









MotionCtrl: A Unified and Flexible Motion Controller for Video Generation
-
这篇论文是基于VideoCrafter的,而VideoCrafter是基于LVDM的
-
关于LVDM可以看https://blog.csdn.net/Are_you_ready/article/details/136615853
-
2023年12月6日发表在arxiv
-
这篇论文讨论了一种先进的技术,用于控制视频生成中的相机和物体运动。主要内容包括:
- 综合框架:论文提出了一个统一且灵活的运动控制框架,用于视频内容生成。
- 控制功能:该框架能够控制相机和物体的运动,包括方向、速度和轨迹。
- 技术应用:适用于各种视频制作场景,如电影制作、游戏开发等。
Abstract
- 在视频中,运动主要包括由相机运动引起的相机运动和由物体运动引起的物体运动。对这两种运动的精确控制对于视频生成至关重要。然而,现有的工作要么主要关注一种类型的运动,要么没有明确地区分两者,从而限制了其控制能力和多样性。
- 因此,本文提出了一种统一的、灵活的运动控制器MotionCtrl,用于视频生成,旨在有效且独立地控制相机和物体运动
- 我们仔细设计了MotionCtrl的架构和训练策略,同时考虑了相机运动、物体运动和不完善训练数据的固有属性
- 与以前的方法相比,MotionCtrl具有以下三个主要优点:
- 它可以有效且独立地控制相机运动和物体运动,从而实现更精细的运动控制,并促进两种类型运动的灵活和多样化组合
- 其运动条件由相机姿态和轨迹确定,这些姿态和轨迹与外观无关,并且对生成视频中物体的外观或形状的影响最小
- 它是一种相对通用的模型,一旦训练过,就可以适应各种相机姿态和轨迹,即MotionCtrl可以控制各种摄像机运动和轨迹,无需对每个摄像机或对象运动进行精细调整。
Introduction
- 在视频中,主要有两种类型的运动:由相机运动引起的全局运动和由物体运动引起的局部运动
- 相机运动是指整个场景在时间维度上的全局变换,通常通过一段时间内的相机姿态序列来表示。
- 相比之下,物体运动涉及场景中特定物体的时间运动,通常表示为与物体相关联的一组像素的轨迹
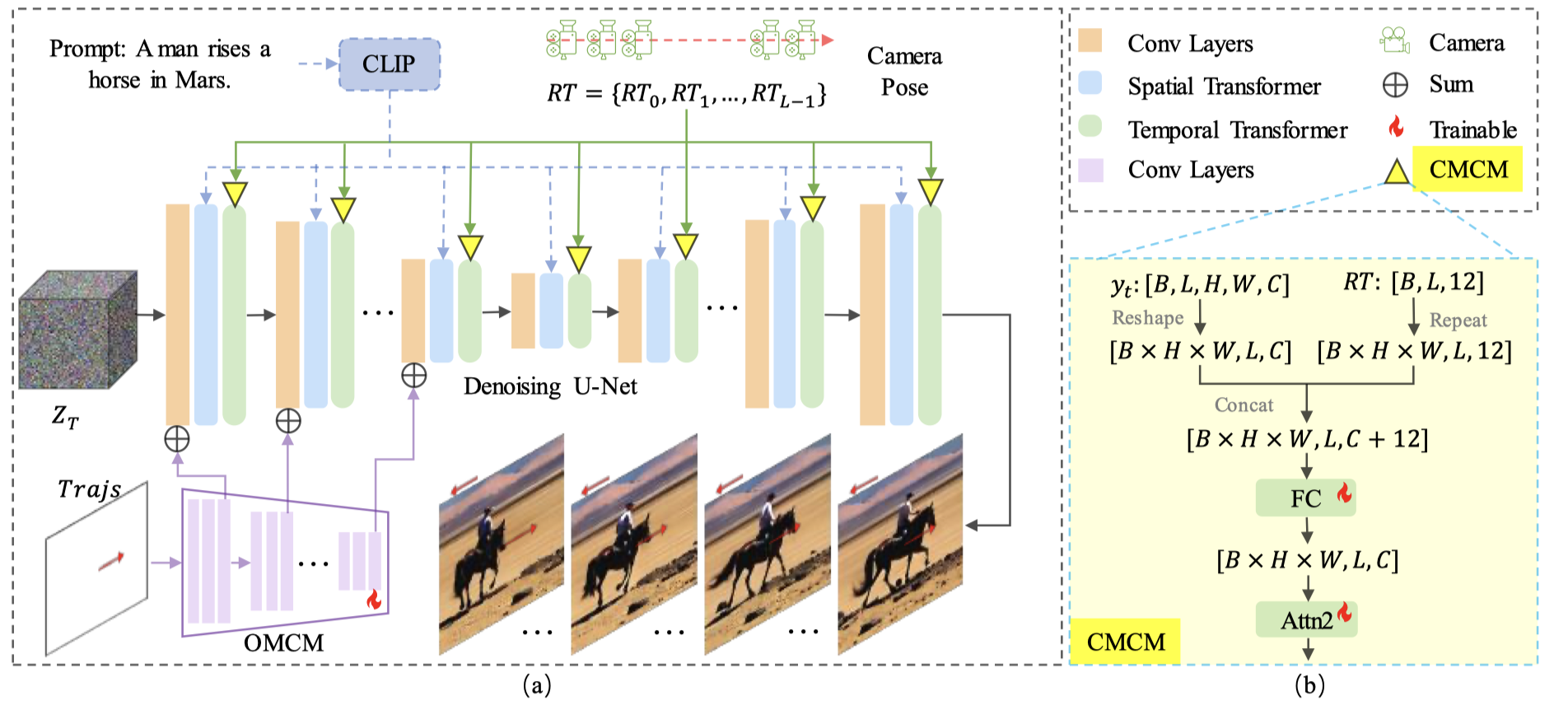
MotionCtrl的两个模块
- 首先,我们根据相机运动和物体运动的属性,构建了MotionCtrl的两个模块:相机运动控制模块(CMCM–Camera Motion Control Module)和物体运动控制模块(OMCM–Object Motion Control Module)。这两个模块与现有的视频生成模型协同工作
- 在这项工作中,我们采用了VideoCrafter1 [5],这是LVDM [9]的改进版本,作为视频生成模型,并在整篇论文中将其称为LVDM(VideoCrafter[5],该模型在结构上类似于LVDM[9]。为了清晰起见,我们将本文中使用的视频模型称为LVDM)
- CMCM:通过其时间变换器将一系列相机姿态按时间顺序融合到LVDM中,使生成的视频的全球运动符合给定的相机姿态
- OMCM:将物体运动的信息空间融合到LVDM的卷积层中,以指示每个生成帧中物体的空间位置
训练MotionCtrl
- 训练MotionCtrl需要带有完整注释的视频片段,包括标题、相机姿态和物体运动轨迹,这些目前不可用且难以构建
- 我们可以独立训练CMCM和OMCM这两个模块
- 从而将数据集简化为一个具有标题和相机姿态注释的视频数据集。我们首先引入了一个增强版的Realestate10k数据集,该数据集利用Blip2 [13]为Realestate10k [33]中的每个样本生成标题。这个具有标题和相机姿态注释的视频数据集被用来训练CMCM模块
- 以及另一个具有标题和物体运动轨迹注释的视频数据集。我们使用ParticleSfM [31]中提出的运动分割算法合成的物体运动轨迹来增强WebVid [3]中的视频。因此,我们可以获得一个增强版的WebVid数据集来训练OMCM模块
- 由于独立的适配器式训练策略和冻结的预训练LVDM,我们可以使用相机和物体运动中的一种或结合两种运动来控制视频生成,从而实现精细和灵活的运动控制。
贡献
- 本文的主要贡献可以总结如下:
- 我们引入了MotionCtrl,这是一种统一且灵活的视频生成运动控制器,旨在独立且有效地控制生成视频中的相机运动和物体运动,实现更精细和多样化的运动控制。
- 我们根据相机运动、物体运动的固有属性以及不完美的训练数据,精心设计了MotionCtrl的架构和训练策略,有效地实现了视频生成中的精细运动控制。
- 我们进行了广泛的实验,从定性和定量两个方面证明了MotionCtrl优于之前的相关方法。
相关工作
-
一些努力旨在实现更通用的运动控制。例如,VideoComposer [25]通过额外的运动向量引入了运动控制,DragNUWA [28]提出了在初始图像、提供的轨迹和文本提示的条件下的视频生成。然而,这些方法中的运动控制相对广泛,无法在视频中精细地分离相机和物体运动。
-
与这些工作不同,我们提出了MotionCtrl,这是一个统一且灵活的运动控制器,可以使用相机姿态和物体轨迹或结合这两种指导来控制生成的视频的运动。它为视频生成提供了更精细和灵活的控制。
方法
- 考虑到相机运动的全局属性和物体运动的局部属性,CMCM与LVDM中的时间变换器进行交互,而OMCM与LVDM中的卷积层进行空间合作
- 此外,我们采用多个训练步骤使MotionCtrl适应缺乏高质量视频剪辑、标题、摄像机姿态和物体运动轨迹的训练数据的情况
CMCM
- 将CMCM模块插入到Temporal Transformer中,只插入到它的后两个全连接层和注意力层,这应该是因为相机运动和时间密切相关

OMCM
- 将OMCM模块插入到卷积层,这应该是因为它与物体密切相关
训练策略与数据集构建
- 为了通过文本提示生成视频并实现相机和物体运动的控制,训练数据集中的视频剪辑必须包含标题、摄像机姿态和物体运动轨迹的注释,然而,目前没有这样的综合细节的数据集可用
- 为了解决这一挑战,我们提出了多步骤训练策略,并使用针对其特定运动控制需求的独特增广数据集对所提出的相机运动控制模块(CMCM)和物体运动控制模块(OMCM)进行训练。
- 多步骤训练也就是因为一步训练的数据集没有,就先训练CMCM,训练完后,将其冻结,然后训练OMCM
CMCM
- 学习相机运动控制模块(CMCM)需要一个包含带有标题、摄像机姿态但不包含物体运动轨迹的视频剪辑的训练数据集
- 我们选择使用Realestate10K数据集 [33],在移除了无效的视频链接后,提供了62,992个视频剪辑,并伴随着各种摄像机姿态
- 使用 这个数据集存在的两个问题:
- 数据集的场景多样性有限,主要来自房地产视频
- 它缺乏T2V模型所需的标题
- 第一个问题解决方案:
- 我们专门设计了CMCM模块,仅训练LVDM中的时间变换器的几个额外的MLP层和第二个自注意力模块,同时冻结所有其他参数,CMCM的训练主要集中在学习全局运动上,很少影响生成视频的内容
- 我们使用Blip2 [13],一个图像描述算法,为Realestate10K中的每个视频剪辑生成标题
- 使用 这个数据集存在的两个问题:
OMCM
- 学习物体运动控制模块(OMCM)需要一个包含相应标题和物体运动轨迹的视频剪辑的数据集
- 目前,还没有大规模的数据集将视频文本对与物体轨迹结合起来。为了解决这个问题,我们使用ParticleSfM [31]来生成物体运动轨迹,使用WebVid数据集 [3],该数据集广泛用于T2V生成
- 尽管ParticleSfM很有效,但它并不高效,需要大约2分钟来处理一个32帧的视频
- 为了解决密集轨迹的问题,我们使用从密集轨迹中采样的稀疏轨迹来训练OMCM。这些稀疏轨迹过于分散,不利于有效学习,因此我们使用高斯滤波器对其进行细化。
- 在训练过程中,我们从合成的轨迹中随机选择n∈[1, N]轨迹(其中N是每个视频的最大轨迹数)
- 在训练过程中,我们首先使用密集轨迹对OMCM进行训练,然后使用稀疏轨迹对其进行微调。
- 在这个训练阶段,我们采用了已经与CMCM进行微调的LVDM模型。我们只训练OMCM层,而整个基础模型和CMCM保持冻结
- 这种策略保证了OMCM在有限的数据集上增加了物体运动控制能力,同时最小化了对LVDM和CMCM的影响
实验
-
我们的MotionCtrl基于LVDM [9]和训练权重由VideoCraft1 [5]提供
- 它在分辨率为256 × 256的16帧序列上进行训练
- 我们将最大轨迹数N设置为8
- CMCM和OMCM都使用Adam优化器 [12]进行优化,批量大小为128,学习率为1×10 −4,在8个NVIDIA Tesla V100 GPU上进行训练
- CMCM需要大约50,000次迭代才能收敛。OMCM首先在密集轨迹上进行20,000次迭代训练,然后使用稀疏轨迹进行额外的20,000次微调。
-
我们将它与两种领先的方法进行了比较:AnimateDiff [8]和VideoComposer [25]
- AnimateDiff使用8个独立的LoRA [11]模型来控制视频中的8个基本相机运动,例如平移和缩放
- VideoComposer使用运动向量来操纵视频运动,没有区分摄像机和物体的运动
- 虽然DragNUWA [28]与我们的研究相关,但其代码未公开,因此无法进行直接比较
- 此外,DragNUWA仅通过从光学流中提取的轨迹来学习运动控制,无法精细地区分前景物体和背景的运动,限制了其精确控制摄像机和物体运动的能力
-
摄像机和物体运动的结合。MotionCtrl不仅可以在单个视频中独立控制摄像机和物体的运动,还可以对两者进行集成控制















 1228
1228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









