






系列文章目录
【Dataset Shift】
文章目录
【阅读笔记】【AI测试】【Dataset Shift】Reliable and Trustworthy Machine Learning for Health Using Dataset Shift Detection
阅读笔记,非全文翻译
Abstract
- 医用领域对没见过的数据(unseen data)的预测比较看重
- 作者探索了 使用最新的OOD detectors在可靠和可信的诊断预测上的可行性
- 我们选择与各种健康状况(如皮肤癌、肺音和帕金森病)相关的公开可用深度学习模型,使用各种输入数据类型(如图像、音频和运动数据)。我们证明,这些模型在非分布数据集上显示出不合理的预测。
- 我们表明,基于马氏距离和克氏矩阵的分布外检测方法能够对运行在不同模式下的健康模型进行高精度的分布外检测数据。然后,我们将分布外得分转化为人类可解释的信心评分,以调查其对用户与健康ML应用程序交互的影响。
- 我们的用户研究表明,CONFIDENCE SCORE帮助参与者只相信得分高的结果来做出医疗决策,而忽视得分低的结果。通过这项工作,我们证明了数据集转移对于高风险的ML应用程序(如医疗诊断和医疗保健)来说是一个至关重要的信息,可以为用户提供可靠和可信的预测。
问题:
【1】什么是user-perceived trustworthiness of the health models
1 Introduction
- 人们希望医疗AI能够帮助做出无偏决策(unbiased decision)
- 现在的健康模型严重依赖于用于训练的数据集,但数据集很难覆盖一个领域,比如covid-19的出现,现有肺炎模型无法判断出新疾病的出现。对于医疗诊断和疾病筛查这种对错误很敏感的任务,这很重要。
- 基于输入,研究人员可以估计ML模型的不确定性。
- Out-of-distribution detection(下文简称OODD)方法可以判断:一个输入样本是否服从训练数据集的分布。但医疗领域中OOD研究比较少
- 病人上传的医疗数据可能比较糟糕,比如拍的照片光照不好,不如专家收集的训练数据集
- 把ood分数转换为可信度分数confidence,并显示给病人看,病人更易接受这种方法
- 三个贡献:①找到并量化当前健康深度学习模型面对未见过的数据时的局限性;②评估了在医疗筛查诊断方面,OODD在不同数据类型(图片视频声音)上的utility;③评估了数据集转移信息对用户感知的健康诊断结果可信度的影响。
2 Related Work
基于ML的健康筛查和诊断
Mobile ML模型帮助护士、健康工作者和大众更快地筛查病情。
本文致力于探索一个方法,使用dataset shift information来帮助健康ML模型对用户来说更可靠。
Dataset Shift Detection
OODD的baseline:Softmax confidence
文章选用了Mahalanobis distance,Gram matrices,energy-based oodd 方法,因为这几个方法不用重训练或不需要知道OOD的先验知识,并且在pretrained分类器上可以工作
Trustworthy AI
现实生活中,构建可信AI是非常重要的问题,不然可能导致严重后果。
3 Background:Dataset Shift Detection Methods
3.1 Mahalanobis Distance-Based Out-of-Distribution Detection
- 假设:卷积神经网络的每层特征是符合多元高斯分布的
- 对每一层网络,提前计算每个类别的数据的均值,和协方差矩阵
- 根据均值和协方差矩阵,计算input样本到ID各个类别的置信度得分(马氏距离的相反数)
- 最大化置信度得分,就是最小化马氏距离。使用马氏距离的相反数作为样本来自ID的置信度
【问题】什么是proximity of a point
作者用FGSM生成的对抗样本来代替OOD了
3.2 Gram Matrices-Based OODD
- 提前从ID中计算好每个层、每个类别的Gram矩阵,对每个类别记录最大最小的特征值。
- 对于一个输入样本input,每一层都计算一个Gram矩阵,根据input被判定的类,选择相应的ID Gram矩阵进行比较;比较最大和最小特征值,计算偏差。
- 然后利用所有层的偏差的normalized sum作为总偏差。
3.3 Energy-Based OODD
基于能量的OOD检测
【问题】有待进一步理解
4 Performance Evaluation
- 本章节显示了健康模型在遇到ood数据时的退化;
- 评估了SOTA OODD的性能表现
- 两个评估:①协方差偏移、标签偏移,评估同样分类任务,但是数据集合环境不同的情况;②open-set recognition,评估遇到训练集没有的新类别的情况。
4.1 Models and Datasets
皮肤病变
本文用了一个DenseNet-121皮肤病变分类器,分类结果有7个:actinic keratoses, basal cell carcinoma, benign
keratosis, dermatofibroma, melanoma, melanocytic nevi and vascular lesions。
- [ID] HAM10000,10000份皮肤肿瘤样本
- [OOD] ISIC,HAM10000的前置版本,二分类
- [OOD] Face,102个人的正面图象
- [OOD] CIFAR10,不赘述
肺部声音
基于Resnet-34,对肺部音频输出4个分类结果:normal, wheezing, crackle, and wheezing + crackle。
- ID:ICBHI 2017 Respiratory Challenge
- OOD:Stethoscope
- OOD:AudioSet:Youtube上的音频集,选用了其中一部分关于咳嗽、呼吸、喘息的音频
帕金森氏病
性能最高的二分类模型,5个一维卷积层和单个输出层。利用加速度计信号检测人体运动,判断是否患有帕金森氏病。
- ID,mPower:包含3100名健康和帕金森患者休息时的30秒加速度计读数
- OOD,Kaggle Parkinson‘s Disease:健康人模仿患者的加速度计读数
- OOD,Motion Sense:24个参与者的各种运动,走路慢跑等
- OOD,MHEALTH:与Motion Sense类似
4.2 Performance Impact by Dataset Shift
- For the datasets that do not have the same labels from the in-distribution, the accuracy could not be computed. 对于没有对应标签的数据集,准确率无法计算。
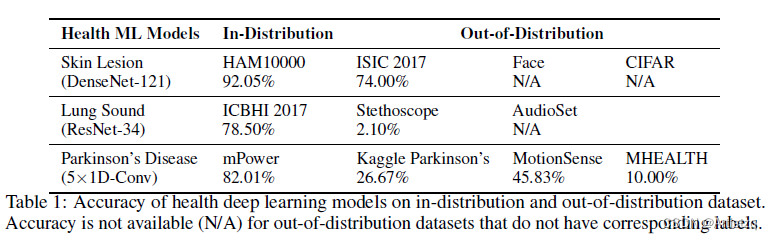
- observed a significant performance drop for all health machine learning models that are tested with out-of-distribution datasets。观察到所有的模型在OOD上测试时都有明显退化。
- 把人脸识别成血管疾病;CIFAR10识别成皮肤病;把运动识别成帕金森;把笑声识别成肺音,这些都是实际中可能遇到的,比如有人把自拍上传了。
- 这表明用户接触到了那种提供令人无法信任诊疗结果的健康ML模型
4.3 OOD Detection Performance
用上述三个检测方法检测了:①pretrain;②不需要retrain;不需要OOD先验知识。符合三种情况的模型
4.3.1 Experimental Setup
- 马氏距离:提取了DenseNet和ResNet中输出层和残差块;对帕金森病模型,因为没有Dense和Residual,所以抽取了每个conv层的结果。然后用FGSM和ID生成对抗样本,噪声的magnitude:皮肤病分类器0.0,肺音5e-4,帕金森0.0
- Gram矩阵:【问题】
- Energy-Based:【问题】
所有方法进行5次实验,取平均。
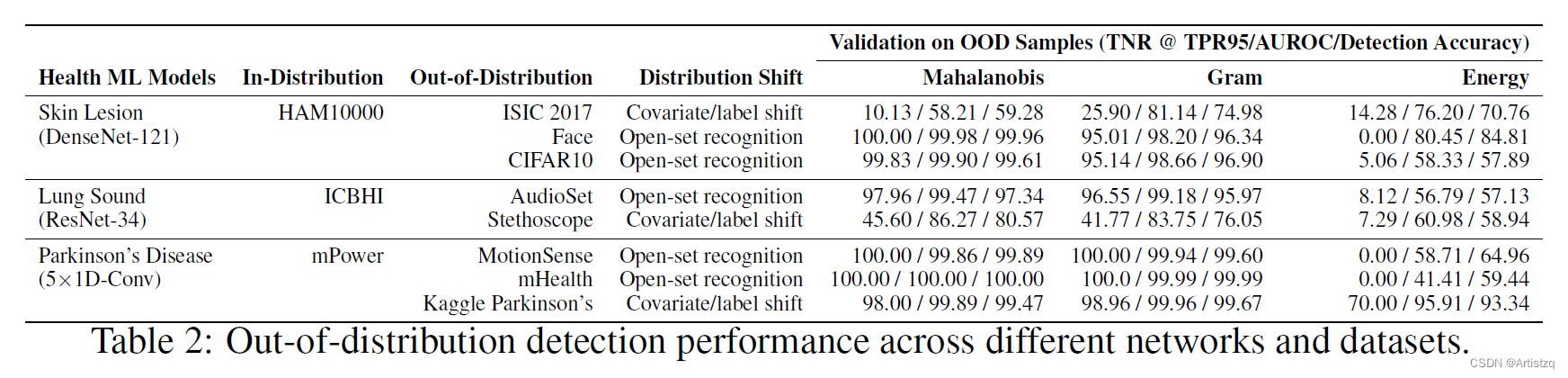
4.3.2 Evaluation Metrics
常见的二分类指标,TPR,TNR,AUROC等。设定:ID为正,OOD为负;【问题】TPR95%的TNR为正确检测的百分比。AUROC不赘述。
4.4.4 Results
- 马氏距离和Gram矩阵效果outstanding
- Energy-Based方法极差【问题】:后续还要看这个方法;这个方法在finetuned的分类器上效果好,作者没用finetuned分类器
5 User Study
用Confidence Score来量化可信程度。
【问题】具体怎么量化的?
作者根据以下RQ,做了用户调查
- RQ1:Confidence Score如何影响到医疗诊断结果的可信度?
- RQ2:Confidence Score如何影响到基于诊断结果的医疗决策?
- RQ3:当区分输入样本的Confidence Score的高和低时,会有潜在的学习效果吗?
5.1 Study Procedure and Participants

6 Discussion
Limitations and Future Work
- 参与调查的人的决策不会有真的影响,他们就不会像真实生活中那样深思熟虑
- 还有其他因素,身体状况的严重程度,采取行动的perceived收益【问题】这个perceived到底是什么?
- 参与者知道这个皮肤不是他自己的
- 作者在调差问卷上对实验的解释也可能对参与者的决策有影响
- 尽管信任随着样本的confidence score在发生相应变化,但使用随机的confidence score的样本应能更好量化结果。
- 以后工作
- 研究为用户呈现这些信息的最佳方式
- 利用数据集的偏移信息来发现训练数据集中的潜在偏差和模型的固有问题
- 研究OOD方法在近分布检测中的性能。
【问题】究竟什么是 make medical decision















 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









