









这篇文章
在SVO系统中的"Relaxation Through Feature Alignment"部分使用的是一种特别的LK光流法:the inverse compositional Lucas-Kanade algorithm(逆向LK光流法)。该方法的论文可以在这里查看,对于整个论文的讲解可以参考这篇博客(感谢给位前辈)。这两个资料能够帮助每位博友理解各种光流法的原理。在这里就记录一下自己对光流法和逆向光流法的理解。
【转载声明】本篇文字均为原创,如转载请注明出处
光流法简介
光流法是根据光度不变性假设(同一空间点在各图像上的成像点的灰度值相同)实现,也就是下面的式子:
=I(W(x;p))......(1)")
式中T(x)表示参考图象中点x的像素灰度值。W表示关于x和p的一个函数,W(x;p)表示x点坐标经过变换(变换可以是纯平移或仿射)后的坐标。p是一个参数向量,用于构建相关的变换(构建的方法详见之前提到的两个参考资料)。I(.)表示当前图像中某点的像素灰度值。最终通过调整p的取值来使上述公式成立。
式(1)只针对一个点,但在实际中会考虑多个点对p的求解约束。因此一般的光流法求解的是下面这样的一个式子:
这是求出p关于式(2)的最小二乘解的过程,可由迭代的方法解决(如高斯牛顿法)。对于式(2)来说,p和W(.)的更新公式为(这些更新公式不难理解,就是对p和W(.)进行的一种简单叠加):
迭代求解不可避免地要对原公式进行求导。先对式(2)求在I(W(x; p + △p)) 处的一阶泰勒展开:
式中的▽I(W)是I图像中W(x;p)像素坐标点处的像素梯度,它与当前像素坐标有关,也就是和p有关。同时W关于p的雅可比矩阵也与p的当前值有关。所以上述方法需要在每次迭代优化后求一次新的导数。之后就是通过构建Hessian矩阵来求出△p增量,完成迭代求解操作。大致步骤如下图:

从图中可以看到,由于每次迭代都要重新计算相关雅可比矩阵以及像素梯度值,所以该方法的计算量很大。而逆向光流法就是针对这个不足而优化后的算法,它在计算量方面远小于上述方法。
逆向光流法
逆向光流法也是基于灰度不变性假设实现,但它求解的迭代优化问题不同。它求解的目标是下面这个式子:
与式子(2)相比,式(6)中图象T和I换了个位置。△p的作用对象从图像I变成了图像T(这应该是算法被称为逆向光流的原因吧)。此时,W(.)的更新公式变成了:
下面谈谈我对公式(7)的理解。首先在两张图T、I中标记出正在进行匹配两个点对,将它们分别记为Pt和Pi。由于两幅图像目前估计的仿射变换为W(x;p),所以我们可以用下图来表示当前的情况(图比较飘,望见谅):
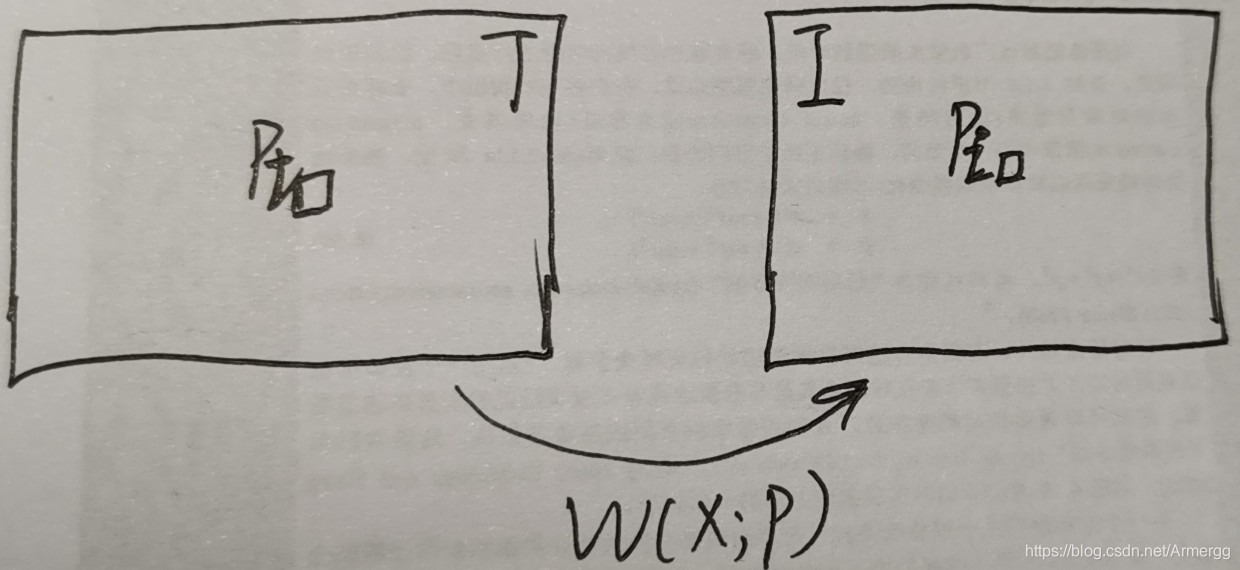
这时我们在图像T中进行一次微调,也就是对Pt执行W(x;△p)操作,将变换后的点记为Pt’。此时情况如下图所示:

我们假设经过这次△p的更新之后, Pt’ 与Pi之间的灰度误差最小,可认为 Pt’ 就是Pi对应的匹配点。得,弄了半天找了个 Pt’ 的匹配点。不过没有关系,至少我们知道Pi不会是Pt的匹配点。因此要在图像I中继续搜索,即移动Pi的位置,获得新的点Pi’。怎么移呢?我们这样想,既然 Pt’ 是通过△p变换获得的,那么对Pi使用与△p方向相反的变换(从这儿可以看出逆向光流法的限制是需要W(.;△p)是可逆的!)就有可能获得与Pt匹配的点。这一步由式(9)来实现,情况如下图所示:

那么这样的方法有什么好处呢?我们先对式(8)进行一阶泰勒展开,从展开式中就能够看出这个方法的优势:
式中的▽T代表的是W(x;0)点处的像素梯度,它是一个固定的量。W关于p的雅可比矩阵是在(x;0)处求得的(这就说明p对雅可比的计算是没有影响的),也是个固定量。之后就是通过构建Hessian矩阵来求出△p增量,完成迭代求解操作。大致步骤如下图:

从图中可以看出,由于有些量在整个迭代过程中是固定的,所以能够在算法的一开始就计算出来它们的值,且在迭代过程中可以一直使用,不需要更新。这固定的量就是降低整个算法计算量的关键所在。
结尾
以上就是本篇博客的全部内容。上述内容介绍了普通的光流法和逆向光流法,并说明了逆向光流法的优势。希望这些内容能帮助到每一位正在学习这个方面的朋友,大家一起进步(大家好才是真的好)!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









