







VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild 零样本语音编辑和文本到语音
2024.3.25
Abstract
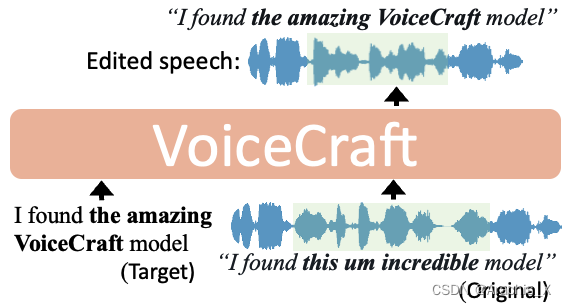
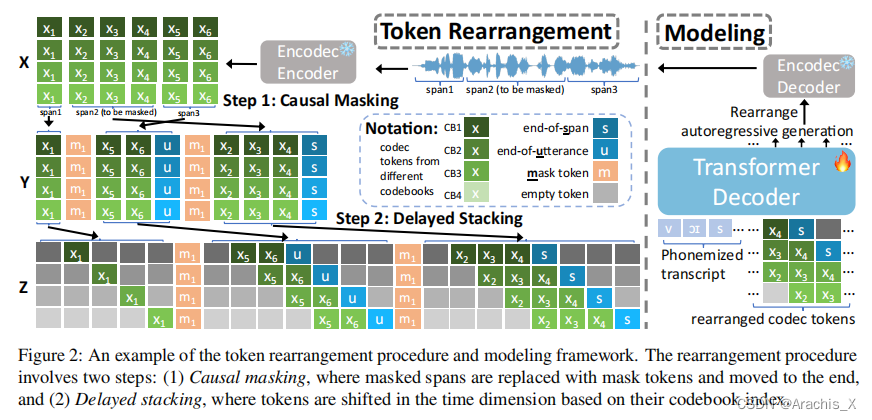
We introduce VoiceCraft, a token infilling neural codec language model, that achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on audiobooks, internet videos, and podcasts. VoiceCraft employs a Transformer decoder architecture and introduces a token rearrangement procedure that combines causal masking and delayed stacking to enable generation within an existing sequence. On speech editing tasks, VoiceCraft produces edited speech that is nearly indistinguishable from unedited recordings in terms of naturalness, as evaluated by humans; for zero-shot TTS, our model outperforms prior SotA models including VALLE and the popular commercial model XTTS-v2. Crucially, the models are evaluated on challenging and realistic datasets, that consist of diverse accents, speaking styles, recording conditions, and background noise and music, and our model performs consistently well compared to other models and real recordings. In particular, for speech editing evaluation, we introduce a high quality, challenging, and realistic dataset named RealEdit. We encourage readers to listen to the demos at https://jasonppy.github.io/VoiceCraft_web.
我们介绍的 VoiceCraft 是一种标记填充神经编解码语言模型,它在有声读物、网络视频和播客的语音编辑和零样本文本到语音(TTS)方面都达到了最先进的性能。
VoiceCraft 采用Transformer解码器架构,并引入了一种标记重新排列程序,该程序结合了因果掩蔽和延迟堆叠技术,可在现有序列中生成语音。
-
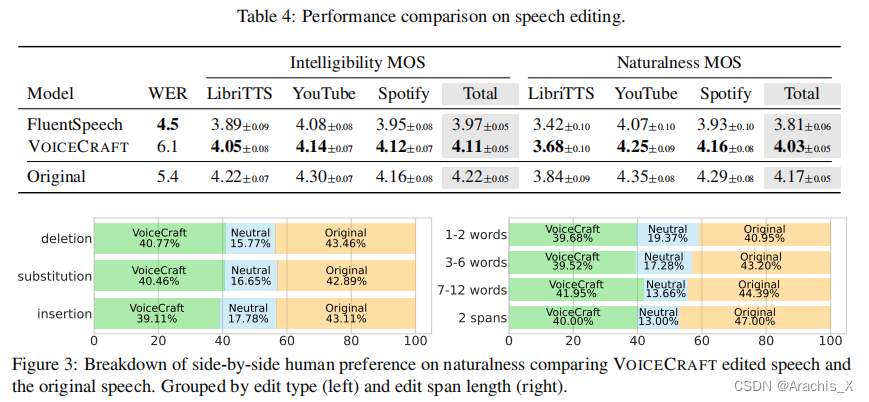
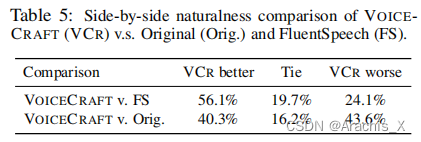
在语音编辑任务中,VoiceCraft 生成的编辑语音在自然度方面与未经编辑的录音几乎没有区别,这是由人类进行评估的;
-
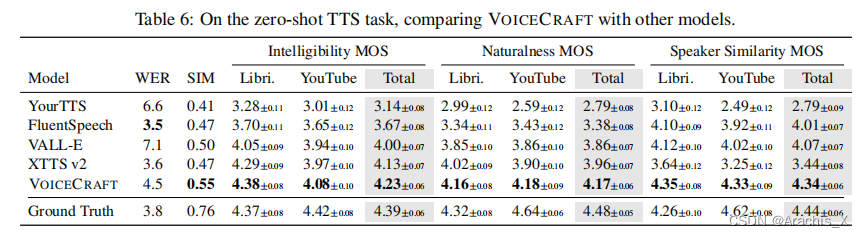
在零样本 TTS方面,我们的模型优于先前的 SotA 模型,包括 VALLE 和流行的商业模型 XTTS-v2。
-
最重要的是,我们在具有挑战性的真实数据集上对模型进行了评估,这些数据集包含不同的口音、说话风格、录音条件以及背景噪音和音乐,与其他模型和真实录音相比,我们的模型一直表现出色。
-
特别是在语音编辑评估方面,我们引入了一个名为 RealEdit 的高质量、高难度和真实的数据集。
我们鼓励读者在 https://jasonppy.github.io/VoiceCraft_web 上收听演示。
Results















 100
100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









