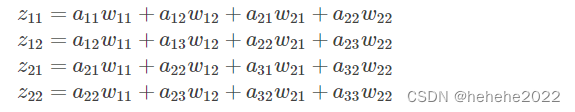
损失函数对al求导:
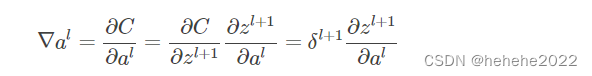
假设
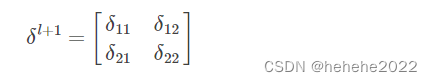
a11只和Z11有关,所以
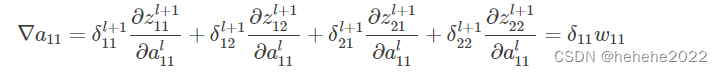
同理得到其他8个:
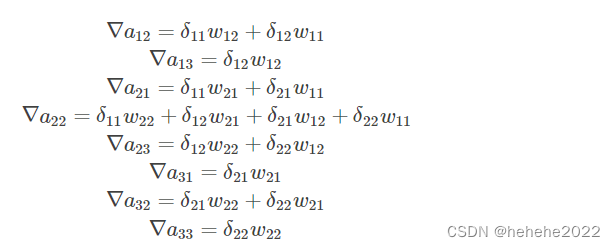
上面的9个式子用矩阵卷积的形式统一表示为:
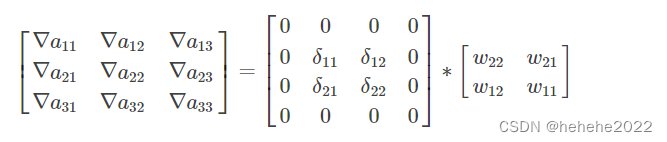
为了符合梯度计算,在误差矩阵周围填充0,将卷积核翻转和反向传播的梯度误差进行卷积,得到前一次的梯度误差,公式表示为:
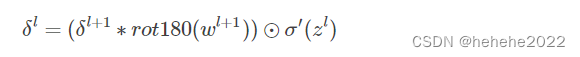
损失函数对权重求导的公式如下,最后梯度下降对参数进行更新。
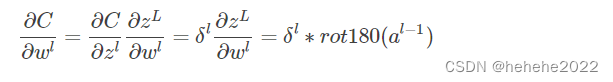
1、卷积了以后会得到啥,这个得到的东西能不能解释;
卷积层的作用就是进行特征提取,最终会得到特征图像。
2、池化的作用是啥,可以替换没有;
增大感受野(卷积神经网络每一层的输出的特征图上的像素点映射会输入图像上的区域大小);对特征进行压缩减少参数量;增大平移不变性,希望目标有些许的位置移动还能得到相同的结果,因为池化抽象了区域特征而不关心位置,所以增大了平移不变性。 池化层可以用卷积层替换。
3、池化卷积池化卷积的叠加到底会有什么效果;
池化层主要是用于压缩数据和参数量,如果是先池化后卷积的话,相比于原来的卷积池化,参数量可能会减少。
4、flattening宽度多少合适;
flattening主要的作用是将输入压平,把多维的输入一维化。
5、全连接能否dropout;
深度学习中, 当参数过多时, 模型容易产生过拟合现象。dropout 能够避免过拟合,往往会在全连接层这类参数比较多的层中使用dropout。
6、最终分类多少与前面各层有没有对应关系。
最终分类与前面的卷积和池化层的关系不是很大,卷积池化主要是进行特征提取,而最终的分类主要与全连接层有关系。
总结
本周在上周的基础之上进一步学习了卷积神经网络,主要学习了与DNN相比,CNN的卷积层在反向传播的时候是如何更新参数的。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









